该笔记介绍的是《卷积神经网络》系列第三周:目标检测 (2)YOLO算法
主要内容有:
1.YOLO算法思想
2.交并比
3.非最大抑制
4.Anchor Box
5.YOLO算法例子
YOLO算法思想
基本的滑动窗口对象检测算法并不能精准描绘边框,所以我们要学习一个能够得到准确边框的算法YOLO(You Only Look Ones)算法。
算法思想:在图片上放置n*n的网格,并将图像分类和定位算法运用到每个网格上面去。
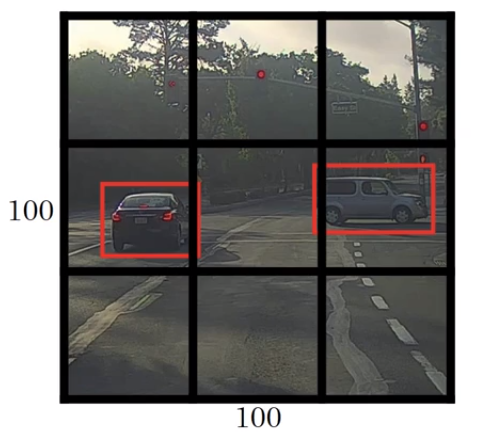
与滑动窗口对象检测算法的区别:
a.窗口滑动由放置网格取代,YOLO算法会对每个网格使用图像分类和图像定位算法,相比滑动窗口会大大的减少了运算量。
b.一个对象可能在多个网格中,YOLO算法会找到该对象的中心点,并把对象分给包含中心的网格。(bh,bw是可以大于网格大小,实践中会使用更精细的去分割网格,所以对象会横跨多个网格)
c.显示的输出边界框架,让神经网络输出的框架可以具有任意的宽高比,并且能输出更精确的坐标。

*由于YOLO算法的特性使得,每个格子的对象不能超过一个,但是实践过程中网格会分的很精细所以基本上不用担心这个问题。
YOLO算法的输出
由于YOLO算法是对每个网格进行运行,在视频给出的例子中输出结果3*3*8
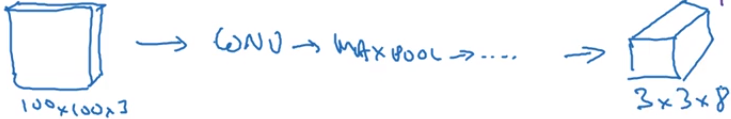
3*3是图片的分割的网格数量
8是输出图片预测和边框位置等信息,其实就等于给出的标签y的具体信息:
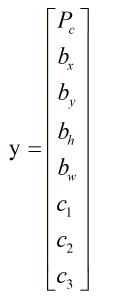
交并比(IOU)
计算两个边框交集和并集之比,IOU是用来衡量两个边框的重叠的大小。

交集/并集=
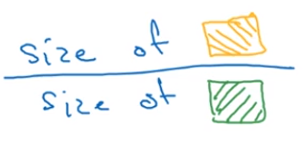
一般认为IOU>=α(阀值,一般人为约定为0.5)是可接受的,由不同场景可自己设置。
非最大抑制
抑制不是极大值的元素,搜索局部的极大值,确保每个对象只检测一次。
YOLO算法在运行中存在一个问题,理论上图片上每一个对象只存在一个中心点,实践中可能会有几个网格都会认为对象的中心在自己网格中。

于是就会生成多个边框
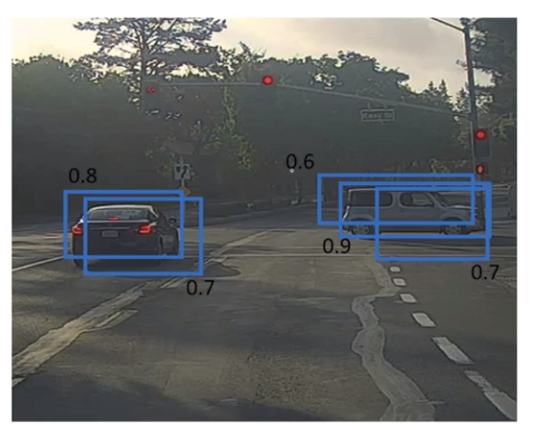
非最大抑制的作用就是,对于每个对象只保留其Pc预测最大的值
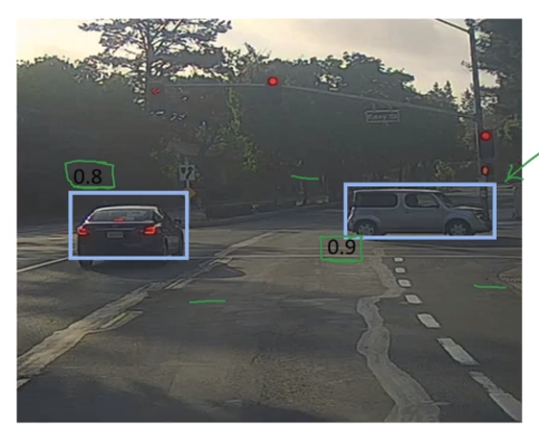
非最大抑制用法
a.去掉IOU没到达到阀值的边框
while(存在剩下的边框):
b.选择概率Pc的边框,输出为预测结果
c.剩下边框中所以和输出边框有很大的交并,则它们的输出被抑制。
*如果存在多种类型的对象(即是c1,c2,c3),每种类型的对象要单独运行最大抑制(不同类型对象的交并值会对结果产生影响)。
Anchor Box
使用Anchor Box可以让一个检测出多个对象(不同类别的)。

Anchor Box思路:
a.预先定义多个个不同形状的的Anchor Box,Anchor Box的形状是与预测结果关联起来的。

b.现在每个对象都和以前一样分配到同一个格子里面,但是现在还要分配到一个Anchor Box,分配的原则是比较并选择该格子内对象与定义的Anchor Box不同形状之间的IOU交并比最高的那个。
于是标签y(对于视频中的例子)就变成下图这样了,每一个Pc对应这一个Anchor Box形状。
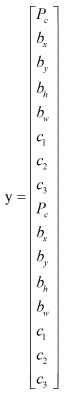
使用Anchor Box的好处:
a.处理两个不同类型的对象出现在同一格子里面,实际情况中如果格子够细致的话,一般不会出现两个格子在一个对象里面的。
b.能够让算法更有针对行(监督学习),如果你的数据给出的对象的形状大概相似。
如何选择Anchor Box:
一般手动根据对象制定Anchor Box形状,可以选择5个到10个形状,可以涵盖你想要检测对象的各种对象。
YOLO算法例子
上面讲的都是构建YOLO算法中所需要知道的一些知识,下面就通过一个例子把所有的知识点穿插起来。
视频使用的例子还是在图片中检测pedestrian(行人)、car(车)和motorcycle(摩托车)

输出数据形状是3x3x16:
a.3x3是分的格子形状
b.16(=2x8)其中2是使用的Anchor Box的个数,8就是输出的参数个数(Pc,bw,bx,bh,bw,c1,c2,c3)
输出标签y:
![]()
Anchor Box选择:
使用Anchor Box 1表示pedestrian(行人),Anchor Box 2表示car(车)和motorcycle(摩托车),这里是不知道为什么摩托车没Anchor形状,所以我认为可能摩托车形状与Anchor Box 2差不多。
使用卷积神经网络训练:

最后是使用非最大抑制:
没有使用非最大抑制时,由于使用了两个Another Box,每个格子都会有两个检测边界框,只是Pc概率不同而以。

你需要做的是:
a.抛弃概率比较低的预测边框

b.如果存在三个对象检测的类别(行人,车和摩托车),对每一类单独运行非最大抑制。这里的意思对于行人Anchor Box 1的形状的概率明显高于Anchor Box 2的概率。所以去掉Anchor Box 2形状的边框。