1.本周学习总结(0--2分)
1.1思维导图
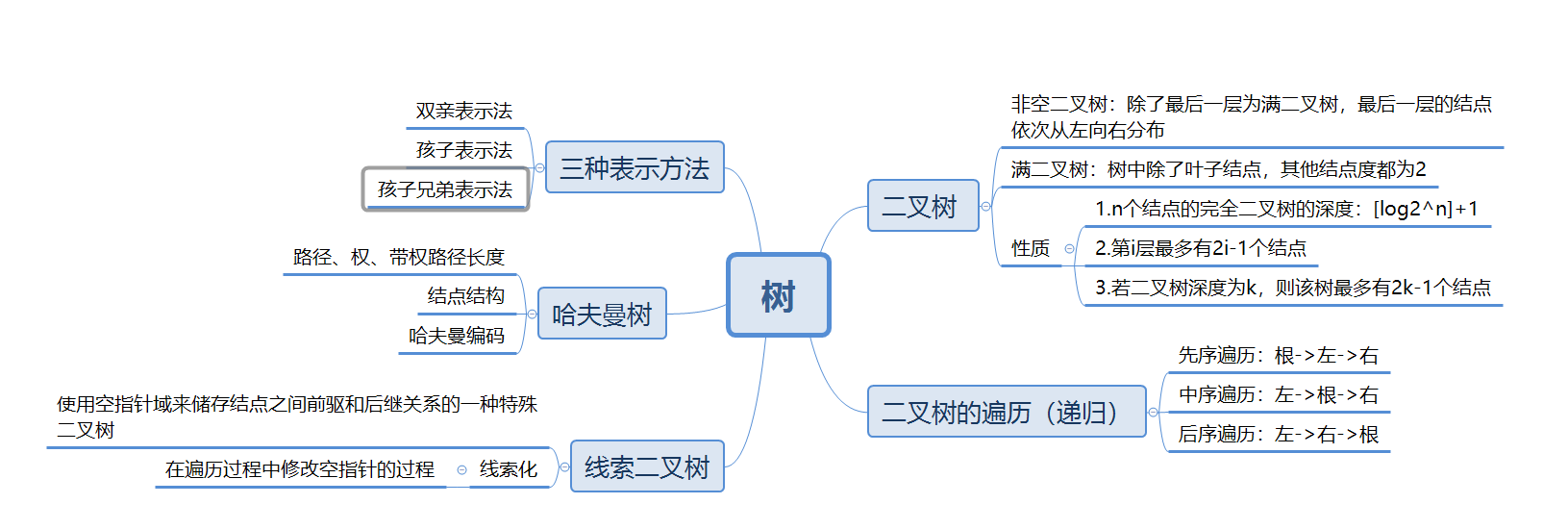
1.2谈谈你对树结构的认识及学习体会
树是数据结构中比较重要也是比较难理解的一类存储结构,它是由n(n>=1)个有限节点组成一个具有层次关系的集合。
①单个结点是一棵树,树根就是该结点本身。
②如果一个结点P的所有子节点都是子树的根,那P也是一个根。
③空集也是树,称为空树。空树中没有结点。
树有多种类型,可分为二叉树和哈夫曼树等,其中二叉树又可分为完全二叉树和满二叉树。
树的应用很广,树在文件系统、编译器、索引以及查找算法中都有应用。
在学习中遇到的困难:简单的建立一棵树不会用代码表达出来。
在树中需用到递归的思想,但我还没掌握递归的内容。
2.PTA实验作业(6分)
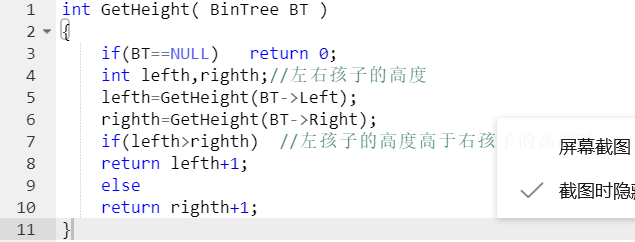
2.1.题目1:求 二叉树的高度
2.1.1设计思路(伪代码)
.比较一棵树的左右子树的高度,高的子树+1即该二叉树的高度
int GetHeight( BinTree BT ) //求二叉树高度的函数
.if(树空) 返回0
.分别计算左右子树的高度(递归调用求高度的函数)
.if(左子树高度>右子树高度) 返回 左子树高度+1
.否则 返回 右子树高度+1
2.1.2代码截图(注意,截图,截图,截图。不要粘贴博客上。)
2.1.3本题PTA提交列表说明

1.编译错误:Lelf和Right的大小写混乱
2.段错误:在判断BT是否为空时,写成了if(BT=NULL),少了一个“=”号
2.2.题目2:二叉树叶子结点带权路径长度和
2.2.1设计思路(伪代码)
.本题有两个函数,建树函数和求带权路径长的函数。
建树函数:
.判断从主函数传过来的i是否大于字符串长度,若大于或者str[i]=“#”都返回NULL。
.否则,把str[i]的值赋给bt->data
.再递归调用该函数本身得到结点的左孩子和右孩子。
求带权路径长的函数:
.如果结点的左孩子和右孩子都为空,说明这个结点是叶子结点。
.该叶子结点的带权路径长度等于该结点值*其路径长度
.递归调用该函数本身算出每个左右叶子结点的带权路径长度
2.2.2代码截图(注意,截图,截图,截图。不要粘贴博客上。)


2.2.3本题PTA提交列表说明。


.在递归调用建树函数得到左右孩子结点时,左右孩子和i的关系搞反了,写成bt->left = CreateBtree(str,2*i+1)
.建树时没有考虑i>字符串长度的情况
2.3.题目3:根据后序和中序遍历输出先序遍历
2.3.1设计思路(伪代码)
本题主要有建树函数和输出结点两个函数
.建树函数:
在主函数中定义两个整型数组分别存放后序遍历和中序遍历的结点的数值,再传参到建树函数中
.用一个for循环遍历中序数组中的数据,如果中序数组中某一个值与后序数组的最后一个值相等,则停止循环。
.根据给定的一棵二叉树的后序遍历和中序遍历结果,递归调用该函数得到这棵树的每个结点,最后得到一棵树。
输出结点函数:
递归,先输出左孩子再输出右孩子(没什么好讲的)
2.3.2代码截图(注意,截图,截图,截图。不要粘贴博客上。)



2.3.3本题PTA提交列表说明。

.输出格式忘记控制前面的空格。
.在输出结点的函数中,先输出了右结点再输出左结点,顺序不对
.建树函数中,在for循环里,没有控制好下标导致超出界限
3、阅读代码(-2--2分)
找一份和树相关代码,谈谈你对这个代码认识体会。
考研题种关于树内容。
ACM、PTA天梯赛、leecode面试刷题网站,找树相关题目阅读分析。
请按照下面内容填写代码阅读内容。请未必认真完成,如果发现应付,没有介绍代码思路、体会等扣分。
3.1 题目:To Add or Not to Add (添加或不添加)
题目意思:
给定一个数组,每次可以给任意元素加1,这样的操作不能超过k次,求操作不超过k次后数组中一个数能够出现的最多次数,以及能够以这个次数出现的最小的数。
3.2 解题思路
分析:这个题目明显具有单调性,这样的话就可以进行二分搜索求取最大次数了。怎么判断假定的解是否可行呢?既然只能是加1,而且又不超过k次,那么首先将数组排序,假设搜索的次数为m,那么i从第m个数循环到最后一个数,只要满足了次数不小于k就立即退出循环,这样找到的便一定是出现m次的最小的数,但是这个判断的过程就是第m个数与其之前的m-1个数的差之和要不大于k,如果每次都直接加上差进行判断必定超时,因为二分搜索加循环判断的时间复杂度太高,那么最好的优化就是直接之前预处理,求出第1个数到第m个数区间的和,后面判断的时候直接就是o(1)计算区间的和了。
3.3 代码截图


3.4 学习体会
.这段代码中用了const定义常量,const修饰一个变量时,一定要给这个变量初始化,若不初始化,在后面也不能初始化。
这是我在之前的学习中没有用过的定义方法。其中const的优点有:可以很方便的进行参数的修改和调整,同时避免意义模糊的数字出现。
.这段代码的实现用了预处理,减少重复的计算从而减少时间复杂度,使得算法性能显著提高。