Fork/Join框架:将一个任务拆分(fork)成若干个子任务,再将一个个的子任务运算的结果进行汇总(join)。

以四核CPU为例,多线程下将任务分配到每个cpu线程核上,传统线程存在的问题是:每个任务可能会阻塞,一单某个线程发生了阻塞,那么这个核上线程的
其他线程将不能执行,与此同时,其他核上的线程执行完成后会达到空闲状态,这样阻塞的线程队列还在等待,这样一定程度上会造成资源浪费,没有很好的利用
CPU资源,被白白浪费掉,也会影响到效率问题。
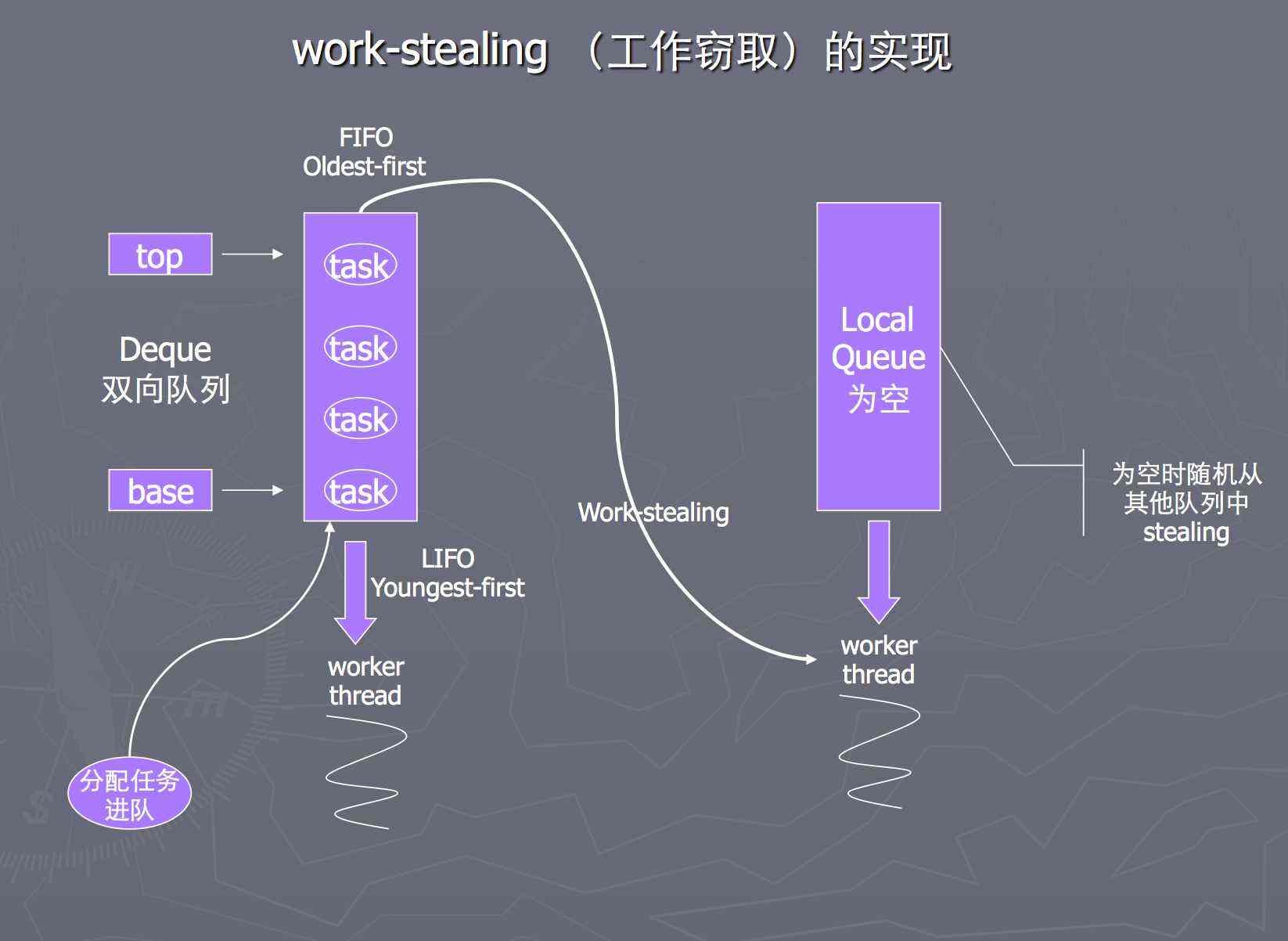
Fork/Join框架是将一个任务分成多个子任务,再将子任务压入到线程中,形成一个个线程队列,与传统线程池不一样的地方是,Fork/Join采用的是“工作
窃取”模式,简单理解为:当执行新的任务时它可以将其拆分成更小的任务执行,并将小任务加到线程队列中,然后再从一个随机线程的队列中偷一个并把它
放在自己的队列中。如果某个子问题由于阻塞而无法继续执行的时候,那么处理该子问题的线程会主动寻找其他尚未运行的子问题来执行,这种方式减少了
线程的等待时间,提高了性能。再说的直白一点就是,其他线程完事之后不会变成空闲状态,而是去别的线程队列上“偷”一个来“帮助”执行(因为线程队列
是双端队列,所以可以从尾部进行“偷取”),更好的利用了CPU资源。
Fork/Join在java1.7的时候就有了,为啥没有广泛的利用呢?写个Demo就知道了!
package com.lql.java8; import java.util.concurrent.RecursiveTask; /** * @author: lql * @date: 2019.08.24 * Description: ForkJoinDemo */ public class ForkJoinCalculate extends RecursiveTask<Long> { /** * 必须继承 : * RecursiveTask 或者 RecursiveAction * 有返回值 返回值 * @Override @Override * protected Long compute() {return null;} protected void compute() { } */ //需求:做个累加操作 /** * start:起始 * end:终止 * THRESHOLD:临界值 */ private long start; private long end; private static long THRESHOLD = 10000; public ForkJoinCalculate(long start,long end) { this.start = start; this.end = end; } @Override protected Long compute() { long length = end - start; if (length <= THRESHOLD) { //小于等于临界值将不在拆分 long sum = 0; //累加 for (long i = start; i <= end; i++ ) { sum+=i; } return sum; } else { long mid= (start + end) / 2 ; //如果没到临界值则递归去拆 ForkJoinCalculate left = new ForkJoinCalculate(start,end); left.fork(); //拆分子任务 ForkJoinCalculate right = new ForkJoinCalculate(mid+1,end); right.fork(); //汇总 return left.join()+right.join(); } } }
接下来进行测试:
package com.lql.java8; import org.junit.Test; import java.util.concurrent.ForkJoinPool; import java.util.concurrent.ForkJoinTask; /** * @author: lql * @date: 2019.08.24 * Description: ForkJoin测试 */ public class ForkTestTest { @Test public void test() { ForkJoinPool pool = new ForkJoinPool(); ForkJoinTask<Long> task = new ForkJoinCalculate(0,1000000000L); Long sum = pool.invoke(task); System.out.println(sum); } }
可以看出来代码复杂,这也是没有广泛使用起来的原因,在java8中,并行流很好的解决这种复杂性,也是做累加操作,代码如下:
@Test public void test2() { LongStream.range(0, 1000000000L).parallel().reduce(0,Long::sum); }
这里介绍下“并行流和顺序流”
并行流:就是把一个内容分成多个数据块,并用不同的线程分别处理每个数据块的流,StreamAPI可以声明性地通过parallel()与sequential()在并行流和顺序流之间进行切换
顺序流:执行过程是一个连续的步骤序列,它在完成一个活动之后会去执行到下一个
当然parallel()底层就是Fork/Join.