1,概念理解
爬虫:抓取和保存网页信息,用户看到的网页实质是由 HTML 代码构成的,爬虫爬来的便是这些内容,通过分析和过滤这些 HTML 代码,实现对图片文字等资源的获取。
URL:即统一资源定位符,也就是我们说的网址,统一资源定位符是对可以从互联网上得到的资源的位置和访问方法的一种简洁的表示,是互联网上标准资源的地址。url由三部分组成:①第一部分是协议(或称为服务方式)。②第二部分是存有该资源的主机IP地址(有时也包括端口号)。③第三部分是主机资源的具体地址,如目录和文件名等。
2,urllib使用,暴力扒网页
import urllib2
#request = urllib2.Request("http://www.baidu.com") #实际上这一句可写可不写,但是考虑到访问网站的流程:发请求,响应,解析网页;建议写上 response = urllib2.urlopen("http://www.baidu.com") print response.read() #扒下来的是它的整个HTML,所以内容很嘈杂
知识点1:urlopen(url, data, timeout) #urlopen函数有三个参数,第一个参数url即为URL,第二个参数data是访问URL时要传送的数据,比如:response = urllib2.urlopen("http://www.baidu.com","nihao")实际上访问的是http://www.baidu.com/nihao。第三个timeout是设置超时时间(有可能还可以设置headers,下文有实例)。
知识点2:print response.read() #response是一个对象,如果不加read()会打印出对于对象的描述而不是打印出网页内容
3,post和get数据传递,类似于输入用户名和密码
GET方式是直接以链接形式访问,链接中包含了所有的参数。
POST则不会在网址上显示所有的参数。
POST方式的实例:
import urllib #引用urllib主要是想利用其urlencode这个函数,它可以把一个包含登录信息的values字典传递给data然后给Resquest函数使用
import urllib2
values = {"username":"1016903103@qq.com","password":"XXXX"} #包含登录信息的一个字典,当然了,由于验证码,此处实际上登录不了,仅做用法参考
data = urllib.urlencode(values) #用urlencode给包含登录信息的字典编码,这样才能传递参数给Request。
url = "https://passport.csdn.net/account/login?from=http://my.csdn.net/my/mycsdn" #接下来是抓取的一般流程
request = urllib2.Request(url,data)
response = urllib2.urlopen(request)
print response.read()
GET方式实例:
import urllib
import urllib2
values={} #第一步和post方法一样,建立一个用户名用户密码等信息的字典
values['username'] = "1016903103@qq.com"
values['password']="XXXX"
data = urllib.urlencode(values) #给字典编码
url = "http://passport.csdn.net/account/login"
geturl = url + "?"+data #直接把网址加上”?“加上登录信息字典,注意,这种方法会在网址上显示所有的参数,保密性不如post好。
request = urllib2.Request(geturl)
response = urllib2.urlopen(request)
print response.read()
4,设置headers
为什么要设置headers?因为有些网站禁止urllib的访问形式,大约是设置了防止爬虫程序吧。
访问网站的时候,通常首先发送请求,Request URL一般包含以下信息:
General:
Response Headers:
略... #详细可谷歌查看f12-network-headers
除此以外,还有个agent信息,agent是请求身份,把请求身份加入到headers中,代码如下:
import urllib
import urllib2
url = 'http://www.server.com/login' #网址
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)' #设置agent
values = {'username' : 'cqc', 'password' : 'XXXX' } #设置登录信息
headers = { 'User-Agent' : user_agent } #把agent信息包装在headers中,然后传入访问请求的第三个参数中
data = urllib.urlencode(values) #以下流程和带登录信息的爬取程序是一样的。
request = urllib2.Request(url, data, headers)
response = urllib2.urlopen(request)
page = response.read()
对付防盗链的基本原理是,网站服务器会识别headers中的referer是不是它自己,如果不是,有的服务器不会响应,所以我们还可以在headers中加入referer,基本原理和加入agent是一样的,把headers的值改一改就可以:
headers = { 'User-Agent' : user_agent ,'Referer':'http://www.zhihu.com/articles'}
除了agent和headers,headers还有以下属性影响到爬虫是否成功,先简单知道就可以啦:
User-Agent : 有些服务器或 Proxy 会通过该值来判断是否是浏览器发出的请求
Content-Type : 在使用 REST 接口时,服务器会检查该值,用来确定 HTTP Body 中的内容该怎样解析。
application/xml : 在 XML RPC,如 RESTful/SOAP 调用时使用
application/json : 在 JSON RPC 调用时使用
application/x-www-form-urlencoded : 浏览器提交 Web 表单时使用
在使用服务器提供的 RESTful 或 SOAP 服务时, Content-Type 设置错误会导致服务器拒绝服务
5 Proxy代理设置
urllib2 默认会使用环境变量 http_proxy 来设置 HTTP Proxy。假如一个网站设置了检测机制,比如检查单位时间某个IP 的访问次数,如果次数过多,它会禁止访问。所以你可以设置一些代理服务器来帮助你做工作,每隔一段时间换一个代理,这样就不会被网站封禁了。
import urllib2 enable_proxy=True proxy_handler=urllib2.ProxyHandler({"http":"http://some-proxy.com:8080"}) null_proxy_handler = urllib2.ProxyHandler({}) if enable_proxy: opener=urllib2.ProxyHandler({}) else: opener=urllib2.build_opener(null_proxy_handler) urllib2.install_opener(opener) # 暂时看不很懂,回头做几个实例试试把
6 timeout设置,等待时间
为了避免有些网站响应过慢,可以认为设置等待响应的时间,即:timeout参数:
import urllib2 response = urllib2.urlopen('http://www.baidu.com',data, timeout=10) #默认timeout参数为urlopen的第三个参数
7 http中的put和delete方式
http协议有六种请求方法,get,head,put,delete,post,options。put和delete方式比较少用,仅了解
8 爬虫异常处理:
URLError:原因:网络问题,服务器问题。
import urllib2 requset = urllib2.Request('http://www.xxxxx.com') try: urllib2.urlopen(request) except urllib2.URLError, e: print e.reason #由于是错误的网址,执行后返回Error:getaddrinfo faild,没法获取链接信息,也有的电脑上显示:Connection timed out
HRRPError:是网站服务器response中包含的一个状态码,常见状态码如下:
100:继续 客户端应当继续发送请求。客户端应当继续发送请求的剩余部分,或者如果请求已经完成,忽略这个响应。 101: 转换协议 在发送完这个响应最后的空行后,服务器将会切换到在Upgrade 消息头中定义的那些协议。只有在切换新的协议更有好处的时候才应该采取类似措施。 102:继续处理 由WebDAV(RFC 2518)扩展的状态码,代表处理将被继续执行。 200:请求成功 处理方式:获得响应的内容,进行处理 201:请求完成,结果是创建了新资源。新创建资源的URI可在响应的实体中得到 处理方式:爬虫中不会遇到 202:请求被接受,但处理尚未完成 处理方式:阻塞等待 204:服务器端已经实现了请求,但是没有返回新的信 息。如果客户是用户代理,则无须为此更新自身的文档视图。 处理方式:丢弃 300:该状态码不被HTTP/1.0的应用程序直接使用, 只是作为3XX类型回应的默认解释。存在多个可用的被请求资源。 处理方式:若程序中能够处理,则进行进一步处理,如果程序中不能处理,则丢弃 301:请求到的资源都会分配一个永久的URL,这样就可以在将来通过该URL来访问此资源 处理方式:重定向到分配的URL 302:请求到的资源在一个不同的URL处临时保存 处理方式:重定向到临时的URL 304:请求的资源未更新 处理方式:丢弃 400:非法请求 处理方式:丢弃 401:未授权 处理方式:丢弃 403:禁止 处理方式:丢弃 404:没有找到 处理方式:丢弃 500:服务器内部错误 服务器遇到了一个未曾预料的状况,导致了它无法完成对请求的处理。一般来说,这个问题都会在服务器端的源代码出现错误时出现。 501:服务器无法识别 服务器不支持当前请求所需要的某个功能。当服务器无法识别请求的方法,并且无法支持其对任何资源的请求。 502:错误网关 作为网关或者代理工作的服务器尝试执行请求时,从上游服务器接收到无效的响应。 503:服务出错 由于临时的服务器维护或者过载,服务器当前无法处理请求。这个状况是临时的,并且将在一段时间以后恢复。
import urllib2 req = urllib2.Request('http://blog.csdn.net/cqcre') try: urllib2.urlopen(req) except urllib2.HTTPError, e: print e.code #e.code()是网页状态码,当然了此处并不会执行expect语句,仅供参考 print e.reason
9 cookie使用
Cookie,指某些网站为了辨别用户身份、进行session跟踪而储存在用户本地终端上的数据。opener我的理解是相当于获取网页内容并且解析该内容的操作,可以理解为urlopener,由于urlopener只有三个参数:url,data,timeout,所以想使用cookie爬取某些信息得用更加普遍的工具实现对cookie的设置。该模块就是cookielib。
使用Cookie Jar可以获取cookie:
import urllib2 import cookielib #声明一个CookieJar对象实例来保存cookie,cookie是一个实例,需要迭代才能打印出内容。 cookie = cookielib.CookieJar() #利用urllib2库的HTTPCookieProcessor对象来创建cookie处理器 handler=urllib2.HTTPCookieProcessor(cookie) #不是特别理解本句的内容 #通过handler来构建opener opener = urllib2.build_opener(handler) #不是特别理解 #此处的open方法同urllib2的urlopen方法,也可以传入request response = opener.open('http://www.baidu.com') #注意此处用的不是urlopen,是自定义的opener for item in cookie: print 'Name = '+item.name print 'Value = '+item.value
保存cookie到文件:
import cookielib import urllib2 # 设置保存cookie的文件,同级目录下的cookie.txt filename = 'cookie.txt' # 声明一个MozillaCookieJar对象实例来保存cookie,之后写入文件 cookie = cookielib.MozillaCookieJar(filename) # 利用urllib2库的HTTPCookieProcessor对象来创建cookie处理器 handler = urllib2.HTTPCookieProcessor(cookie) # 通过handler来构建opener opener = urllib2.build_opener(handler) # 创建一个请求,原理同urllib2的urlopen response = opener.open("http://www.baidu.com") # 保存cookie到文件 cookie.save(ignore_discard=True, ignore_expires=True)
从文件中获取cookie并且访问:
import cookielib import urllib2 #创建MozillaCookieJar实例对象 cookie = cookielib.MozillaCookieJar() #从文件中读取cookie内容到变量 cookie.load('cookie.txt', ignore_discard=True, ignore_expires=True) #假设cookie已经在文件中了 #创建请求的request req = urllib2.Request("http://www.baidu.com") #利用urllib2的build_opener方法创建一个opener opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookie)) response = opener.open(req) print response.read()
利用cookie模拟网站登录:
import urllib import urllib2 import cookielib filename = 'cookie.txt' #此文件用于存储第一次登录后的cookie cookie = cookielib.MozillaCookieJar(filename) #后面的程序会把将cookie信息写入filename opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookie)) postdata = urllib.urlencode({ 'stuid':'201200131012', 'pwd':'23342321' }) #这个是抄的,目测百度账号不可以这样登录 loginUrl = 'http://jwxt.sdu.edu.cn:7890/pls/wwwbks/bks_login2.login' #模拟登录,并把cookie保存到变量 result = opener.open(loginUrl,postdata) #保存cookie到cookie.txt中 cookie.save(ignore_discard=True, ignore_expires=True) #利用cookie请求访问另一个网址,此网址是成绩查询网址 gradeUrl = 'http://jwxt.sdu.edu.cn:7890/pls/wwwbks/bkscjcx.curscopre' #请求访问成绩查询网址 result = opener.open(gradeUrl) print result.read()
10 正则
正则表达式的语法:来自CSDN
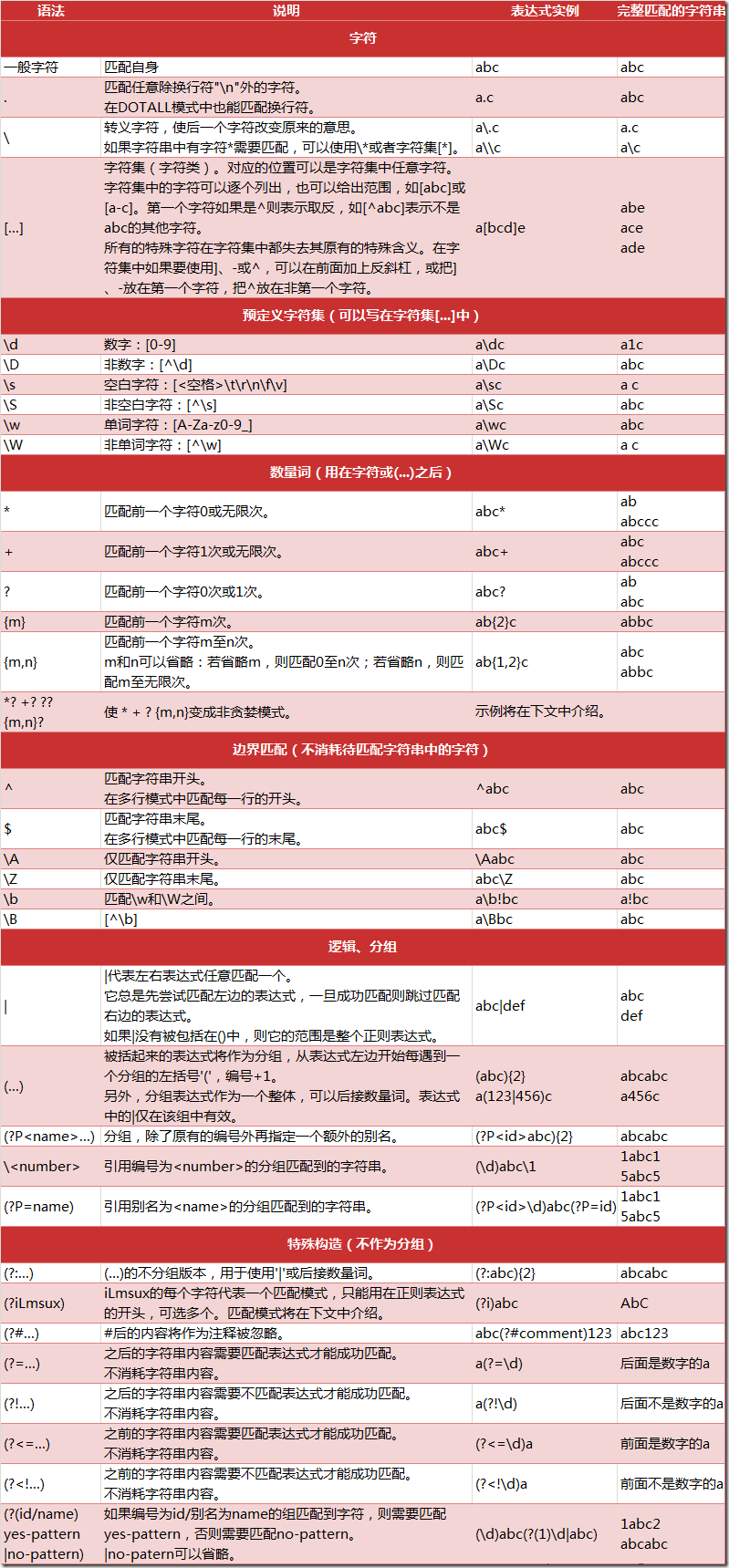
正则表达式实例:match:从开头开始匹配
import re pattern=re.compile(r"hello") #匹配“hello”这个字符串 result=re.match(pattern,'hello python') #从“hello python"中匹配,re,match(r'hello','hello pyton')也可以 if result: print result.group() #打印出匹配的字符串 else: print "failed"
实例:search:查找第一个符合条件的
import re result=re.search(r'pyth','hello python pythee') if result: print result.group() else: print "failed"
实例:findall
import re result=re.findall(r'pyth','hello python pythee') if result: print result else: print "failed"
实例:finditer
import re pattern = re.compile(r'd+') for m in re.finditer(pattern,'one1two2three3four4'): print m.group(),
实例:替换sub
import re pattern = re.compile(r'(w+) (w+)') #w表示单词 s = 'i say, hello world!' print re.sub(pattern, r'2 1', s) #sub括号里的参数依次是匹配模式,变化后 的样子,源字符串