作业要求:https://edu.cnblogs.com/campus/nenu/SWE2017FALL/homework/922
代码地址:https://coding.net/u/a284617374/p/soft/git (功能一、二、三是wf123.cpp 功能四(4-1)是wf41.cpp 功能(4-2)是wf.cpp)
[总结:对于统计单词出现的次数,我的想法是把文本内容看成一个个字符串,通过读取字符串,建立一个二叉树,建立二叉树的过程就是在进行单词频率统计工作,最后遍历一次二叉树就可以得到文本出现的所有单词,把单词和词频放入二维数组中。但是我的代码最终没能运行成功,没有实现作业要求的功能。]
上述段落复制于我上个版本的博客,在这个版本中,我加了快速排序方法,目的是在结果显示出前10个单词的词频。我成功的实现了功能一、二、四(4-1)和四(4-2)。对于功能三,我的第二条数据有问题,每条都是重复的,还没找到原因。我询问了冉华同学(我推测,虽然你把根结点删除了,但是和子结点存在关系。你第二次使用时,仍使用了这些子结点。你的问题估计就是在每次存数据前,将之前数据清空没弄好。),他很耐心的帮助我找出原因,但是我没有成功,问题在于我。做这些功能我用了挺长时间,每天都在进步。
- 功能一
重点:读取文件
使用方法:
FILE *fp; scanf("%49s", filename); getchar(); if ((fp = fopen(filename, "r")) == NULL) printf("文件打开失败");*/ fp = fopen(filename, "r");
难点:把文本内容作为构建二叉树的数据。
使用方法:
c = fgetc(fp);
ungetc(c, fp);
把字符一个个退回到文件流(fp)中,在记录字符串数量的同时把大写字母转成小写字母。做第一部分主要是对结构体的运用,实现自己定义的函数。
运行结果截图:

- 功能二
重点:字符串拼接
使用方法:
strcat(filename, ".txt");
运行结果截图:

- 功能三
重点1:遍历文件夹下的文件
使用方法:
#include<io.h> #include<direct.h> struct _finddata_t find; int fnum = 0; long file; _chdir("start C:\Users\小熊猫yeah\source\repos\wf\Debug\folder"); if ((file = _findfirst("*.txt", &find)) == -1) return -1; else do { printf("%s ", find.name); } while (_findnext(file, &find) == 0);
_chdir规定需被遍历的文件的地址,使用_finddata_t的基本流程:findfirst->_findnext->findclose,函数调用如果成功就返回0,否则返回-1。
结构体 _finddata_t的详细内容可以参见:http://blog.csdn.net/tianxiawuzhei/article/details/43052347
重点2:快速排序投出前10个单词的词频
使用方法:
qsort(list, n + 1, sizeof(list[0]), cmp); for (k = 0; k<n-1; k++) { wordnum = list[k].num; total = total + list[k].num; } printf("total %d ", total); //打印前十个 for (k = 0; k<10; k++) { printf("%-15s %10d ", list[k].w, list[k].num); total = total + list[k].num; }
难点:清空缓冲区,清空树。(我这点有问题,目前还没看出来问题出在哪里)
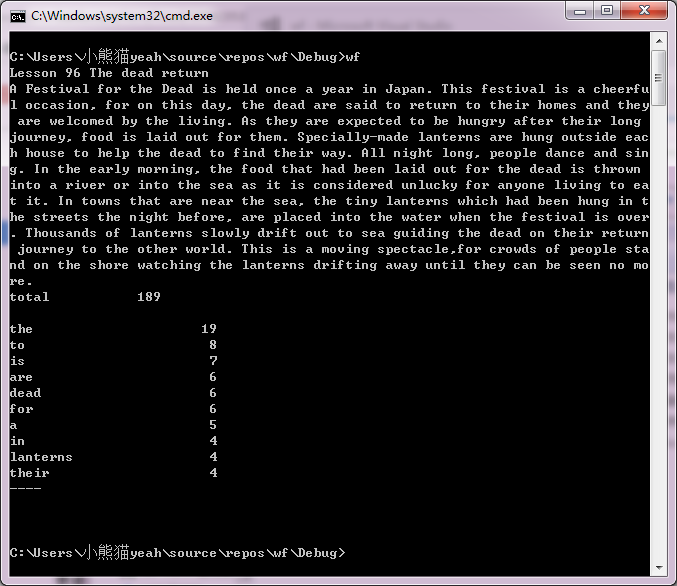
运行结果截图:

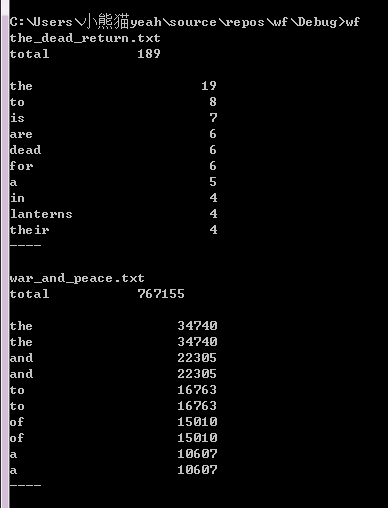
- 功能四
难点:文件名由重定向输入
对于4-1,这个折磨我几个小时,我陷入了一个坑,我一直在纠结怎么用C程序读取文件名,试了freopen,但它必须有文件名或文件具体路径。介于4-2的方法,我选择一直在用argv[1],argv可以读控制台内容,argv[2]读参后返回的结果是<null>,我以为是因为整型的argc不能读出重定向字符<,所以在控制台里可以执行wf the_dead_return.txt,不能执行wf -s < the_dead_return.txt。我想的解决办法是遇到null就continue跳过<,但是没有成功,我也查了shell怎么跟C的输入输出流对接,都没有我想要的结果。后来高远博同学告诉我<是系统读入的,再看到下面这两句代码(也是我的使用方法)也就明白了含义,真是恍然大悟,我就把原来的freopen删掉,把输入流删掉,fgetc(fp)换成了getchar,实现这个功能之后发现这个这么简单,真的是往前走一小步就会成功。
使用方法:
while( getchar() != EOF) { putchar(); }
运行结果截图(4-1):

使用方法(4-2):
fp = fopen("C:\Users\小熊猫yeah\source\repos\wf\Debug\the_dead_return.txt", "r"); char buf[1000] = { 0 }; //buffer预清空,否则结尾有出乱码的可能 fread(buf, sizeof(buf), 1, fp);
从文件流中读出字符串并打印到屏幕。
难点:重定向标准输入
使用方法:
fp = fopen(argv[], "r");
argv用于命令行编译程序,argv[0]为程序名wf。
运行结果截图(4-2):