一、实验目的
(1)通过实验掌握 Spark SQL 的基本编程方法;
(2)熟悉 RDD 到 DataFrame 的转化方法;
(3)熟悉利用 Spark SQL 管理来自不同数据源的数据。
二、实验平台
操作系统: Ubuntu16.04
Spark 版本:2.1.0
数据库:MySQL
三、实验内容和要求
1.Spark SQL 基本操作
将下列 JSON 格式数据复制到 Linux 系统中,并保存命名为 employee.json。
{ "id":1 , "name":" Ella" , "age":36 }
{ "id":2, "name":"Bob","age":29 }
{ "id":3 , "name":"Jack","age":29 }
{ "id":4 , "name":"Jim","age":28 }
{ "id":4 , "name":"Jim","age":28 }
{ "id":5 , "name":"Damon" }
{ "id":5 , "name":"Damon" }
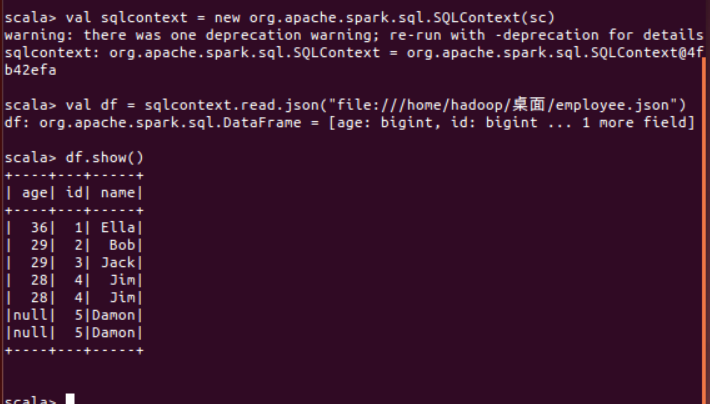
为 employee.json 创建 DataFrame,并写出 Scala 语句完成下列操作:
val sqlcontext = new org.apache.spark.sql.SQLContext(sc)
val df = sqlcontext.read.json("file:///home/hadoop/桌面/employee.json")
(2) 查询所有数据,并去除重复的数据;
df.distinct().show()

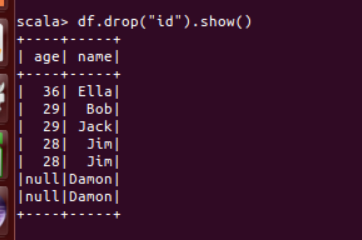
(3) 查询所有数据,打印时去除 id 字段;
df.drop("id").show()
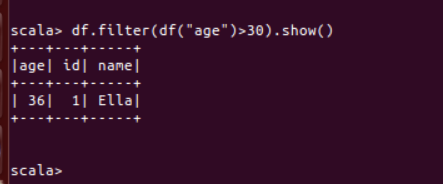
(4) 筛选出 age>30 的记录;
df.filter(df("age")>30).show()
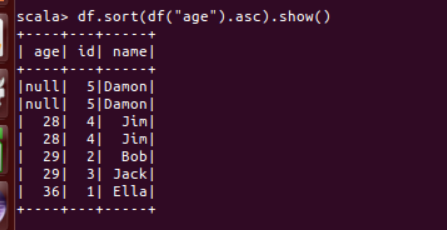
(5) 将数据按 age 分组;
df.sort(df("age").asc).show()
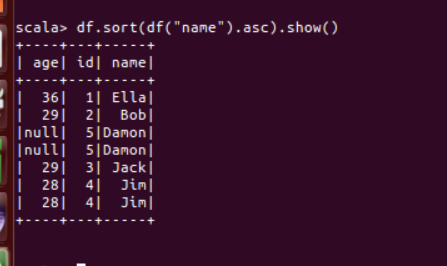
(6) 将数据按 name 升序排列;
df.sort(df("name").asc).show()
(7) 取出前 3 行数据;
df.take(3)或df.head(3)

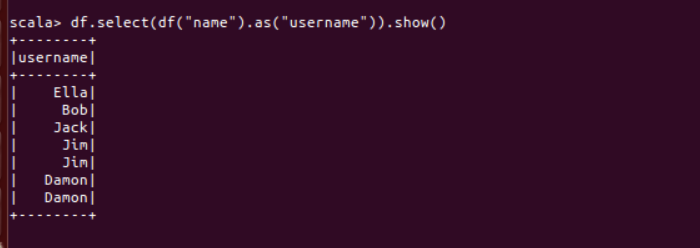
(8) 查询所有记录的 name 列,并为其取别名为 username;
df.select(df("name").as("username")).show()
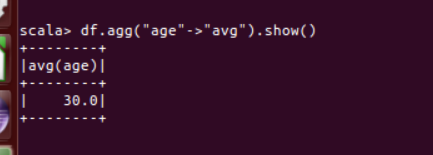
(9) 查询年龄 age 的平均值;
df.agg("age"->"avg").show()
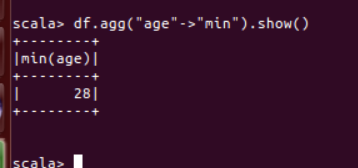
(10) 查询年龄 age 的最小值。
df.agg("age"->"min").show()
2.编程实现将 RDD 转换为 DataFrame
源文件内容如下(包含 id,name,age):
1,Ella,36
2,Bob,29
3,Jack,29
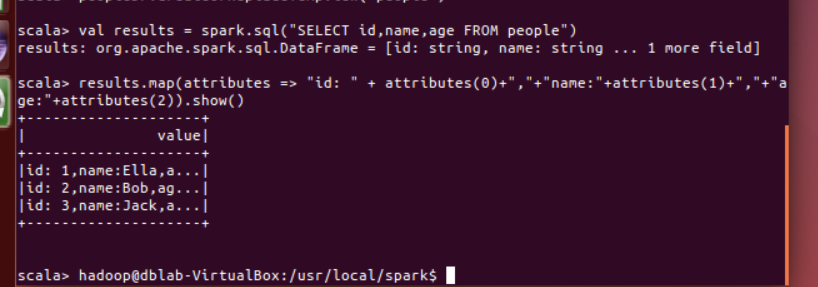
请将数据复制保存到 Linux 系统中,命名为 employee.txt,实现从 RDD 转换得到DataFrame,并按“id:1,name:Ella,age:36”的格式打印出 DataFrame 的所有数据。请写出程序代码。
scala> import org.apache.spark.sql.types._ import org.apache.spark.sql.types._ scala> import org.apache.spark.sql.Row import org.apache.spark.sql.Row scala> val peopleRDD = spark.sparkContext.textFile("file:///home/hadoop/桌面/employee.txt") peopleRDD: org.apache.spark.rdd.RDD[String] = file:///home/hadoop/桌面/employee.txt MapPartitionsRDD[55] at textFile at <console>:32 scala> val schemaString = "id name age" schemaString: String = id name age scala> val fields = schemaString.split(" ").map(fieldName => StructField(fieldName, StringType, nullable = true)) fields: Array[org.apache.spark.sql.types.StructField] = Array(StructField(id,StringType,true), StructField(name,StringType,true), StructField(age,StringType,true)) scala> val schema = StructType(fields) schema: org.apache.spark.sql.types.StructType = StructType(StructField(id,StringType,true), StructField(name,StringType,true), StructField(age,StringType,true)) scala> val rowRDD = peopleRDD.map(_.split(",")).map(attributes => Row(attributes(0), attributes(1).trim, attributes(2).trim)) rowRDD: org.apache.spark.rdd.RDD[org.apache.spark.sql.Row] = MapPartitionsRDD[57] at map at <console>:34 scala> val peopleDF = spark.createDataFrame(rowRDD, schema) peopleDF: org.apache.spark.sql.DataFrame = [id: string, name: string ... 1 more field] scala> peopleDF.createOrReplaceTempView("people") scala> val results = spark.sql("SELECT id,name,age FROM people") results: org.apache.spark.sql.DataFrame = [id: string, name: string ... 1 more field] scala> results.map(attributes => "id: " + attributes(0)+","+"name:"+attributes(1)+","+"age:"+attributes(2)).show() +--------------------+ | value| +--------------------+ |id: 1,name:Ella,a...| |id: 2,name:Bob,ag...| |id: 3,name:Jack,a...| +--------------------+
3. 编程实现利用 DataFrame 读写 MySQL 的数据
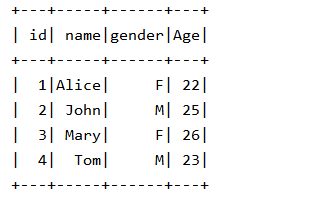
(1)在 MySQL 数据库中新建数据库 sparktest,再创建表 employee,包含如表 6-2 所示的两行数据。


(2)配置 Spark 通过 JDBC 连接数据库 MySQL,编程实现利用 DataFrame 插入如表 6-3 所示的两行数据到 MySQL 中,最后打印出 age 的最大值和 age 的总和。

实验代码:
import java.util.Properties import com.sun.org.apache.xalan.internal.xsltc.compiler.util.IntType import org.apache.spark.sql.types._ import org.apache.spark.sql.{Row, SparkSession} object exercise03 { val spark: SparkSession = SparkSession.builder().getOrCreate() def main(args: Array[String]): Unit = { val jdbcDF = spark.read.format("jdbc").option("url", "jdbc:mysql://localhost:3306/sparktest?serverTimezone=UTC") .option("driver", "com.mysql.cj.jdbc.Driver").option("dbtable", "employee") .option("user", "root").option("password", "root").load() jdbcDF.show() val studentRDD=spark.sparkContext.parallelize(Array("3 Mary F 26","4 Tom M 23")) .map(x=>x.split(" ")) val ROWRDD=studentRDD.map(x=>Row(x(0).toInt,x(1).trim,x(2).trim,x(3).toInt)) ROWRDD.foreach(print) //设置模式信息 val schema=StructType(List(StructField("id",IntegerType,true),StructField("name",StringType,true),StructField("gender",StringType,true),StructField("age", IntegerType, true))) val studentDF=spark.createDataFrame(ROWRDD,schema) val parameter=new Properties() parameter.put("user","root") parameter.put("password","root") parameter.put("driver","com.mysql.cj.jdbc.Driver") studentDF.write.mode("append").jdbc("jdbc:mysql://localhost:3306/sparktest?serverTimezone=UTC","employee",parameter) jdbcDF.show() } }