简单爬虫框架实现
目录
框架流程 调度器
url管理器 网页下载器 网页解析器 数据处理器 具体演示效果
框架流程

调度器
#导入模块
import Url_Manager
import parser_html
import html_output
import download
class SpiderMain(object):
def __init__(self):
#实例化:url管理器,网页下载器,网页解析器,数据输出
self.urls=Url_Manager.UrlManager()
self.parser=parser_html.Htmlparser()
self.download = download.download()
self.outputer=html_output.HtmlOutputer()
def craw(self,root_url):
count=1
#向列表里面添加新的单个url
self.urls.add_new_url(root_url)
#判断待爬取的url列表里面有没有新的url
while self.urls.has_new_url():
try:
#如果待爬取的url列表不为空,则取一个url出来
new_url=self.urls.get_new_url()
print('craw %d:%s' % (count,new_url))
#下载网页
html_cont=self.download.download(new_url)
#解析网页
#解析获得两个数据:新的url,以及我们要获取的数据
new_urls,new_data=self.parser.parse(new_url,html_cont)
#获取的url添加到待爬取的url列表
self.urls.add_new_urls(new_urls)
#保存数据
self.outputer.collect_data(new_data)
#如果下载的url页面达到50个,结束当前循环
if count ==50:
break
count=count+1
except:
print('craw failed')
#输出数据
self.outputer.output_html()
if __name__ == '__main__':
#开始爬取的url
url = "http://www.dili360.com/gallery/"
root_url=url
#实例化
obj_spider=SpiderMain()
obj_spider.craw(root_url)
url管理器
#url管理器需要四个方法:
#add_new_url:向管理器添加单个url
#add_new_url:向管理器添加批量的url
#has_new_url:判断管理器里面是否有新的在爬取的url
#get_new_url:在管理器中获取一个正在爬取的url
#url管理器需要维护两个列表:待爬取的url,已经爬取的url
class UrlManager(object):
def __init__(self):
#待爬取的url列表
self.new_urls=set()
#已经爬取的url列表
self.old_urls=set()
#向管理器添加单个url
def add_new_url(self,url):
#首先判断url是否为空
if url is None:
return
#如果这个url既不在待爬取的url里面也没有在已经爬取的url里面,则说明这是一个新url
if url not in self.new_urls and url not in self.old_urls:
self.new_urls.add(url)
# 向管理器添加批量的url
def add_new_urls(self,urls):
if urls is None or len(urls) ==0:
return
for url in urls:
self.add_new_url(url)
#判断管理器里面是否有新的在爬取的url
def has_new_url(self):
return len(self.new_urls) != 0
# 获取一个正在爬取的url
def get_new_url(self):
new_url = self.new_urls.pop()
self.old_urls.add(new_url)
return new_url
网页下载器
import requests
class download(object):
def download(self,url):
if url is None:
return None
else:
response = requests.get(url)
if response.status_code !=200:
return None
return response.text
网页解析器
from urllib.parse import urljoin
from bs4 import BeautifulSoup
class Htmlparser(object):
def _get_new_urls(self,page_url,soup):
new_urls = set()
#这里可以加上正则表达式,对url进行过滤
links=soup.find_all('a')
for link in links:
#补全url,添加到列表里面
new_url=link['href']
new_full_url=urljoin(page_url,new_url)
new_urls.add(new_full_url)
return new_urls
def _get_new_data(self,page_url,soup):
#解析数据,由用户来编写
new_datas=set()
imgs=soup.find_all('img')
for img in imgs:
new_data=img['src']
new_full_data=new_data
new_datas.add(new_full_data)
return new_datas
#需要解析出新的url和数据
def parse(self,page_url,html_cont):
if page_url is None or html_cont is None:
return
soup=BeautifulSoup(html_cont,'html.parser')
#调用两个本地方法:解析新的url以及解析数据
new_urls=self._get_new_urls(page_url,soup)
new_data = self._get_new_data(page_url,soup)
return new_urls,new_data
# 报错:
# UserWarning: You provided Unicode markup but also provided a value for from_encoding. Your from_encoding will be ignored.
# 解决方法:
# soup = BeautifulSoup(html_doc,"html.parser")
# 这一句中删除【from_encoding="utf-8"】
# 原因:
# python3 缺省的编码是unicode, 再在from_encoding设置为utf8, 会被忽视掉,去掉【from_encoding="utf-8"】这一个好了
数据处理器
使用文档保存文本信息
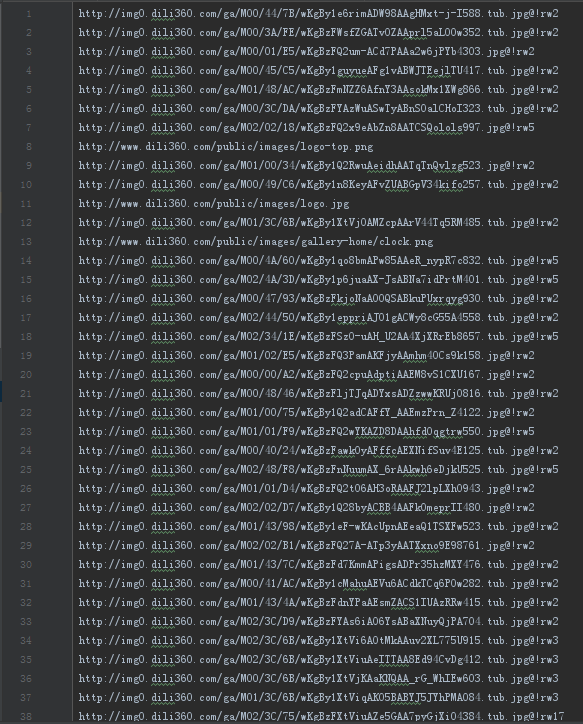
使用文件保存图片,视频文件等,可进行扩展
class HtmlOutputer(object):
def __init__(self):
self.datas=[]
def collect_data(self,data):
if data is None:
return
self.datas.append(data)
def output_html(self):
fout=open('output','a+')
for data in self.datas:
for da in data:
fout.write(str(da)+'
')
fout.close()
具体演示效果
演示url:http://www.dili360.com/gallery/
演示过程:
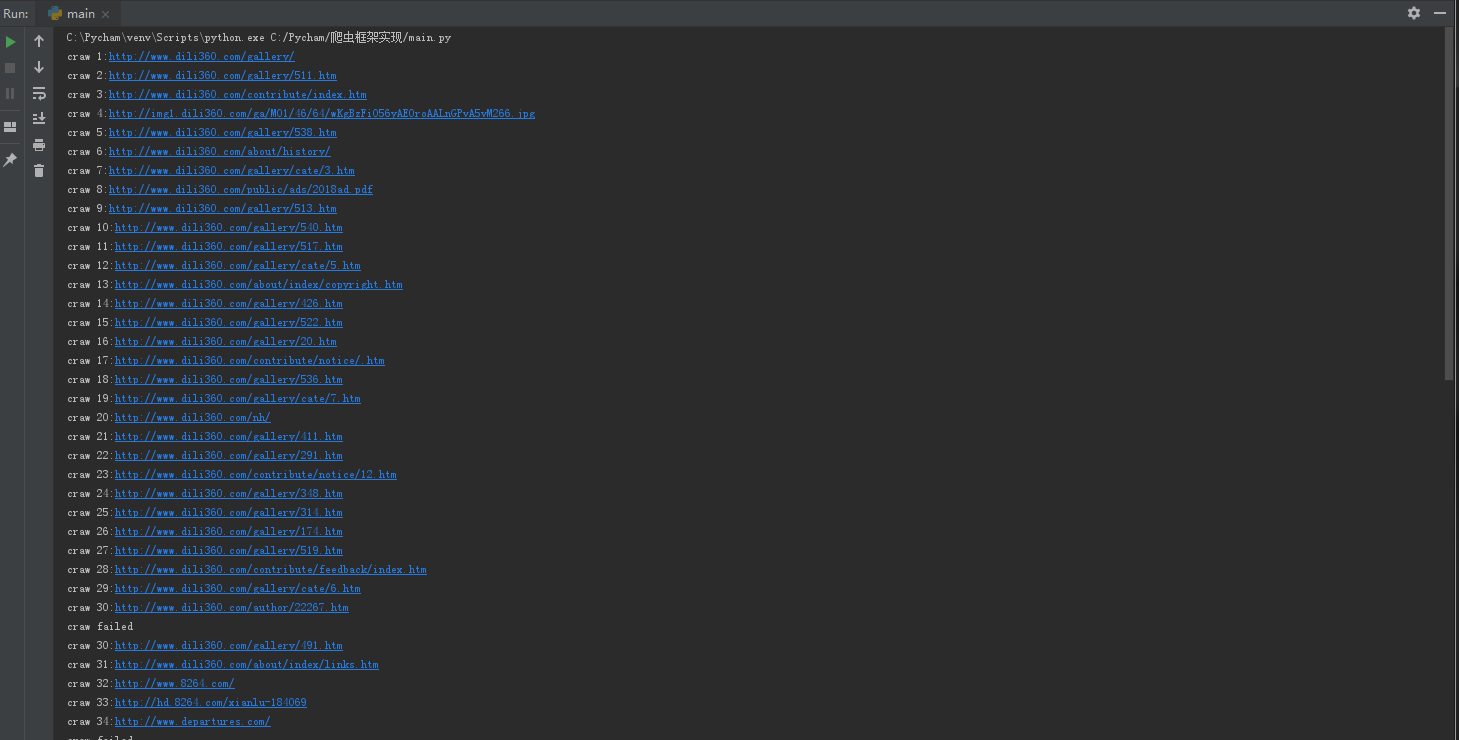
数据处理: