最近做的爬取比较多,查看网上的代码很多都用到了scrapy框架。下面是一个简单的scrapy爬取实例(环境为python3.8+pycharm):
(1)右击项目目录->open in terminal输入下面代码创建Scapy初始化项目:
scrapy startproject qsbk
(2)建立一个爬虫,爬虫的名称为qsbk_spider,爬虫要爬取的网站范围为"http://www.lovehhy.net"
scrapy genspider qsbk_spider "http://www.lovehhy.net"
(3)配置settings文件:
BOT_NAME = 'qsbk' SPIDER_MODULES = ['qsbk.spiders'] NEWSPIDER_MODULE = 'qsbk.spiders' # Obey robots.txt rules ROBOTSTXT_OBEY = False # Override the default request headers: DEFAULT_REQUEST_HEADERS = { 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', 'Accept-Language': 'en', 'User Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36' } #项目中只要是需要pipelines操作的,此注释就需要打开 ITEM_PIPELINES = { 'qsbk.pipelines.QsbkPipeline': 300, }
(4)items配置,这里的items与javaweb中的javabean用法类似,就像是一个类,里面可以自定义需要爬取的字段的名称
import scrapy class QsbkItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() title = scrapy.Field() time = scrapy.Field()
(5)编写爬虫的代码:
爬虫代码中的parse作用是产生item,传给pipelines来对数据进行储存
import scrapy from qsbk.items import QsbkItem class QsbkSpiderSpider(scrapy.Spider): name = 'qsbk_spider' start_urls = ['http://www.lovehhy.net/Joke/Detail/QSBK/1'] baseUrl = "http://www.lovehhy.net" def parse(self, response): node_title_list = response.xpath("//div[@class='post_recommend_new']/h3/a/text()").extract()
node_time_list = response.xpath("//div[@class='post_recommend_new']/div[@class='post_recommend_time']/text()").extract()
items = [] for i in range(len(node_title_list)): item = QsbkItem() title = node_title_list[i] content = node_time_list[i]
item = QsbkItem(title=title, time=time) yield item
(6)编写pipelines代码对数据进行储存:
这里储存到了csv数据集文件中
import csv class ScPipeline(object): def __init__(self): self.file = open("mmm.csv", 'w+', newline="", encoding='utf-8') self.writer = csv.writer(self.file) def open_spider(self, spider): print("爬虫开始了...") def process_item(self, item, spider): self.writer.writerow([item['title'], item['time']]) return item def close_spider(self, spider): self.file.close() print("爬虫结束了...")
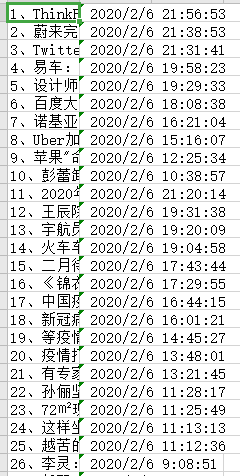
最后看一下我们爬取的结果:
还是在命令行中输入下面内容来启动爬虫
scrapy crawl qsbk_spider
爬取结果: