OneR原理:一个属性决定类。
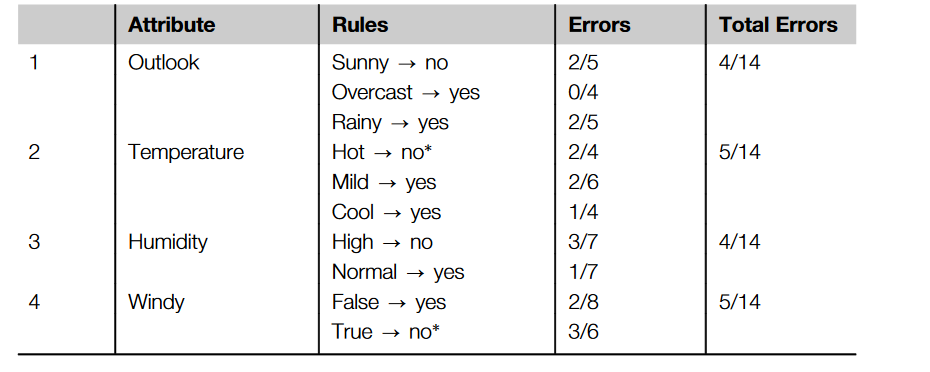
算法步骤

中文描述如下:
For 对于每一个属性:
For 对于属性的每一个值,创建规则如下:
计算每一个类(值)出现的次数
找到出现最多的类
创建规则:把这个出现最多的类赋值给属性值(比如 OutLook中Sunny-->yes)
计算每一个属性规则集合的错误率
找到错误率最低属性集合
举例 weather.nomiral.arff
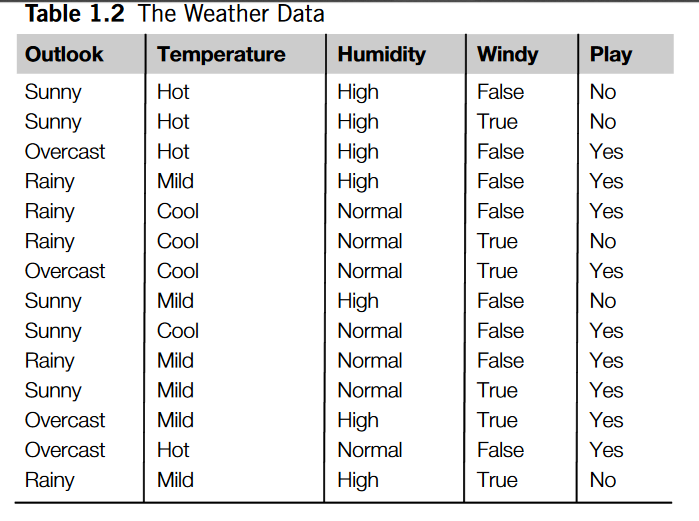
对于每个属性重复上述步骤后:(带星号表示可选,也就是说类值可以选yes也可以选no)
特殊情况:1.对于遗失值的属性而言,可以通过把Missing Value当作一个属性值 比如 OutLook就具有四个值:Sunny,Overcast,Rainy,Missing Value
2.对于数字值得属性而言,该如何操作呢?
针对第二种情况 我们可以使用离散型的方法把数字属性转换为名词属性,具体步骤如下:
以weather.numeric.arff中温度为例
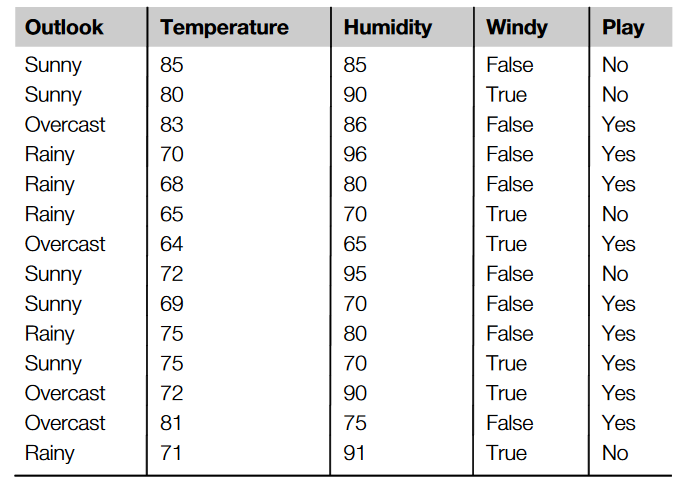
第一步:根据数字属性的值来选择训练案例

第二步:通过设置断点来分割这个数字序列,断点:类变化的那个点作为断点
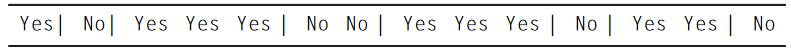
第三步:选择断点为两边的中间值,依次为:64.5,66.5,70.5,72,77.5,80.5,84,
但是两个实例中值都为72,可是对应的类不同。这个如何处理?
最简单的解决方法是通过把断点移动到72以上的一个案例,移动到73.5(正好为(72+75)/2),这样就产生了一个混合的划分,在这个划分中no占大多数。
第四步:可能会产生过度拟合(overfitting的概念将在下一章讲解)问题,
问题描述:比如对于训练集中的每一个实例,某个属性总有不同的属性值。从而标识码属性就能唯一的标识实例,这对于训练集而言会产生零错误率(因为每个分区都只有一个实例)。这个标识码属性将不会在训练集正确的外部得到任何示例。这种就是overfitting现象。处理办法?
解决办法
1.对于oneR来说,当某个属性有大量的可能值时,过度拟合就很有可能发生。因此,在离散化一个 数字类型属性时,加上一个条件---即每个分区中的大多数类的个数必须满足一个最小值。
不妨设置为3,那么上述分区变为如下

2.在第一个分区中,要确保大多数类(yes)至少有三条记录。然而,接下来的还是yes,我们完全可以把这个也划分到第一个分区,新的分割如下
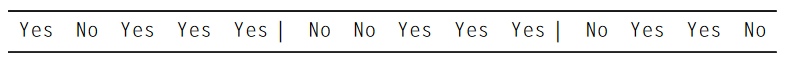
3.从上述图片中看到,除了最后一个,其它的分区都满足至少有三个大多数类记录。
其实第一个分区和第二个分区的大多数类都是yes,当我们融合两个分区时,对于规则集合没影响。融合图如下:

第五步:最后得到 规则集合
temperature : <=77.5 --->yes 2/10
>77.5 ----->no 2/4
温馨提醒!
如果数字属性有已经遗失的值,将会为它创建一个额外的类别。离散程序作用这些实例的时候,会把这个属性的值作为已经定义