4. 激活函数
-
激活函数是用来加入非线性因素的,因为线性模型的表达能力不够。引入非线性激活函数,可使深 层神经网络的表达能力更加强大。
-
优秀的激活函数:
- 非线性:激活函数非线性时,多层神经网络可逼近所有函数
- 可微性:优化器大多用梯度下降算法更新参数
- 单调性:当激活函数是单调的,能保证单层神经网络的损失函数是凸函数
- 近似恒等性: 当参数初始化为随机小值时,神经网络更稳定
-
激活函数输出值的范围:
-
激活函数输出为有限值时,基于梯度的优化方法更稳定
-
激活函数输出为无限值时,建议调小学习率
-
-
常见的激活函数:
- sigmoid :
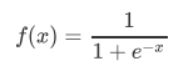
- 函数图像:
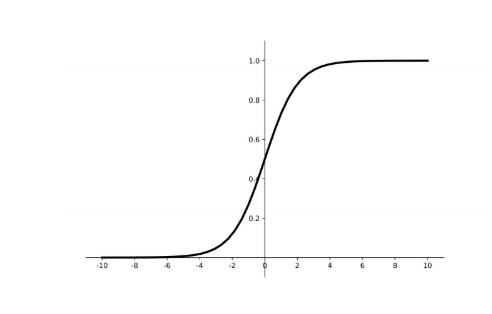
优点:
- 输出映射在(0,1)之间,单调连续,输出范围有限,优化稳定,可用作输出层;
- 求导容易。
缺点:
- 易造成梯度消失;
- 输出非0均值,收敛慢;
- 幂运算复杂,训练时间长。
- tanh :

- 函数图像:
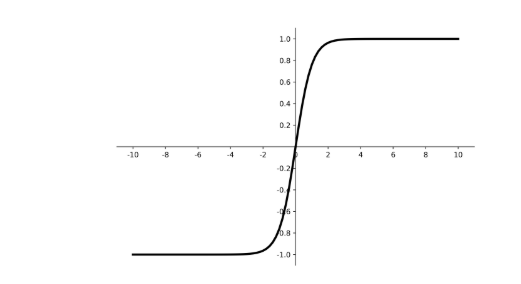
优点:
- 比sigmoid函数收敛速度更快。
- 相比sigmoid函数,其输出以0为中心。
缺点:
- 易造成梯度消失;
- 幂运算复杂,训练时间长。
- ReLU:
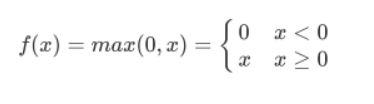
- 函数图像

优点:
- 解决了梯度消失问题(在正区间);
- 只需判断输入是否大于0,计算速度快;
- 收敛速度远快于sigmoid和tanh,因为sigmoid和tanh涉及很多expensive的操作; 提供了神经网络的稀疏表达能力。
缺点:
- 输出非0均值,收敛慢;
- Dead ReLU问题:某些神经元可能永远不会被激活,导致相应的参数永远不能被更新。
- Leaky ReLU:
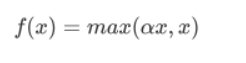
- 函数图像:
优点:
理论上来讲,Leaky ReLU有ReLU的所有优点,外加不会有Dead ReLU问题,但是在实际操作当 中,并没有完全证明Leaky ReLU总是好于ReLU
- softmx:
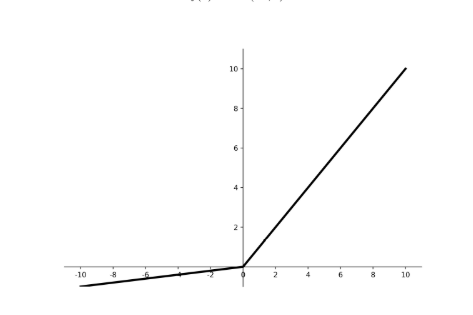
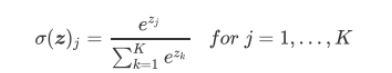
- 对神经网络全连接层输出进行变换,使其服从概率分布,即每个值都位于[0,1]区间且和为1。
5.损失函数
-
损失函数是前向传播计算出的结果y 与已知标准答案y_的差距
-
神经网络的优化目标:找到合适的一套参数,使得损失函数最小
-
损失函数的三种计算方法:
- 均方误差:

- 在tensorflow中的实现:tf.reduce_mean(tf.square(y_-y))
-
自定义: 根据具体任务和目的,可设计不同的损失函数。
-
交叉熵:表示两个概率分布之间的距离,交叉熵越大,两个概率分布越远,交叉熵越小,两个概率分布越近

- 在tensorflow中的实现:tf.losses.categorical_crossentropy(y_-y)
6.欠拟合与过拟合
-
欠拟合:模型不能有效拟合数据集,是对现有数据集学习的不够彻底
-
过拟合:模型对当前数据拟合的太好了,但对从未见过的新数据却难以做出正确的判断,模型缺乏泛化力

- 欠拟合的解决方法:
- 增加输入特征项
- 增加网络参数
- 减少正则化参数
- 过拟合的解决方法:
- 数据清洗
- 增大训练集
- 采用正则化
- 增大正则化参数
正则化缓解过拟合:
正则化就是在损失函数中引入模型复杂度指标,给每个参数w加权值,抑制训练数据的噪声(一般不正则化b)

-
正则化的选择:
- L1正则化大概率会使很多参数变为零,因此该方法可通过稀疏参数 ,即减少参数的数量,降低复杂度。
- L2正则化会使参数很接近零但不为零,因此该方法可通过减小参数 值的大小降低复杂度。