参考:https://www.iteye.com/blog/liwenshui322-1488949
https://blog.csdn.net/sh185/article/details/8494907
一. 什么是redo(用于重做数据)
redo也就是重做日志文件(redo log file),Oracle维护着两类重做日志文件:在线(online)重做日志文件和归档(archived)重做日志文件。这两类重做日志文件都用于恢复;其主要目的是,万一实例失败或介质失败,它们能够恢复数据。
由于数据库缓冲,对磁盘数据的更新不是实时的,但是对redo日志的更新会在commit之后确切发生。 如果在事务提交之后,磁盘数据更新之前,系统发生故障,比如断电,系统重启之后会将那些已经写入redo,但是没有更新到磁盘的数据进行重做,这样系统就恢复到故障点之前了。
redo日志默认3组,循环写入,第一组(每个组所有成员同时写入同样的信息)满了,切换到第二个,第二个满了切换到第三个,当所有组都写满之后,日志进程再次开始写第一个,后面的数据覆盖前面的数据,即为非归档模式。 鉴于redo如此重要,需要将已写满的日志归档,即复制redo内容到其他地方,即开启归档日志模式,但是会影响系统性能(生产环境建议开启归档,因为生产数据安全性第一)。
二. 什么是undo(用于回滚数据)
从概念上讲,undo正好与redo相对。你对数据执行修改时,数据库会生成undo信息,也就是说被修改的元数据存到undo中,这样万一你执行的事务或语句由于某种原因失败了,或者如果你用一条ROLLBACK语句请求回滚,就可以利用这些undo信息将数据放回到修改前的样子。redo用于在失败时重放事务(即恢复事务),undo则用于取消一条语句或一组语句的作用。
三. 对undo段的一个误解
通常对undo有一个误解,认为undo用于数据库物理地恢复到执行语句或事务之前的样子,但实际上并非如此。数据库只是逻辑地恢复到原来的样子,所有修改都被逻辑地取消,但是数据结构以及数据库块本身在回滚后可能大不相同。(比如一个插入操作,新分配了一些数据块。后来事务失败,插入操作全部回滚,新分配的一些数据块还是存在的)
原因在于:在所有多用户系统中,可能会有数十、数百甚至数千个并发事务。数据库的主要功能之一就是协调对数据的并发访问。也许我们的事务在修改一些块,而一般来讲往往会有许多其他的事务也在修改这些块。因此,不能简单地将一个块放回到我们的事务开始前的样子,这样会撤销其他人 (其他事务)的工作!
例如,假设我们的事务执行了一个INSERT语句,这条语句导致分配一个新区段(也就是说,导致表的空间增大)。通过执行这个INSET,我们将得到一个新的块,格式化这个块以便使用,并在其中放上一些数据。此时,可能出现另外某个事务,它也向这个块中插入数据。如果要回滚我们的事务,显然不能取消对这个块的格式化和空间分配。因此,Oracle回滚时,它实际上会做与先前逻辑上相反的工作。对于每个INSERT,Oracle会完成一个DELETE。对于每个DELETE,Oracle会执行一个INSERT。对于每个UPDATE,Oracle则会执行一个“反UPDATE“,或者执行另一个UPDATE将修改前的行放回去。
所以有一种异常情况就很容易解释了,一个表明明只有1000行左右的数据,一条select * from table 语句可能需要耗时1,2分钟。这张表应该是经常进行新增删除操作的表,比如我新增了1000万行数据,然后又将这些数据删除。对这个表进行全表扫描的时候,仍然会去扫描这1000万行以前所占用的那些数据块,看看里面是否包含数据。也就是oracle里面所说的高水平线(HWM),这些数据块都增加到了高水平线下面,oracle会扫描所有高水平线下的数据块。
四. redo与undo如何协作保证数据完整与安全性
以一个例子来说明一下(一个事务包含一组sql语句):
insert
into t(x,y) values(1,1);
update t set x = x+1 where x = 1;
delete from t where x = 2;
1.INSERT
对于第一条INSERT INTO 语句,redo和undo都会生成。所生成的undo信息足以使INSERT“消失“。INSERT INTOT生成的redo信息则足以让这个插入”再次发生“。
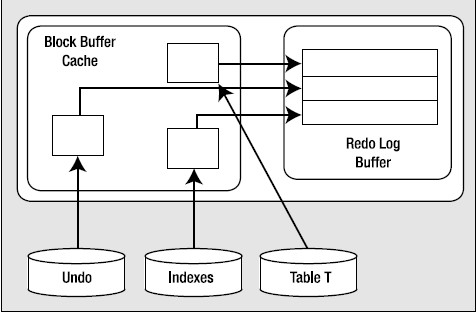
这里缓存了一些已修改的undo块、索引块和表数据块。这些块得到重做日志缓冲区中相应条目的“保护“。
假想场景一:系统现在崩溃
系统现在崩溃是没什么关系的。SGA会被清空,但是我们并不需要SGA里的任何内容。重启动时就好像这个事务从来没有发生过一样。没有将任何已修改的块刷新输出到磁盘,也没有任何redo刷新输出到磁盘。我们不需要这些undo或redo信息来实现实例失败恢复。
假想场景二:缓冲区缓存现在已满
在这种情况下,DBWR必须留出空间,要把已修改的块从缓存刷新输出。如果是这样,DBWR首先要求LGWR将保护这些数据库块的redo条目刷新输出。DBWR将任何有修改的块写至磁盘之前,LGWR必须先刷新输出与这些块相关的redo信息。这是有道理的——如果我们要刷新输出表T中已修改的块,但没有刷新输出与undo块关联的redo条目,倘若系统失败了,此时就会有一个已修改的表T块,而没有与之相关的redo信息。在写出这些块之前需要先刷新输出重做日志缓存区,这样就能重做(重做)所有必要的修改,将SGA放回到现在的状态,从而能发生回滚。(也就是任何一条修改记录持久化到数据文件的时候,必须先把它对应的redo条目持久化到磁盘文件,以保证这个过程的可逆性。你可能会问,redo不是前滚吗,可逆应该是回滚,怎么跟redo有关系呢?其实是redo段里面包含了undo段的信息)
2.UPDATE
UPDATE所带来的工作与INSERT大体一样。不过UPDATE生成的undo量更大;由于存在更新,所以需要保存一些“前“映像。系统状态如下图所示。

块缓冲区缓存中会有更多新的undo段块。为了撤销这个更新,如果必要,已修改的数据库表和索引块也会放在缓存中。我们还生成了更多的重做日志缓存区条目。下面假设前面的插入语句生成了一些重做日志,其中有些重做日志已经刷新输出到磁盘上,有些还放在缓存中。
假想场景一:系统现在崩溃
启动时,oracle会去读取重做日志文件,会发现有一些redo文件对应的修改记录还没有持久化到数据文件。然后发现这些redo文件是一个事务里面的,于是得回滚这个事务。步骤如下:
a. 根据redo文件,进行数据前滚,会在内存中构造出undo块、已修改的表块,以及已修改的索引块。
b. 根据undo块进行数据回滚,回滚到插入前的数据状态。
3.DELETE
同样,DELETE会生成undo,块将被修改,并把redo发送到重做日志缓冲区。这与前面没有太大的不同。实际上,它与UPDATE如此类似,所以我们不再啰嗦,直接来介绍COMMIT。
4.COMMIT
在此,Oracle会把重做日志缓冲区刷新输出到磁盘。
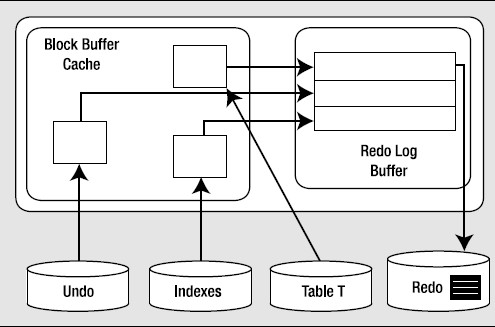
假设目前已修改的块放在缓冲区缓存中;有一些块已经刷新输出到磁盘上,有一些还没有。但是如果重做这个事务所需的全部redo都安全地存放在磁盘上,那么修改就是永久的了,即使有一些修改的块还没有刷新输出到磁盘上。(commit并不是把所有的修改持久化到了数据文件,而是所有的redo文件持久化到磁盘文件,只要所有的重做日志文件持久化到磁盘,这些修改就是永久的了。)如果从数据文件直接读取数据,可能会看到块还是事务发生前的样子,因为很有可能DBWR还没有(从缓冲区缓存)写出这些块。这没有关系,如果出现失败,可以利用重做日志文件来得到最新的块。