1 数据读写
1.1 DataFrameReader
| 组件 | 解释 |
|---|---|
|
|
结构信息, 因为 |
|
|
连接外部数据源的参数, 例如 |
|
|
外部数据源的格式, 例如 |
读取文件的方式
1.2 DataFrameWriter
| 组件 | 解释 |
|---|---|
|
|
写入目标, 文件格式等, 通过 |
|
|
写入模式, 例如一张表已经存在, 如果通过 |
|
|
外部参数, 例如 |
|
|
类似 |
|
|
类似 |
|
|
用于排序的列, 通过 |
mode 指定了写入模式, 例如覆盖原数据集, 或者向原数据集合中尾部添加等
Scala 对象表示 | 字符串表示 | 解释 |
|---|---|---|
|
|
|
将 |
|
|
|
将 |
|
|
|
将 |
|
|
|
将 |
写入文件的方式
1.3 读写 Parquet 格式文件
总结
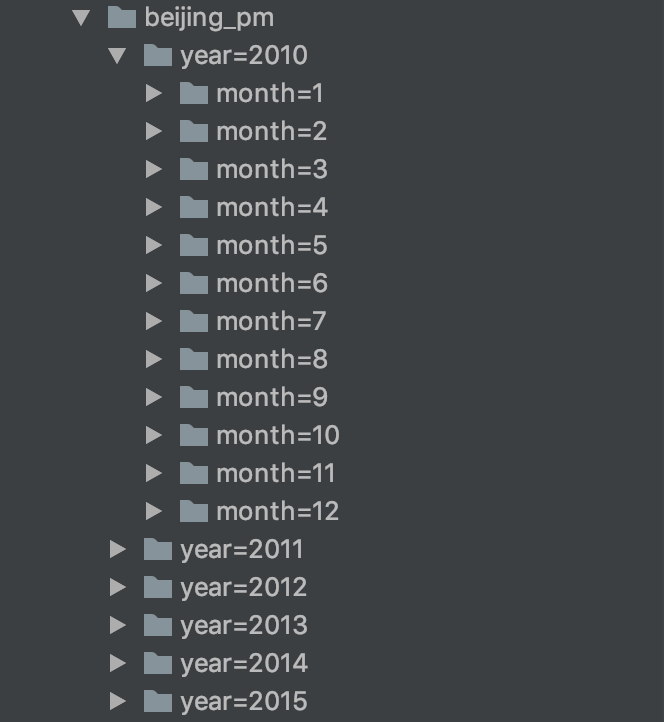
- Spark 不指定 format 的时候默认就是按照 Parquet 的格式解析文件
- Spark 在读取 Parquet 文件的时候会自动的发现 Parquet 的分区和分区字段
- Spark 在写入 Parquet 文件的时候如果设置了分区字段, 会自动的按照分区存储
1.4 读写 JSON 格式文件
1.5 Spark访问Hive
Hive的MetaStore
概念
Hive 的 MetaStore 是一个 Hive 的组件, 一个 Hive 提供的程序, 用以保存和访问表的元数据