函数: fun(){
body
return
}
读入数据使用read 读取函数的返回return使用 $?
#!/bin/bash
#author:Frank
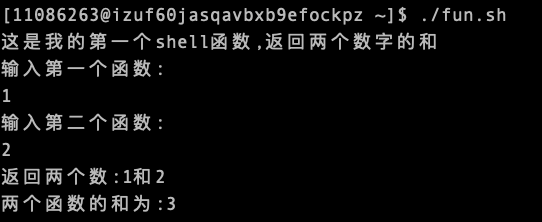
fun(){
echo "这是我的第一个shell函数,返回两个数字的和"
echo "输入第一个函数:"
read num1
echo "输入第二个函数:"
read num2
echo "返回两个数:$num1和$num2"
return $(($num1+num2))
}
fun
echo "两个函数的和为:$?"
函数参数:$10 不能获取第十个参数,获取第十个参数需要${10}。当n>=10时,需要使用${n}来获取参数。
fun(){
echo "返回第一个参数:$1"
echo "返回第二个参数:$9"
echo "返回第10个参数:$10"
echo "返回第10个参数:${10}"
echo "返回参数的个数:$#"
echo "返回所有参数作为一个字符串:$*"
}
fun 1 2 3 4 5 6 7 8 9 20 30 40

shell 的输入和输出:
read用来读取输入,并赋值给变量,echo printf 可以输出变量
>file 可以将输出重定项到另一个文件夹 >>表示追加
<file 表示输入重定项 | 表示把前一项输出传入到下一个命令的输入
标准输入用0表示 标准输出用1表示, 标准错误输出用2表示 2>&1 >logs 会将标准的错误输出和正常的输出都重定向到logs
[11086263@izuf60jasqavbxb9efockpz ~]$ echo hello world | while read x;do echo $x>babys;done
[11086263@izuf60jasqavbxb9efockpz ~]$ cat babys
hello world
LINUX 三剑客
grep 基于正则表达式查找满足条件的 行 (定位) select * from table
awk 根据查到的数据处理其中的分段 列 (数据切片) select ziduan from table
sed 根据定位到的数据修改数据 (数据修改) updata table set file=new where file=old
[11086263@izuf60jasqavbxb9efockpz ~]$ cat babys
hello world
12346
00000
2345678
[11086263@izuf60jasqavbxb9efockpz ~]$ cat babys | grep "Hello" 大写导致匹配不出数据
[11086263@izuf60jasqavbxb9efockpz ~]$ cat babys | grep -i "Hello" -i 不区分大小写
hello world
[11086263@izuf60jasqavbxb9efockpz ~]$ cat babys | grep -i -v "Hello" -v去掉匹配出来的数据,输出剩余数据
12346
00000
2345678
[11086263@izuf60jasqavbxb9efockpz ~]$ cat babys | grep -i -v -o "Hello"
[11086263@izuf60jasqavbxb9efockpz ~]$ cat babys | grep -i -o "Hello" -o 把每个匹配的内容用独立的行表示出来
hello
"12346" -A -B -C 后面都跟阿拉伯数字,-A是显示匹配后和它后面的n行。-B是显示匹配行和它前面的n行。-C是匹配行和它前后各n行。总体来说,-C覆盖面最大[11086263@izuf60jasqavbxb9efockpz ~]$ cat babys | grep -A 2
12346
00000
2345678
[11086263@izuf60jasqavbxb9efockpz ~]$ grep "2" -nr ./babys #grep是在当前目录下(或者是制定目录下)递归搜索 -n是输出行数的意思
2:12346
4:2345678
[11086263@izuf60jasqavbxb9efockpz ~]$ cat babys |grep "2" -nr $x
grep: 00000: 没有那个文件或目录
正则表达式
基本表达式
^表示开头$表示结尾
[0-9] [a-z] 代表区间 [1-9]表示1-9的整数区间,[^1-9]
*表示0个或多个
扩展表达式
?表示非贪婪匹配
+表示一个或多个
()表示分组
{}表示范围分布
| 匹配多个表达式中的任意一个
awk
awk理论上可以代替grep
awk 'pattern{action}'
awk 'BEGIN{}END{}' 开始和结束 awk '/Running/' 正则匹配
awk '/aa/,/bb/' 区间选择
awk '$2~/xxx/' 字段匹配
awk 'NR==2' 取第二行 awk 'NR>1' 去掉第一行
用法一: $awk '{[pattern] action}'{filenames}:
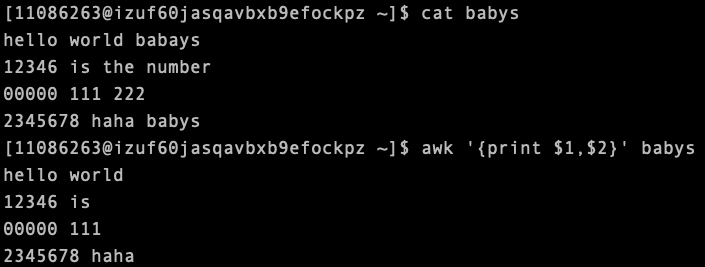
-F' ' 表示把搜索结果按照空格分割

去掉前两行结果

-F 参数指定字段分隔符
BEGIN{FS="_"} 也可以表示分隔符
$0代表当前的记录 $1代表第一个字段
$N 代表第N个字段
$NF 代表最后一个字段
-v 设置参数 $1引用第一个参数


运算符:
|| 或 &&与 in 数组成员 < <= > >= != ==关系运算符 ~ ~!匹配正则表达式和不匹配正则表达式


内建变量
FS 字段分隔符
OFS 输出数据的字段分隔符
RS 记录分隔符
ORS 输出字段的行分隔符
NF 字段数
NR 记录数

字段分割:
echo $PATH | awk 'BEGIN{RS=":"}{print $0}' | awk -F/ '{print $1,$2,$3,$4}' #先把字符串按照 :分割后逐行显示, 然后 按照/将每行分割成列
echo $PATH | awk 'BEGIN{RS=":"}{print $0}'
| awk 'BEGIN{FS="/"}{print $1,$2,$3,$4}'
echo $PATH | awk 'BEGIN{RS=":"}{print $0}' | awk 'BEGIN{FS="/|-"}{print $1,$2,$3,$4}'
修改OFS和ORS让$0重新计算
echo $PATH | awk 'BEGIN{FS=":";OFS=" | "}{$1=$1;print $0}'
echo $PATH | awk 'BEGIN{RS=":";ORS="^"}{print $0}'
把单行分拆为多行
echo $PATH | awk 'BEGIN{RS=":"}{print $0}'
echo $PATH | awk 'BEGIN{RS=":"}{print NR,$0}'
echo $PATH | awk 'BEGIN{RS=":"}END{print NR}'
echo $PATH | awk 'BEGIN{RS=":"}{print $0}' | awk 'BEGIN{FS=" ";ORS=":"}{print $0}'
多行合并成单行
echo $PATH | awk 'BEGIN{RS=":"}{print $0}' | awk 'BEGIN{FS=" ";ORS=":"}{print $0}'
sed
sed [addr]X[options] -e 表达式
sed -n '2p' 打印第二行
sed 's#hello#world#' 修改
-i 直接修改源文件
-E 扩展表达式
--debug 调试
echo $PATH | awk 'BEGIN{RS=":"}{print $0}' | sed 's#/ #----#g'
echo $PATH | awk 'BEGIN{RS=":"}{print $0}' | sed -n '/ ^/bin/,/sbin/p'
sed -i '.bak' -e '' -e ''
