yarn 由,资源管理器rm,应用管理器am appMaster,节点管理器nm 组成!
图侵删

yarn 的设计,是为了代替hadoop 1.x的jobtracker 集中式一对多的资源管理「资源管理,任务监控,任务调度」,而yarn是 分而治之 ,使全局资源管理器减轻压力。
rm 监控每一个applicationmaster就可以了,而每一个applicationmaster则监控 自己node节点的所有任务「跟踪作业状态,进度,故障处理」,所以下降了压力。
rm资源管理器由调度器和应用管理者appmanager 功能模块组成。以调度策略分容量调度器和公平调度器。前者是集群吞吐量利用率最大化,后者基于内存公平的调度。
而应用管理者负责接收提交作业,申请,负责作业容器失败时的重启。
hdfs
1 fsimgae,editlog 都是序列化文件,启动时会加载到内存
记录目录结构和crud等操作
2块的概念,让其支持大规模存储,数据备份和管理。
map reduce VS rdd 技术
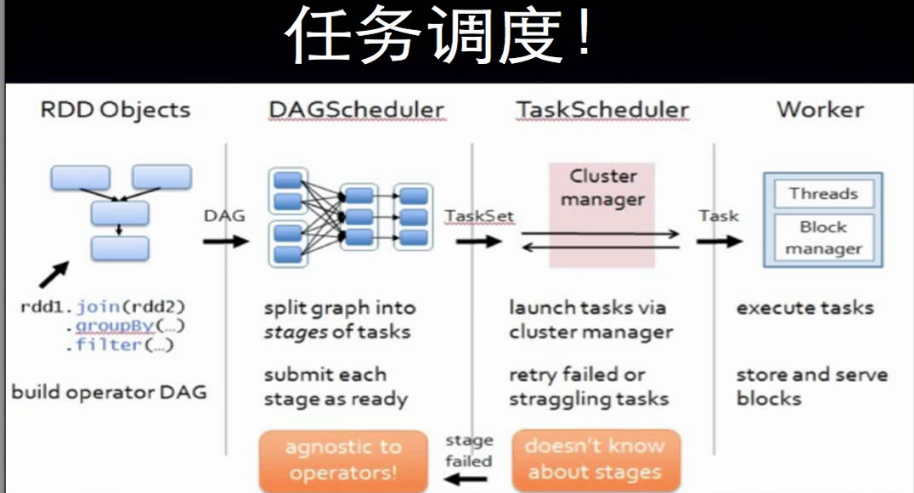
1 创建rdd对象;
2 sparkContext负责计算rdd之间的依赖关系,构建DAG;
3 DAGScheduler负责把DAG图分解成多个阶段,每个阶段包含多个任务,每个任务会被taskScheduler分发给各个工作节点worknode上的executor去执行。
「在DAG中进行反向解析,遇到宽依赖就断开,遇到窄依赖就把当前的rdd加入到当前的阶段中」
rdd的窄依赖与宽依赖, 以 父rdd只被一个子rdd依赖 一对一,多对一,区分是窄依赖,否则是宽依赖!
因为这是内存块,如果是窄依赖,则可以完全打包 分成一个线程并发执行! 而如果被其它多个子rdd依赖,即宽依赖,就可能rdd数据会变化,
等等,需要等待之前的阶段完成,才能继续执行!
这就是DAG的设计,比mapreduce快的原因。mapreduce,的reduce业务需要等map 执行完才能开始,而没有并发!这是依赖的!
还有一个原因是,一个是内存,一个是磁盘io。
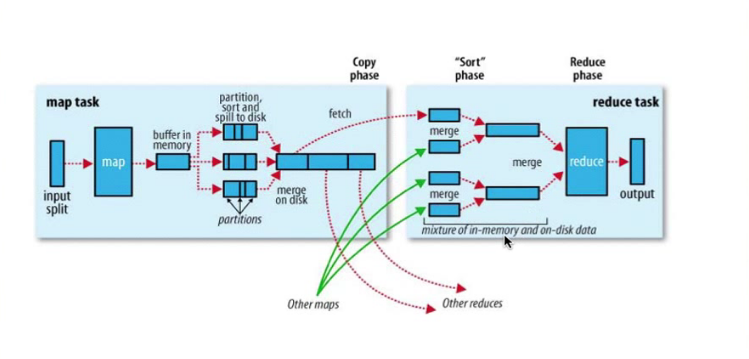
核心思想:分而治之! 把大的数据集分片而小多个 小数据集,对应多个map 并行处理。
结束后,以key value 中间结果,让reduce'减少' 整合,即具有相同的key 的结果分到同一个reduce任务!
整个过程,map输入文件,reduce任务处理结果都是保存到分布式文件系统中,而中间结果则保存到本地存储中,如磁盘。
只有当map处理全部结束后,reduce过程才能开始!
shuffle过程:map的结果,进行,分区,排序,合并等处理并交给reduce的过程,即上图。
map的shuffle:每个map把结果首先写入缓存,当满了就溢写到磁盘,并清空缓存。 为了让不同的reduce方便拿数据,会分好区,map结果会排序合并等操作处理。
reduce的shuffe: 从多个map中领回属于自己处理那部分数据,然后对数据合并merge后给reduce处理。
从学习hadoop和spark 过程,yarn代替jobstracker,spark代替mapreduce,明白,原来高手们写代码,做产品架构设计一开始的时候,也不是完善完美的,
需要先做出来,在实际环境去调优,修正,发现问题,然后解决问题,不断完善甚至改掉原来的架构或思想。