应用领域全面突破:图像识别
-
图像识别近年来取得重大突破,主要突破点在深度学习和卷积神经网络,成绩的大幅度提升几乎都伴随着卷积神经网络的层数加深。
-
(Google)神经机器翻译系统在多种语言间的翻译性能取得大幅提升,接近人类的翻译水平
-
在语音识别领域极具挑战性的(SwitchBord)任务中
-
(GMM-HMM)传统方法一直未有突破
-
(2011)年使用(DNN)后获得较大突破
-
(2015)年,(IBM)再次将错误率降低到(6.9\%),接近人类的平均水平((4\%))
-
借助深度学习和强化学习,谷歌的(DeepMind)团队已开发出能够自我学习玩游戏的系统,且不需要人工干预
-
在(49)种(Atari)视频游戏中,(23)种击败了人类职业玩家
-
(2017)年(8)月(10)日,(DeepMind)宣布开源星际争霸(2)研究训练平台(SC2LE)
深度学习获得发展的原因
- 大规模高质量标注数据集的出现
- 并行运算(例如(GPU))的发展
- 更好的非线性激活函数的使用:(ReLU)代替(Logistic)
- 更多优秀的网络结构的发明:(ResNet、GgooleNet)和(AlexNet)等
- 深度学习开发平台的发展:(TensorFlow、PyTorch)和(MXNet)等
- 新的正则化技术的出现:批标准化、(Dropout)等
- 更多稳健的优化算法:(SGD)的变种:如(RMSprop、Adam)等
多层感知机((MLP))
- 多个神经元以全连接层次相连
- 这种网络称为前馈神经网络
- 也称为多层感知机((MLP))
- 万能逼近原理:((MLP))能够逼近任何函数
(MLP)的困境
- 目标函数通常为非凸函数
- 极容易陷入局部最优值
- 网络层数增多后,梯度消失或梯度爆炸问题
非线性函数逼近
- 深度学习通过一种深层网络结构,实现复杂函数逼近
- 万能逼近原理:当隐层节点数目足够多时,具有一个隐层的神经网络可以以任意精度逼近任意具有有限间断点的函数
- 网络层数越多,需要的隐含节点数目指数减小
典型网络结构
- 卷积神经网络((VGG/GoogleNet/AlexNet/ResNet))
- 循环神经网络((RNN))
- 自编码器((Autoencoder))
- 生成对抗网络((GAN))
卷积神经网络((CNN))
- 适合处理网格型数据
- 在计算机视觉领域获得巨大成功:物体识别,图片分类,2维网格
- 全连接网络并不适用于图像
- 像素大:参数爆炸
- 图像大小:(1000*1000),第一层复杂度(O(1,000,000))
- (CNN):卷积
- 稀疏连接;参数共享;等变表示
(AlexNet)
- 数据增强
- 通过水平翻转、随机裁剪、平移变换和颜色光照变换得到更多训练集
- (Dropout)
- 创建的防止过度拟合方法:按照一定概率将神经元暂时从网络中丢弃
- (ReLU)激活函数
- (ReLU(x)=max(0,x))不容易发生梯度爆炸问题,求解简单
- (Local\,\,Response\,\,Normalization)
- 利用临近的数据做归一化
(GAN)
- (Yann\,\,LeCun)曾评价(GAN)是“20年来机器学习领域最酷的想法”
- 利用深度网络生成数据
- (D)为判别网络
- (G)为生成网络
自然语言处理
- 使用向量来表示词、句子、文档和语义
- 机器翻译
- 情感分析
- 问答系统
案例:
Olivetti Faces 是由纽约大学整理的一个人脸数据集。原始数据库可从(http://www.cl.cam.ac.uk/research/dtg/attarchive/facedatabase.html)。 我们使用的是 Sklearn 提供的版本。该版本是纽约大学 Sam Roweis 的个人主页以 MATLAB 格式提供的。
数据集包括 40 个不同的对象,每个对象都有 10 个不同的人脸图像。对于某些对象,图像是在不同的时间、光线、面部表情(睁眼/闭眼、微笑/不微笑)和面部细节(眼镜/不戴眼镜)下拍摄。所有的图像都是在一个深色均匀的背景下拍摄的,被摄者处于直立的正面位置(可能有细微面部移动)。原始数据集图像大小为 (92 imes 112),而 Roweis 版本图像大小为 (64 imes 64)。
from sklearn.datasets import fetch_olivetti_faces
faces = fetch_olivetti_faces()
print (faces)
观察发现,该数据集包括四部分:
1)DESCR 主要介绍了数据的来源;
2)data 以一维向量的形式存储了数据集中的400张图像;
3)images 以二维矩阵的形式存储了数据集中的400张图像;
4)target 存储了数据集中400张图像的类别信息,类别分别为 0-39 。
print("The shape of data:",faces.data.shape, "The data type of data:",type(faces.data))
print("The shape of images:",faces.images.shape, "The data type of images:",type(faces.images))
print("The shape of target:",faces.target.shape, "The data type of target:",type(faces.target))

可见,数据都以 numpy.ndarray 形式存储。因为下一步我们希望搭建卷积神经网络来实现人脸识别,所以特征要用二维矩阵存储的图像,这样可以充分挖掘图像的结构信息。
随机选取部分人脸,使用 matshow 函数将其可视化。
from sklearn.datasets import fetch_olivetti_faces
faces = fetch_olivetti_faces()
# print (faces)
# print("The shape of data:",faces.data.shape, "The data type of data:",type(faces.data))
# print("The shape of images:",faces.images.shape, "The data type of images:",type(faces.images))
# print("The shape of target:",faces.target.shape, "The data type of target:",type(faces.target))
import numpy as np
rndperm = np.random.permutation(len(faces.images)) #将数据的索引随机打乱
import matplotlib.pyplot as plt
plt.gray()
fig = plt.figure(figsize=(9,4) )
for i in range(0,18):
ax = fig.add_subplot(3,6,i+1 )
plt.title(str(faces.target[rndperm[i]]))
ax.matshow(faces.images[rndperm[i],:])
plt.box(False) #去掉边框
plt.axis("off")#不显示坐标轴
plt.tight_layout()
plt.show()

# 查看同一个人的不同人脸的特点。
labels = [2,11,6] #选取三个人
# %matplotlib inline
plt.gray()
fig = plt.figure(figsize=(12,4) )
for i in range(0,3):
faces_labeli = faces.images[faces.target == labels[i]]
for j in range(0,10):
ax = fig.add_subplot(3,10,10*i + j+1 )
ax.matshow(faces_labeli[j])
plt.box(False) #去掉边框
plt.axis("off")#不显示坐标轴
plt.tight_layout()
plt.show()

观察发现,每一个人的不同图像都存在角度、表情、光线,是否戴眼镜等区别,这种样本之间的差异性虽然提升了分类难度,但同时要求模型必须提取到人脸的高阶特征。
将数据集划分为训练集和测试集两部分,注意要按照图像标签进行分层采样。
# 定义特征和标签
X,y = faces.images,faces.target
# 以5:5比例随机地划分训练集和测试集
from sklearn.model_selection import train_test_split
train_x, test_x, train_y, test_y = train_test_split(X, y, test_size=0.5,stratify = y,random_state=0)
# 记录测试集中出现的类别,后期模型评价画混淆矩阵时需要
#index = set(test_y)
import pandas as pd
pd.Series(train_y).value_counts().sort_index().plot(kind="bar")
pd.Series(test_y).value_counts().sort_index().plot(kind="bar")
# 转换数据维度
train_x = train_x.reshape(train_x.shape[0], 64, 64, 1)
test_x = test_x.reshape(test_x.shape[0], 64, 64, 1)
import warnings
warnings.filterwarnings('ignore') #该行代码的作用是隐藏警告信息
import tensorflow as tf
import tensorflow.keras.layers as layers
import tensorflow.keras.backend as K
K.clear_session()
# 逐层搭建卷积神经网络模型。
inputs = layers.Input(shape=(64,64,1), name='inputs')
conv1 = layers.Conv2D(32,3,3,padding="same",activation="relu",name="conv1")(inputs)
maxpool1 = layers.MaxPool2D(pool_size=(2,2),name="maxpool1")(conv1)
conv2 = layers.Conv2D(64,3,3,padding="same",activation="relu",name="conv2")(maxpool1)
maxpool2 = layers.MaxPool2D(pool_size=(2,2),name="maxpool2")(conv2)
flatten1 = layers.Flatten(name="flatten1")(maxpool2)
dense1 = layers.Dense(512,activation="tanh",name="dense1")(flatten1)
dense2 = layers.Dense(40,activation="softmax",name="dense2")(dense1)
model = tf.keras.Model(inputs,dense2)
# 网络结构打印。
model.summary()
# 模型编译,指定误差函数、优化方法和评价指标。使用训练集进行模型训练。
model.compile(loss='sparse_categorical_crossentropy', optimizer="Adam", metrics=['accuracy'])
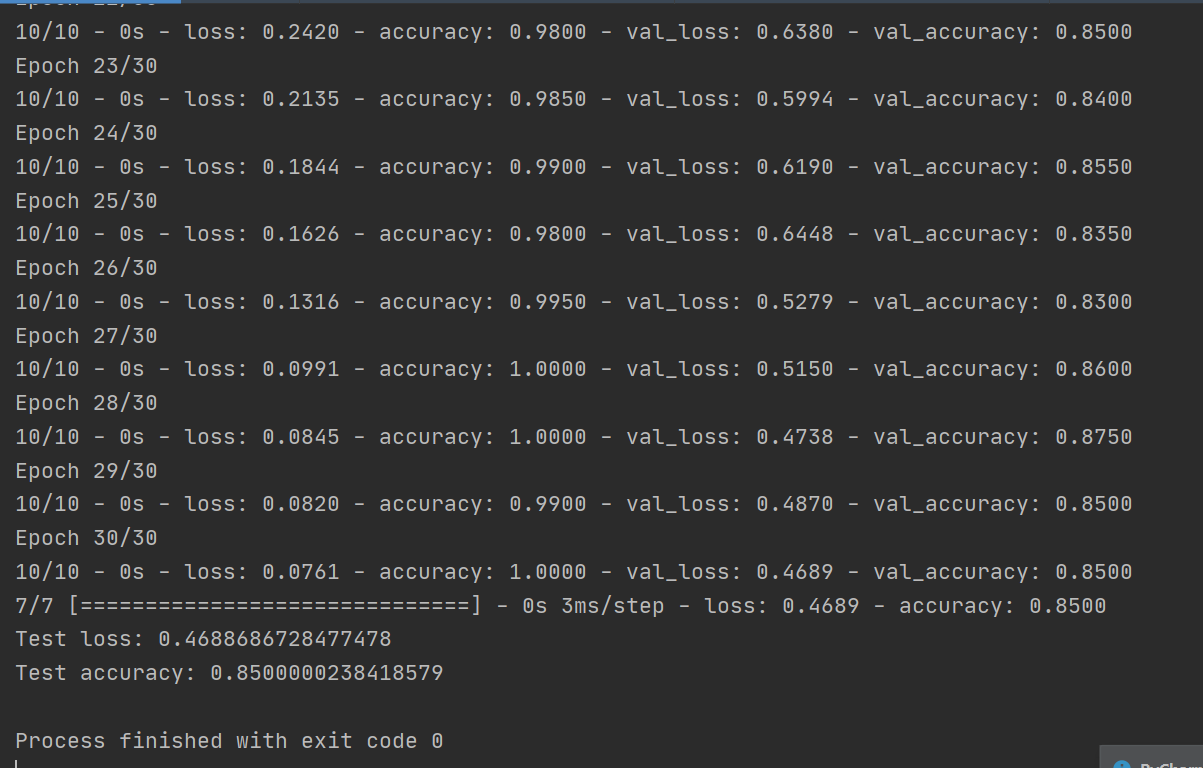
model.fit(train_x,train_y, batch_size=20, epochs=30, validation_data=(test_x,test_y),verbose=2)
# 模型评价
score = model.evaluate(test_x, test_y)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
在深度学习中,为了防止过度拟合,我们通常需要足够的数据,当无法得到充分大的数据量时,可以通过图像的几何变换来增加训练数据的量。为了充分利用有限的训练集(只有320个样本),我们将通过一系列随机变换增加训练数据。
TensorFlow 提供一个图像预处理类 ImageDataGenerator 能够帮助我们进行图像数据增强,增强的手段包括图像随机转动、水平偏移、竖直偏移、随机缩放等。
from tensorflow.keras.preprocessing.image import ImageDataGenerator
# 定义随机变换的类别及程度
datagen = ImageDataGenerator(
rotation_range=0, # 图像随机转动的角度
width_shift_range=0.01, # 图像水平偏移的幅度
height_shift_range=0.01, # 图像竖直偏移的幅度
shear_range=0.01, # 逆时针方向的剪切变换角度
zoom_range=0.01, # 随机缩放的幅度
horizontal_flip=True,
fill_mode='nearest')
# 下面我们使用增强后的数据集训练模型:
inputs = layers.Input(shape=(64,64,1), name='inputs')
conv1 = layers.Conv2D(32,3,3,padding="same",activation="relu",name="conv1")(inputs)
maxpool1 = layers.MaxPool2D(pool_size=(2,2),name="maxpool1")(conv1)
conv2 = layers.Conv2D(64,3,3,padding="same",activation="relu",name="conv2")(maxpool1)
maxpool2 = layers.MaxPool2D(pool_size=(2,2),name="maxpool2")(conv2)
flatten1 = layers.Flatten(name="flatten1")(maxpool2)
dense1 = layers.Dense(512,activation="tanh",name="dense1")(flatten1)
dense2 = layers.Dense(40,activation="softmax",name="dense2")(dense1)
model2 = tf.keras.Model(inputs,dense2)
model2.compile(loss='sparse_categorical_crossentropy', optimizer="Adam", metrics=['accuracy'])
# 训练模型
model2.fit_generator(datagen.flow(train_x, train_y, batch_size=200),epochs=30,steps_per_epoch=16, verbose = 2,validation_data=(test_x,test_y))
# 模型评价
score = model2.evaluate(test_x, test_y)
print('Test score:', score[0])
print('Test accuracy:', score[1])

可以看到,数据增强后,模型效果得到提升。
本案例我们使用一份人脸数据集,借助 TensorFlow 构建了卷积神经网络用于人脸识别,同时对比了数据增强对模型效果的影响。本案例使用的主要 Python 工具,版本和用途列举如下。如果在本地运行遇到问题,请检查是否是版本不一致导致。
| 工具包 | 版本 | 用途 |
|---|---|---|
| NumPy | 1.17.4 | 图像数据格式 |
| Pandas | 0.23.4 | 数据读取与预处理 |
| Matplotlib | 3.0.2 | 数据可视化 |
| Seaborn | 0.9.0 | 数据可视化 |
| Sklearn | 0.19.1 | 测试集训练集划分、人脸数据集加载 |
| TensorFlow | 1.12.0 | 卷积神经网络的构建与训练、数据增强 |