作者:R语言和Python学堂
链接:https://www.jianshu.com/p/35cfc959b37c
1. 什么是目标检测?
啥是目标检测?
拿上图 (用YOLOv3检测) 来说,目标检测 (Object Detection) 就是将图片中的物体用一个个矩形框框出来,并且识别出每个框中的物体是啥,而且最好的话是能够将图片的所有物体都框出来。
再来看下YOLOv3在视频上的效果:




总之,目标检测本质上包含两个任务:物体识别和物体定位。
2. 目标检测技术的概述
目前,基于深度学习(deep learning)的目标检测技术效果是最好的,这些技术模型可以分成三类:
-
R-CNN系列,包括R-CNN,Fast R-CNN,以及Faster R-CNN
-
Single Shot Detector (SSD)
-
You Only Look Once (YOLO)系列,其中YOLOv3是今天的主角
下面来简单说一下这些模型,SSD这里就不介绍了,感兴趣的话可自行去了解。
R-CNN系列
Faster R-CNN的基本原理

上图是Faster R-CNN模型的原理简图,技术细节可参考下面所提及的相关文章。
R-CNN系列的演化路径为:R-CNN → Fast R-CNN → Faster R-CNN
R-CNN 是第一个基于深度学习的目标检测模型,它属于two-stage方法,即将物体识别和物体定位分为两个步骤,分别完成。 详情见Girshick等人的第一篇相关文章:https://arxiv.org/abs/1311.2524,其原理大概为:(1) 预先找出图中物体可能出现的位置,即候选区域 (Region Proposal) 。利用图像中的纹理、边缘、颜色等信息,可以保证在选取较少窗口 (几千甚至几百) 的情况下保持较高的召回率 (Recall) 。(2) 然后将这些候选框送入CNN网络中进行识别分类。
R-CNN 方法的缺点是它太慢了;由于它采用外部的候选框算法,它也不是一个完整的端到端 (end-to-end) 检测器。
Girshick等人于2015年发表了第二篇论文 Fast R-CNN,链接为:https://arxiv.org/abs/1504.08083。相对R-CNN,Fast R-CNN算法有了很大改进,即提高了精确度,并减少了执行前向网络计算所需的时间;然而,该模型仍然依赖于外部的候选框算法。
直到2015年的后续模型 Faster R-CNN 的出现,链接为:https://arxiv.org/abs/1506.01497。通过使用区域生成网络 (Region Proposal Network, RPN)来取代候选框算法,Faster R-CNN 最终成为真正的端到端目标检测器。
虽然R-CNN系列的精确度不断提高,但是R-CNN系列最大的问题是它的速度,即使使用GPU也只能达到5 FPS.
YOLO系列
YOLO的基本原理

上图是YOLO模型的原理简图,技术细节可参考下面所提及的相关文章,YOLO官网为:https://pjreddie.com/darknet/yolo/。
为了提高基于深度学习的目标检测器的速度,SSD和YOLO都使用了one-stage策略。
这些算法将目标检测作为一个回归问题,对于给定的输入图像,同时给出边界框位置以及相应的类别。
一般来说,one-stage策略比two-stage策略的精度低,但速度快得多。
YOLO是one-stage检测器的一个很好的例子。
Redmon等人于2015年首次引入了YOLO,论文链接为:https://arxiv.org/abs/1506.02640,详细介绍了一个具有超实时目标检测能力的检测器,在GPU上获得了45 FPS。
YOLO已经经历了许多不同版本的迭代,包括YOLO9000模型,通过联合训练,它能够检测9000种不同类别的目标。虽然YOLO9000的表现有趣且新颖,但在COCO的156类数据集上,只达到了16%的平均精度(mAP)。虽然YOLO9000可以检测9000种类别,但是它的精度不是很理想。
最近,Redmon和Farhadi发表了一篇新的YOLO论文——YOLOv3: a Incremental Improvement(2018),链接为:https://arxiv.org/abs/1804.02767。YOLOv3比之前的模型更大了,但在我看来,它是YOLO目标检测器系列中最好的一个。
相比之前的算法,尤其针对小目标情况,YOLOv3的精度有显著提升。
3. 基于OpenCV的快速实现
我们将在这篇博客使用在COCO数据集上预训练好的YOLOv3模型。
COCO 数据集包含80类,有people (人),bicycle(自行车),car(汽车)......,详细类别可查看链接:https://github.com/pjreddie/darknet/blob/master/data/coco.names。
测试程序中的文件:
百度云:https://pan.baidu.com/s/1MPG89T6CrabYKLCsv_g5ZA
官网下载:https://pjreddie.com/darknet/yolo/
下面利用OpenCV来快速实现YOLO目标检测,我将其封装成一个叫yolo_detect()的函数,其使用说明可参考函数内部的注释。网络的模型和权重都已上传至百度网盘。
# -*- coding: utf-8 -*- # 载入所需库 import cv2 import numpy as np import os import time def yolo_detect(pathIn='', pathOut=None, label_path='./cfg/coco.names', config_path='./cfg/yolov3_coco.cfg', weights_path='./cfg/yolov3_coco.weights', confidence_thre=0.5, nms_thre=0.3, jpg_quality=80): ''' pathIn:原始图片的路径 pathOut:结果图片的路径 label_path:类别标签文件的路径 config_path:模型配置文件的路径 weights_path:模型权重文件的路径 confidence_thre:0-1,置信度(概率/打分)阈值,即保留概率大于这个值的边界框,默认为0.5 nms_thre:非极大值抑制的阈值,默认为0.3 jpg_quality:设定输出图片的质量,范围为0到100,默认为80,越大质量越好 ''' # 加载类别标签文件 LABELS = open(label_path).read().strip().split(" ") nclass = len(LABELS) # 为每个类别的边界框随机匹配相应颜色 np.random.seed(42) COLORS = np.random.randint(0, 255, size=(nclass, 3), dtype='uint8') # 载入图片并获取其维度 base_path = os.path.basename(pathIn) img = cv2.imread(pathIn) (H, W) = img.shape[:2] # 加载模型配置和权重文件 print('从硬盘加载YOLO......') net = cv2.dnn.readNetFromDarknet(config_path, weights_path) # 获取YOLO输出层的名字 ln = net.getLayerNames() ln = [ln[i[0] - 1] for i in net.getUnconnectedOutLayers()] # 将图片构建成一个blob,设置图片尺寸,然后执行一次 # YOLO前馈网络计算,最终获取边界框和相应概率 blob = cv2.dnn.blobFromImage(img, 1 / 255.0, (416, 416), swapRB=True, crop=False) net.setInput(blob) start = time.time() layerOutputs = net.forward(ln) end = time.time() # 显示预测所花费时间 print('YOLO模型花费 {:.2f} 秒来预测一张图片'.format(end - start)) # 初始化边界框,置信度(概率)以及类别 boxes = [] confidences = [] classIDs = [] # 迭代每个输出层,总共三个 for output in layerOutputs: # 迭代每个检测 for detection in output: # 提取类别ID和置信度 scores = detection[5:] classID = np.argmax(scores) confidence = scores[classID] # 只保留置信度大于某值的边界框 if confidence > confidence_thre: # 将边界框的坐标还原至与原图片相匹配,记住YOLO返回的是 # 边界框的中心坐标以及边界框的宽度和高度 box = detection[0:4] * np.array([W, H, W, H]) (centerX, centerY, width, height) = box.astype("int") # 计算边界框的左上角位置 x = int(centerX - (width / 2)) y = int(centerY - (height / 2)) # 更新边界框,置信度(概率)以及类别 boxes.append([x, y, int(width), int(height)]) confidences.append(float(confidence)) classIDs.append(classID) # 使用非极大值抑制方法抑制弱、重叠边界框 idxs = cv2.dnn.NMSBoxes(boxes, confidences, confidence_thre, nms_thre) # 确保至少一个边界框 if len(idxs) > 0: # 迭代每个边界框 for i in idxs.flatten(): # 提取边界框的坐标 (x, y) = (boxes[i][0], boxes[i][1]) (w, h) = (boxes[i][2], boxes[i][3]) # 绘制边界框以及在左上角添加类别标签和置信度 color = [int(c) for c in COLORS[classIDs[i]]] cv2.rectangle(img, (x, y), (x + w, y + h), color, 2) text = '{}: {:.3f}'.format(LABELS[classIDs[i]], confidences[i]) (text_w, text_h), baseline = cv2.getTextSize(text, cv2.FONT_HERSHEY_SIMPLEX, 0.5, 2) cv2.rectangle(img, (x, y-text_h-baseline), (x + text_w, y), color, -1) cv2.putText(img, text, (x, y-5), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 0), 2) # 输出结果图片 if pathOut is None: cv2.imwrite('with_box_'+base_path, img, [int(cv2.IMWRITE_JPEG_QUALITY), jpg_quality]) else: cv2.imwrite(pathOut, img, [int(cv2.IMWRITE_JPEG_QUALITY), jpg_quality])
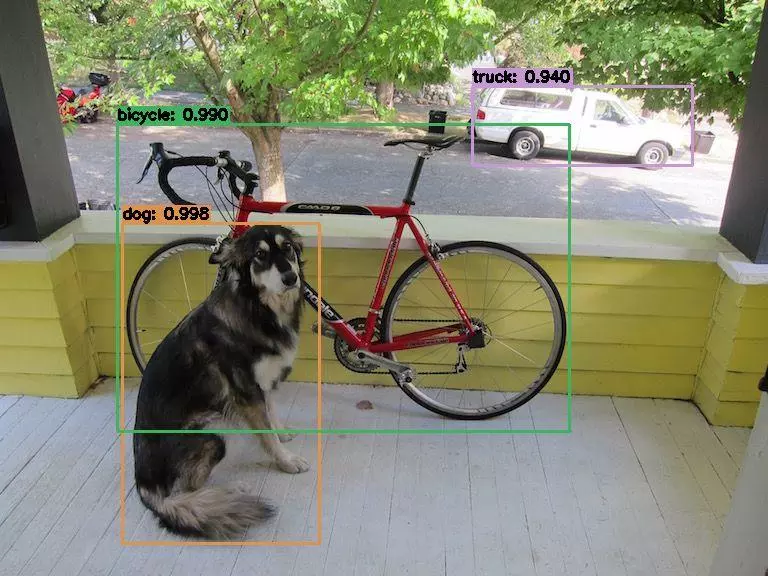
来测试一下:
pathIn = './test_imgs/test1.jpg' pathOut = './result_imgs/test1.jpg' yolo_detect(pathIn,pathOut) >>> 从硬盘加载YOLO...... >>> YOLO模型花费 3.63 秒来预测一张图片 pathIn = './test_imgs/test2.jpg' pathOut = './result_imgs/test2.jpg' yolo_detect(pathIn,pathOut) >>> 从硬盘加载YOLO...... >>> YOLO模型花费 3.55 秒来预测一张图片 pathIn = './test_imgs/test3.jpg' pathOut = './result_imgs/test3.jpg' yolo_detect(pathIn,pathOut) >>> 从硬盘加载YOLO...... >>> YOLO模型花费 3.75 秒来预测一张图片
结果为:



从运行结果可知,在CPU上,检测一张图片所花的时间大概也就3到4秒。如果使用GPU,完全可以实时对视频/摄像头进行目标检测。
结合之前的博客用Python提取视频中的图片,可将YOLOv3应用于视频流。
YOLOv3最大的局限性和缺点就是:对于小物体,有时检测效果不佳;尤其不善于处理靠得很近的物体。
这些缺点都是由YOLO自身的算法所导致的:首先YOLO将输入图像划分为一个SxS的网格,网格中的每个单元格只预测一个对象。如果在一个单元格中存在多个小对象,那么YOLO将无法检测它们,最终导致检测对象的丢失。
因此,如果你知道你的数据集包含许多小物体,而且这些小物体也靠得很近,那么你不应该使用YOLO目标检测器。在小物体方面,Faster R-CNN效果是最好,尽管它的速度是最慢的。