该书籍PDF下载地址:http://download.csdn.net/download/muyeju/10001473
Java变量命名方式:包名全小写,类名首字母全大写,常量全部大写并用下划线分隔,变量采用驼峰命名法
1.不要在常量、变量中出现易混淆的字母
例如:数字1和字母小写l,数字0和字母小写o,大写O等
2.常用值必须唯一(常量值必须在编译期确定,而且在运行期不能修改)
例如:不能用随机数或者序列号的算法等当作常量,public static final Int STATE = new Random().nextInt() ;这是不正确的
3.三元操作符的类型必须一致
例如:int d = 0 ; String s = String.valueOf(d>0?10:0.0) ;前面是int型,后面是double型,所以int类型就会向double类型转换,最终结果是10.0 ; 会造成多余的操作,会浪费时间,消耗资源,所以要避免这种操作
4.避免带有变长方法的参数重载
例如:
public void cal(int price,int discount){}
public void cal(int price,int...discount(){}
cal(1000,0.5) ->则,该方法调用的是上面哪个方法,(编译器会从最简单的开始“猜想”,只要符合编译条件的即可通过,所以会先调用第一个方法)
所以还是尽量不要用这种带变成的参数重载,可以直接用第二种,然后里面可以判断传入的值的个数,根据个数写不同的逻辑
5.别让null值和空值影响变长方法(如果要用null值,需要指定null值的类型)
例如:public static void cal(String name,String...hoby){}
cal("张三",null),这是会出现警告信息,所以可以写成这样
String[] hobys = null ; cal("张三",hobys ) ;这样说明了null值是String类型的,所以就不抱错了。或者cal("张三","")
6.重写变长方法需注意
方法名相同,参数列表相同,访问修饰符相同或是其子类,访问修饰符不能严于父类
例:下面的例子中,base.fun(1000,1)是没问题的,是子类向上转型,所以参数列表是父类决定的,在编译时,编译器通过“猜测”将1编译成了{1}数组,而sub.fun(1000,1)没有转型,编译器不会对1进行类型转换,所以就无法匹配,从而报错
Class Base{ void fun(int price ,int...discount){ System.out.println("------------Base Fun"); } } Class Sub extends Base{ void fun(int price ,int[] discount){ System.out.println("------------Base Sub"); } } public static void main(String[] args) { Base base = new Sub() ; base.fun(1000,1); Sub sub = new Sub() ; sub.fun(1000,1); }
7.自增陷阱
count++:先赋值在加1,++count:先加1在赋值
Java对自加是这样处理的:首先将count的值(注意是值,不是引用)拷贝到一个临时变量区,然后对count变量加1,最后返回临时变量区的值。
注意下面的例子:
public static void main(String[] args) { int count = 0 ; for(int i=0 ;i<10;i++){ count++ ; } System.out.println("------------"+count); 结果:------------10
解析:首先JVM将count的值拷贝到临时变量区,此时的值是0,然后对count加1,此时count是1,然后返回临时变量区的值,此时临时变量区的值还是0,但是返回临时变量区的值的值并没在对其进行操作
所以,此时count就是自加后的值
}
public static void main(String[] args) { int count = 0 ; for(int i=0 ;i<10;i++){ count=count++ ; } System.out.println("------------"+count); 结果:------------
解析:首先JVM将count的值拷贝到临时变量区,此时的值是0,然后对count加1,此时count是1,然后返回临时变量区的值,此时临时变量区的值还是0,但是将返回的临时变量区的值又
重新赋值给了count,所以count就是0
}
8.不要让旧语法困扰你
例如: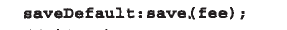 ,这个冒号是c语言的goto语句,Java语音已经抛弃了goto语句,但是还保留着关键字,它的作用可以实现条件转移,构成循环,跳槽循环等。(只是百度了一下,没有深入研究)
,这个冒号是c语言的goto语句,Java语音已经抛弃了goto语句,但是还保留着关键字,它的作用可以实现条件转移,构成循环,跳槽循环等。(只是百度了一下,没有深入研究)
9.少用静态导入
例:没得静态导入的例子
public static void main(String[] args) { //圆面积,PI是圆周率 double d = Math.PI*0.3*0.3 ; System.out.println("------------"+d); }
有静态导入的例子:(引入了java.lang.Math.PI)
package cn.com.prac.controller; import org.springframework.stereotype.Controller; import org.springframework.web.bind.annotation.RequestMapping; import static java.lang.Math.PI; @Controller @RequestMapping("/test") public class TestController { public static void main(String[] args) { //圆面积,PI是圆周率 double d = PI*0.3*0.3 ; System.out.println("------------"+d); } }
这里的PI对于熟悉的人知道是圆周率,对于不熟悉的人确不知道是什。如果要引入,就不尽量不使用带*的引入,因为到时直接调用某些方法,有时是不能从方法名知道它到底是做什么的
10.不要在本类中覆盖静态导入的常量和方法
例如:静态导入了java.lang.Math.PI和java.lang.Math.abs,然后本类中又声明了一个PI的变量,一个abs的方法,本来中在调用PI和abs()方法,那么调用的到底是本来的还是静态导入的呢?答案是:调用的是本类中的PI和本类中的abs()方法。原因:Java编译器有一个最短路径原则:如果能在本类中查找得到的变量、常量、方法,就不会到其它包或父类、接口中查找,已确保本类中的属性、方法优先。
总结:1.如果调用某个重载的变长方法,编译器会从最简单的开始“猜想”,只要符合编译条件的即可通过。
2.Java编译器有一个最短路径原则:如果能够在本类中查找得到的变量、常量、方法,就不会到其它包或其它父类、接口中查找,已确保本来中的属性、方法优先。
3.Java对自加(++)的处理:首先将自增的值(注意是值,不是引用)拷贝到一个临时变量区,然后对变量加1,最后返回临时变量区的值。