一次完整的http请求过程是什么样的
当我们在web浏览器的地址栏中输入: www.baidu.com,然后回车,到底发生了什么
过程概览
1.对www.baidu.com这个网址进行DNS域名解析,得到对应的IP地址
2.根据这个IP,找到对应的服务器,发起TCP的三次握手
3.建立TCP连接后发起HTTP请求
4.服务器响应HTTP请求,浏览器得到html代码
5.浏览器解析html代码,并请求html代码中的资源(如js、css图片等)(先得到html代码,才能去找这些资源)
6.浏览器对页面进行渲染呈现给用户
注:1.DNS域名解析采用的是递归查询的方式,过程是,先去找DNS缓存->缓存找不到就去找根域名服务器->根域名又会去找下一级,这样递归查找之后,找到了,给我们的web浏览器
2.为什么HTTP协议要基于TCP来实现? TCP是一个端到端的可靠的面相连接的协议,HTTP基于传输层TCP协议不用担心数据传输的各种问题(当发生错误时,会重传)
3.最后一步浏览器是如何对页面进行渲染的? a)解析html文件构成 DOM树,b)解析CSS文件构成渲染树, c)边解析,边渲染 , d)JS 单线程运行,JS有可能修改DOM结构,意味着JS执行完成前,后续所有资源的下载是没有必要的,所以JS是单线程,会阻塞后续资源下载
下面我们来详细看看这几个过程的具体细节:
1.域名解析
a)首先会搜索浏览器自身的DNS缓存(缓存时间比较短,大概只有1分钟,且只能容纳1000条缓存)
b)如果浏览器自身的缓存里面没有找到,那么浏览器会搜索系统自身的DNS缓存
c)如果还没有找到,那么尝试从 hosts文件里面去找
d)在前面三个过程都没获取到的情况下,就递归地去域名服务器去查找,具体过程如下

DNS优化:两个方面:DNS缓存、DNS负载均衡
2.TCP连接(三次握手)
拿到域名对应的IP地址之后,User-Agent(一般指浏览器)会以一个随机端口(1024<端口<65535)向服务器的WEB程序(常用的有httpd,nginx)等的80端口。这个连接请求(原始的http请求经过TCP/IP4层模型的层层封包)到达服务器端后(这中间有各种路由设备,局域网内除外),进入到网卡,然后是进入到内核的TCP/IP协议栈(用于识别连接请求,解封包,一层一层的剥开),还有可能要经过Netfilter防火墙(属于内核的模块)的过滤,最终达到WEB程序,最终建立了TCP/IP的连接
图解:
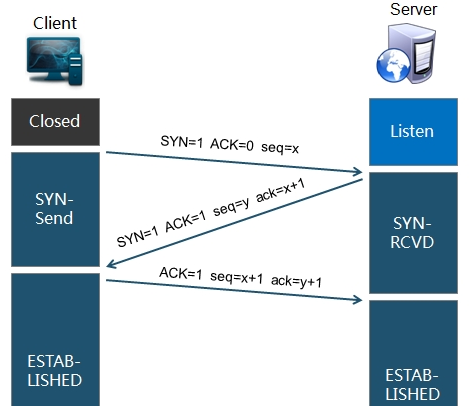
具体可以翻阅前面关于 TCP三次握手和四次挥手的博客
3.建立TCP连接之后,发起HTTP请求
HTTP请求报文由三部分组成:请求行,请求头和请求正文
请求行:用于描述客户端的请求方式,请求的资源名称以及使用的HTTP协议的版本号(例:GET/books/java.html HTTP/1.1)
请求头:用于描述客户端请求哪台主机,以及客户端的一些环境信息等
注:这里提一个请求头 Connection,Connection设置为 keep-alive用于说明 客户端这边设置的是,本次HTTP请求之后并不需要关闭TCP连接,这样可以使下次HTTP请求使用相同的TCP通道,节省TCP建立连接的时间
请求正文:当使用POST, PUT等方法时,通常需要客户端向服务器传递数据。这些数据就储存在请求正文中(GET方式是保存在url地址后面,不会放到这里)
4.服务器端响应http请求,浏览器得到html代码
HTTP响应也由三部分组成:状态码,响应头和实体内容
状态码:状态码用于表示服务器对请求的处理结果
列举几种常见的:200(没有问题) 302(要你去找别人) 304(要你去拿缓存) 307(要你去拿缓存) 403(有这个资源,但是没有访问权限) 404(服务器没有这个资源) 500(服务器这边有问题)
若干响应头:响应头用于描述服务器的基本信息,以及客户端如何处理数据
实体内容:服务器返回给客户端的数据
注:html资源文件应该不是通过 HTTP响应直接返回去的,应该是通过nginx通过io操作去拿到的吧
5.浏览器解析html代码,并请求html代码中的资源
浏览器拿到html文件后,就开始解析其中的html代码,遇到js/css/image等静态资源时,就向服务器端去请求下载(会使用多线程下载,每个浏览器的线程数不一样),这是时候就用上 keep-alive特性了,建立一次HTTP连接,可以请求多个资源,下载资源的顺序就是按照代码里面的顺序,但是由于每个资源大小不一样,而浏览器又是多线程请求请求资源,所以这里显示的顺序并不一定是代码里面的顺序。
6.浏览器对页面进行渲染呈现给用户
最后,浏览器利用自己内部的工作机制,把请求的静态资源和html代码进行渲染,渲染之后呈现给用户
浏览器是一个边解析边渲染的过程。首先浏览器解析HTML文件构建DOM树,然后解析CSS文件构建渲染树,等到渲染树构建完成后,浏览器开始布局渲染树并将其绘制到屏幕上。这个过程比较复杂,涉及到两个概念: reflow(回流)和repain(重绘)。DOM节点中的各个元素都是以盒模型的形式存在,这些都需要浏览器去计算其位置和大小等,这个过程称为relow;当盒模型的位置,大小以及其他属性,如颜色,字体,等确定下来之后,浏览器便开始绘制内容,这个过程称为repain。页面在首次加载时必然会经历reflow和repain。reflow和repain过程是非常消耗性能的,尤其是在移动设备上,它会破坏用户体验,有时会造成页面卡顿。所以我们应该尽可能少的减少reflow和repain。
JS的解析是由浏览器中的JS解析引擎完成的。JS是单线程运行,JS有可能修改DOM结构,意味着JS执行完成前,后续所有资源的下载是没有必要的,所以JS是单线程,会阻塞后续资源下载
自此一次完整的HTTP事务宣告完成.
总结:
域名解析-------> 发起TCP的3次握手-------> 建立TCP连接后发起http请求-------> 服务器响应http请求,浏览器得到html代码-------> 浏览器解析html代码,并请求html代码中的资源(如js、css、图片等)-------> 浏览器对页面进行渲染呈现给用户