一、常规哈希算法
常规的哈希算法在进行扩容的时候,都要进行在哈希计算,重新哈希计算之后的结果通常会和原来的位置不一样,这在做负载均衡和缓存集群的时候,这种改变不是我们想要的(局限性)
因为服务器为了方便用户的访问,会在服务器上缓存数据,加速下一次的访问,因此用户每次访问的时候最好能保持同一台服务器。常规的哈希算法显然解决不了这个问题
比如你有 N 个 cache 服务器(后面简称 cache ),那么如何将一个对象 object 映射到 N 个 cache 上呢,你很可能会采用类似下面的通用方法计算 object 的 hash 值,然后均匀的映射到到 N 个 cache ;
hash(object)%N
一切都运行正常,再考虑如下的两种情况;
1 、一个 cache 服务器 m down 掉了(在实际应用中必须要考虑这种情况),这样所有映射到 cache m 的对象都会失效,怎么办,需要把 cache m 从 cache 中移除,这时候 cache 是 N-1 台,映射公式变成了 hash(object)%(N-1) ;
2 、由于访问加重,需要添加 cache ,这时候 cache 是 N+1 台,映射公式变成了 hash(object)%(N+1) ;
1 和 2 意味着什么?这意味着突然之间几乎所有的 cache 都失效了。对于服务器而言,这是一场灾难,洪水般的访问都会直接冲向后台服务器;
再来考虑第三个问题,由于硬件能力越来越强,你可能想让后面添加的节点多做点活,显然上面的 hash 算法也做不到。
我们的每一个缓存节点也遵循同样的Hash算法,比如利用缓存节点的IP做Hash,将节点映射到环形空间当中
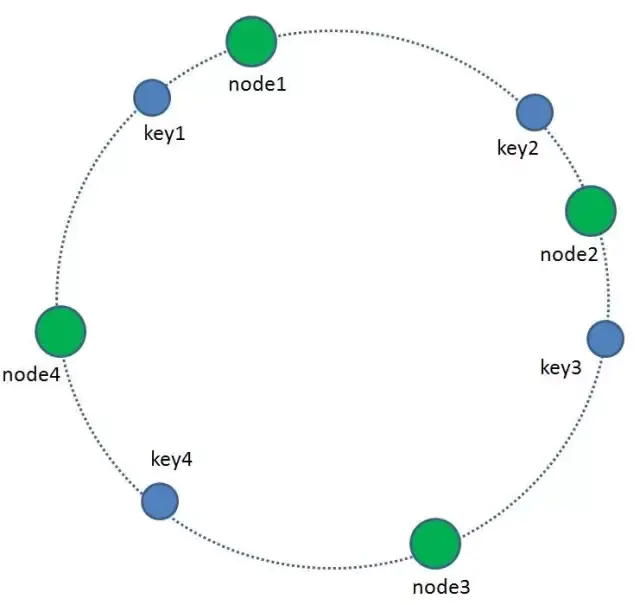
那么如何让key和节点对应起来呢?很简单,每一个key的顺时针方向最近节点,就是key所归属的存储节点。所以图中key1存储于node1,key2,key3存储于node2,key4存储于node3。
按这种分配缓存节点的规则,我们再来看看一个增删缓存节点的问题,假设2号节点宕机了,只有key2键会受到影响,key2对应的服务节点变为node3,其它key对应的服务节点不变,如下图
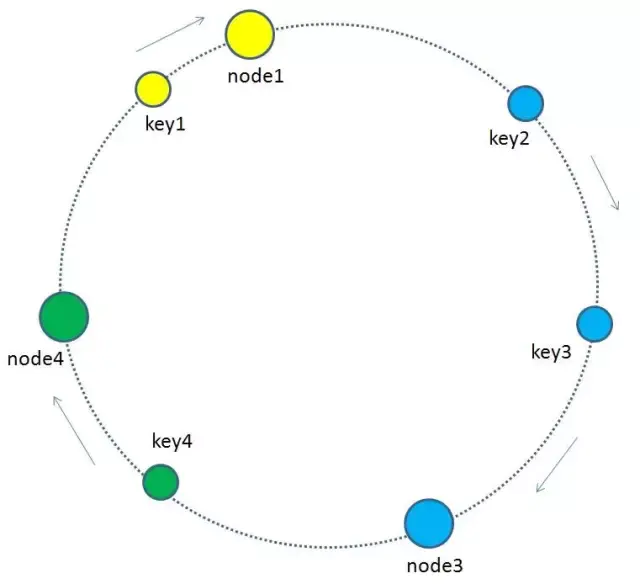
增加服务节点的时候,也只有少部分的key 会收到影响,对应的服务节点也就只有少部分需要迁移
如果出现分布不均匀的情况怎么办?比如下图这样,按顺时针规则,所有的key都归属于统一个节点。
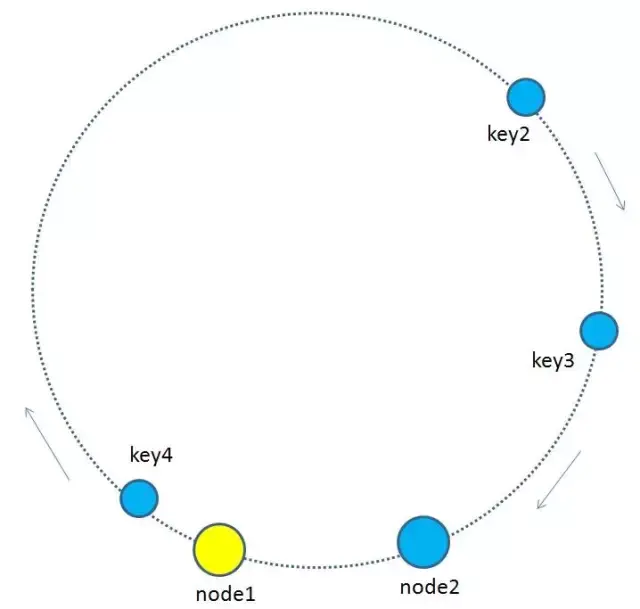
为了优化这种节点太少而产生的不均衡情况。一致性哈希算法引入了 虚拟节点 的概念。平衡性
所谓虚拟节点,就是基于原来的物理节点映射出 N 个子节点,最后把所有的子节点映射到环形空间上。
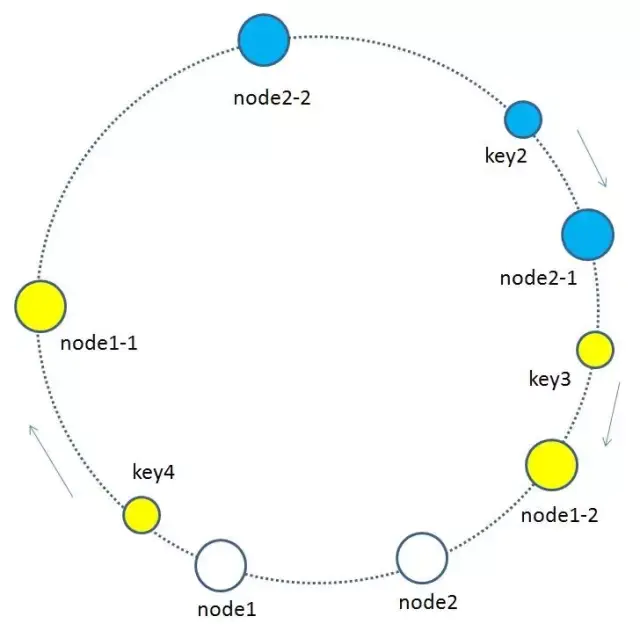
如上图所示,假如node1的ip是192.168.1.109,那么原node1节点在环形空间的位置就是hash(“192.168.1.109”)。
我们基于node1构建两个虚拟节点,node1-1 和 node1-2,虚拟节点在环形空间的位置可以利用(IP+后缀)计算,例如:
hash(“192.168.1.109#1”),hash(“192.168.1.109#2”)
此时,环形空间中不再有物理节点node1,node2,只有虚拟节点node1-1,node1-2,node2-1,node2-2。由于虚拟节点数量较多,缓存key与虚拟节点的映射关系也变得相对均衡了。