Ⅰ、索引的另一个作用
B+ tree 是排序过的,对排序过的列进行查询也会非常快
(root@localhost) [dbt3]> explain select * from orders order by o_totalprice desc limit 10;
+----+-------------+--------+------------+------+---------------+------+---------+------+---------+----------+----------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+---------------+------+---------+------+---------+----------+----------------+
| 1 | SIMPLE | orders | NULL | ALL | NULL | NULL | NULL | NULL | 1489118 | 100.00 | Using filesort |
+----+-------------+--------+------------+------+---------------+------+---------+------+---------+----------+----------------+
1 row in set, 1 warning (0.00 sec)
看到没走索引,依赖sort_buffer_size来排序
加一个索引
(root@localhost) [dbt3]> alter table orders add index idx_o_totalprice(o_totalprice);
Query OK, 0 rows affected (6.81 sec)
Records: 0 Duplicates: 0 Warnings: 0
(root@localhost) [dbt3]> explain select * from orders order by o_totalprice desc limit 10;
+----+-------------+--------+------------+-------+---------------+------------------+---------+------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+-------+---------------+------------------+---------+------+------+----------+-------+
| 1 | SIMPLE | orders | NULL | index | NULL | idx_o_totalprice | 9 | NULL | 10 | 100.00 | NULL |
+----+-------------+--------+------------+-------+---------------+------------------+---------+------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
会发现走了创建的索引,extra也是null了,根本就不用排序了,用不到排序内存了,也就是说不用调大sort_buffer_size了
综上:索引的第二个作用,加速order by,从排序的数据中取数据,第一个作用,快速定位
Ⅱ、什么时候创建索引
- cardinality:简单说就是count(distinct column)
- the count of unique record:唯一记录的数量(不重复数据数量)
- high selectivity:高选择性,性别这种就是低选择性,姓名就是高选择性
- using B+ tree to access less record:从大量数据中找出一小部分数据
如何看索引是否选择度高?
看information_schema库中statistics表里cardinality字段
(root@localhost) [information_schema]> select cardinality from statistics where table_schema='dbt3' and table_name = 'customer' limit 1;
+-------------+
| cardinality |
+-------------+
| 147674 |
+-------------+
1 row in set (0.00 sec)
(root@localhost) [information_schema]> select table_rows from tables where table_schema='dbt3' and table_name = 'customer' limit 1;
+------------+
| table_rows |
+------------+
| 147674 |
+------------+
1 row in set (0.00 sec)
发现记录数和cardinality数目是一致的 这是为什么呢,因为主键是唯一的 ,其他索引的cardinality就没这么高了
综上:高选择性即cardinality/table_rows越接近于1越好
一下子抓出所有低效索引
SELECT
t.TABLE_SCHEMA,
t.TABLE_NAME,
INDEX_NAME,
CARDINALITY,
TABLE_ROWS,
CARDINALITY / TABLE_ROWS AS SELECTIVITY
FROM
information_schema.tables t,
(SELECT
table_schema, table_name, index_name, cardinality
FROM
information_schema.STATISTICS
WHERE
(table_schema , table_name, index_name, seq_in_index) IN (SELECT
table_schema, table_name, index_name, MAX(seq_in_index)
FROM
information_schema.STATISTICS
GROUP BY table_schema , table_name , index_name)) s
WHERE
t.table_schema = s.table_schema
AND t.table_name = s.table_name
AND t.table_rows != 0
AND t.table_schema NOT IN ('mysql' , 'performance_schema',
'information_schema',
'sys')
HAVING SELECTIVITY < 0.1
ORDER BY SELECTIVITY DESC;
tips::
①categories要不要创建索引呢?
只根据类别查询的场景不多,什么分类下的产品什么的都会被放到cache中,很多时候是和另一个字段一起做一个复合索引
②cardinality 和 table_rows 是通过采样的方式预估的,不是精确的
③慢查询日志和计算每一行的大小也是用采样
Ⅲ、复合索引
通常来说,复合索引是二级索引
原理:和之前的一样,叶子节点存放键值和主键值,非叶节点存放的是key和pointer,这里key是多个索引组成的一个key
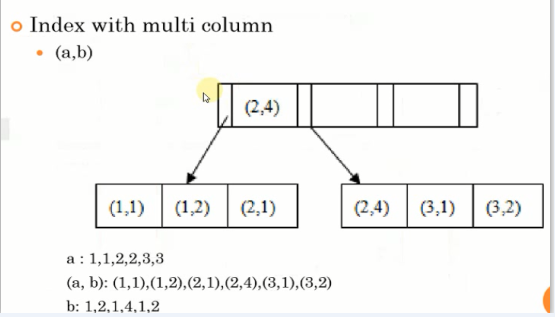
a和a,b都已经排序,b不一定排序
使用场景:
select * from t where a = ?
select * from t where a = ? and b = ?
对a a,b已经排序,所以上面两个能用
select * from t where b = ?
这个是不能用到前面的复合索引,对b没排序
用的最多的是下面这个,很重要
select * from t where a = ? order by b 完美的索引表示,找到a后,b已经排确定好顺序了,
很多人只对a列创建索引,这样会用到filesort,而且还不会被记录到slow.log,因为已经走了索引了,可能运行还蛮快的,因为你取出的数据比较少,再排序,limit
但是如果你这样做了,排序会对cpu消耗很大,单条sql执行不难,但是互联网某条sql很热门,一千个用户都来执行,那就完蛋了
如何查看排序最多的sql?
看sys库中statements_with_sorting表的exec_count列
一个问题:
a b c 三个列的组合索引
a = ? and b = ? order by c
a = ? b = ? c = ?
这时候该怎么创建复合索引
原则:选择度高的放到前面,根据cardinality从高到低做索引
tips:
a b c d 四个列 d 是主键
a b 创建的复合索引,则其叶子节点中就会保存a b d ,a b d 是排序的 (key ,pk)
Ⅳ、索引覆盖
index coverage——只要是不回表取得数据就叫索引覆盖
通常来说覆盖索引是一个复合索引,当然单个列也可以覆盖
索引覆盖的标签就是执行计划的extra中显示using index
explain select a from t where c between '2018-06-12 00:00:00' and '2018-06-12 23:59:59';
+----+-------------+----------------+------------+-------+---------------+---------------+---------+------+-------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------------+------------+-------+---------------+---------------+---------+------+-------+----------+-----------------------+
| 1 | SIMPLE | t | NULL | range | idx_c | idx_c | 5 | NULL | 33560 | 100.00 | Using index condition |
+----+-------------+----------------+------------+-------+---------------+---------------+---------+------+-------+----------+-----------------------+
1 row in set, 1 warning (0.00 sec)
这样走idx_c索引,idx_c索引覆盖不到要查的a,所以需要根据idx_c查到pk,再根据pk回表去查a
加一个索引
(root@localhost) [j8]> alter table t add index idx_c_a(c,a);
Query OK, 0 rows affected (14.54 sec)
Records: 0 Duplicates: 0 Warnings: 0
(root@localhost) [j8]> explain select a from t where c between '2018-06-12 00:00:00' and '2018-06-12 23:59:59';
+----+-------------+----------------+------------+-------+----------------------------------+--------------------+---------+------+-------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------------+------------+-------+----------------------------------+--------------------+---------+------+-------+----------+--------------------------+
| 1 | SIMPLE | t | NULL | range | idx_c,idx_c_a | idx_c_a | 5 | NULL | 34650 | 100.00 | Using where; Using index |
+----+-------------+----------------+------------+-------+----------------------------------+--------------------+---------+------+-------+----------+--------------------------+
1 row in set, 1 warning (0.00 sec)
新索引包含了c_ip,所以就using index不用回表了,两个sql消耗的对比可以用explain format=json看cost,这个例子直接看执行计划确实不明显,不过对比cost第二个情况消耗要小很多,json就先不贴了,洲际哥绝逼不骗人的,很正儿八经
如果有了(a,b)复合索引,b再单独创建一个索引是常用的,那a列需要单独创建一个索引吗?a=?是比a b =? 快一些,但从B+ tree高度上来说是差不多的,除非b列特别大,就算1k也没什么太大感觉,多创建索引,对dml操作维护起来消耗更大
(a,b) (a) 同时存在,(a)叫冗余索引 redundant index
如何查看冗余索引?
sys库中schema_redundant_indexes表,里面有提示,甚至有建议删除的语句在里面
到目前为止讲的都是oltp的,互联网,在线事务处理,操作很快,用户并发很大
olap在线分析,实时性能要求不高,数据仓库,大数据,这时候创建冗余索引关系不大,更新操作比较少,查询比较多,mysql不适用于这种