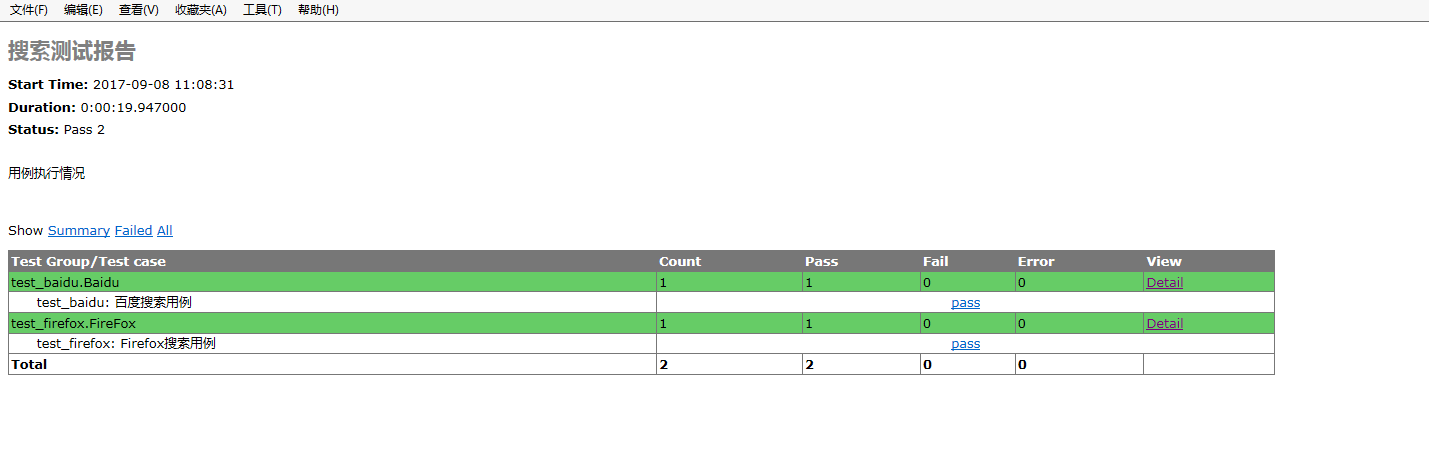
当自动化测试完成后,我们需要一份漂亮且通俗易懂的测试报告来展示自动化测试成果,仅仅一个简单的log文件是不够的
HTMLTestRunner是Python标准库unittest单元测试框架的一个扩展,它生成易于使用的HTML测试报告,下载后,将其复制到Python的安装目录即可,
例如,Windows,放在...python27Lib目录下
补充知识:
1、Python注释
普通注释用#表示
文本注释,放在类或者方法下面:""" 注释内容 """或者 '''注释内容 '''
2、测试报告以测试时间来命名,防止报告被覆盖
time.time():获取当前时间戳
time.ctime():当前时间的字符串形式
time.localtime():当前时间的struct_time形式
time.strftime():用来获取当前时间,可以讲师时间格式化为字符串
下面是项目集成生成测试报告源码:
test_case文件下的两个测试用例
test_baidu.py
# -*- coding: utf-8 -*-
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import Select
from selenium.common.exceptions import NoSuchElementException
from selenium.common.exceptions import NoAlertPresentException
import unittest, time, re
class Baidu(unittest.TestCase):
def setUp(self):
self.driver = webdriver.Firefox()
self.driver.implicitly_wait(30)
self.base_url = "https://www.baidu.com/"
self.verificationErrors = []
self.accept_next_alert = True
def test_baidu(self):
u"""百度搜索用例"""
driver = self.driver
driver.get(self.base_url + "/?tn=98012088_5_dg&ch=12")
driver.find_element_by_id("kw").clear()
driver.find_element_by_id("kw").send_keys("select")
driver.find_element_by_id("su").click()
time.sleep(3)
def tearDown(self):
self.driver.quit()
if __name__ == "__main__":
unittest.main()
test_firefox.py
# -*- coding: utf-8 -*-
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import Select
from selenium.common.exceptions import NoSuchElementException
from selenium.common.exceptions import NoAlertPresentException
import unittest, time, re
class FireFox(unittest.TestCase):
def setUp(self):
self.driver = webdriver.Firefox()
self.driver.implicitly_wait(30)
self.base_url = "http://start.firefoxchina.cn/"
self.verificationErrors = []
self.accept_next_alert = True
def test_firefox(self):
u"""Firefox搜索用例"""
driver = self.driver
driver.get(self.base_url + "/")
driver.find_element_by_id("search-key").clear()
driver.find_element_by_id("search-key").send_keys("selenium webdriver")
driver.find_element_by_id("search-submit").click()
time.sleep(5)
def tearDown(self):
self.driver.quit()
if __name__ == "__main__":
unittest.main()
执行测试用例的run_test.py
#coding=utf-8 import unittest, doctest import HTMLTestRunner import time #相对路径定义用例存放的路径和报告存放路径 test_dir='./test_case' test_dir1='./report'
#查找对应路径下的测试用例放到discover中 discover=unittest.defaultTestLoader.discover(test_dir,pattern='test*.py') #定义带有当前测试时间的报告,防止前一次报告被覆盖 now=time.strftime("%Y-%m-%d %H_%M_%S") filename=test_dir1+ '/' +now+ 'result.html' #二进制打开,准备写入文件 fp = file(filename, 'wb') #定义测试报告 runner =HTMLTestRunner.HTMLTestRunner( stream=fp, title=u'搜索测试报告', description=u'用例执行情况') runner.run(discover)
最后生成的生成的html测试报告如下: