说明:如遇到报错没有hadoop命令,请重新执行source hadoop-env.sh。后续的实验中同理。
1、HDFS是Master和Slave的结构,分为NameNode、Secondary NameNode和DataNode三种角色。
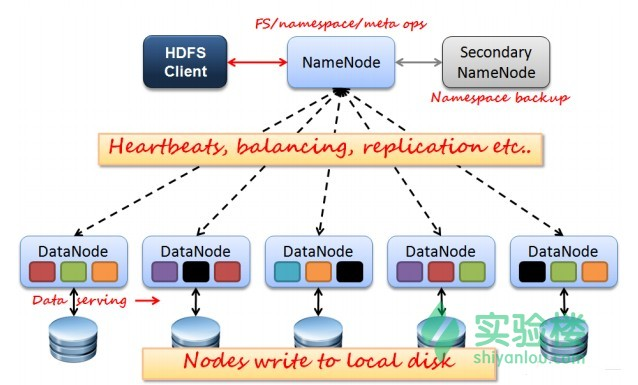
- NameNode:在Hadoop1.X中只有一个Master节点,管理HDFS的名称空间和数据块映射信息、配置副本策略和处理客户端请求;
- Secondary NameNode:辅助NameNode,分担NameNode工作,定期合并fsimage和fsedits并推送给NameNode,紧急情况下可辅助恢复NameNode;
- DataNode:Slave节点,实际存储数据、执行数据块的读写并汇报存储信息给NameNode;
2、HDFS常用命令
①. hadoop fs 将本地文件上传到hdfs,同时删除本地文件。


hadoop fs -ls / hadoop fs -lsr hadoop fs -mkdir /user/hadoop hadoop fs -put a.txt /user/hadoop/ hadoop fs -get /user/hadoop/a.txt / hadoop fs -cp src dst hadoop fs -mv src dst hadoop fs -cat /user/hadoop/a.txt hadoop fs -rm /user/hadoop/a.txt hadoop fs -rmr /user/hadoop/a.txt hadoop fs -text /user/hadoop/a.txt hadoop fs -copyFromLocal localsrc dst 与hadoop fs -put功能类似。 hadoop fs -moveFromLocal localsrc dst
② hadoop fsadmin 运行一个 HDFS 的 dfsadmin 客户端
③hadoop fsck 运行 HDFS 文件系统检查工具。
用法:hadoop fsck [GENERIC_OPTIONS] <path> [-move | -delete | -openforwrite] [-files [-blocks [-locations | -racks]]]
④启动 Hadoop
cd /app/hadoop-1.1.2/bin
./start-all.sh
3、Pig的调用方式:
- Grunt shell方式:通过交互的方式,输入命令执行任务;
- Pig script方式:通过script脚本的方式来运行任务;
- 嵌入式方式:嵌入java源代码中,通过java调用来运行任务。
4、Hive与关系数据库的区别具体如下:
①Hive和关系数据库存储文件的系统不同,Hive使用的是Hadoop的HDFS(Hadoop的分布式文件系统),关系数据库则是服务器本地的文件系统;
②Hive使用的计算模型是Mapreduce,而关系数据库则是自身的计算模型;
③关系数据库都是为实时查询的业务进行设计的,而Hive则是为海量数据做数据挖掘设计的,实时性很差;实时性的区别导致Hive的应用场景和关系数据库有很大的不同;
④Hive很容易扩展自己的存储能力和计算能力,这个是继承Hadoop的,而关系数据库在这个方面要比数据库差很多。
5、组件
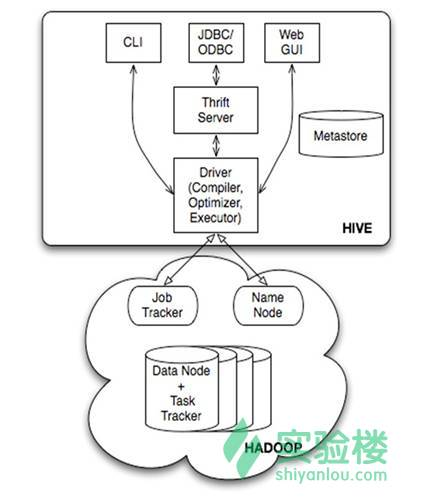
服务端组件:
- Driver组件:该组件包括Complier、Optimizer和Executor,它的作用是将HiveQL(类SQL)语句进行解析、编译优化,生成执行计划,然后调用底层的mapreduce计算框架;
- Metastore组件:元数据服务组件,这个组件存储Hive的元数据,Hive的元数据存储在关系数据库里,Hive支持的关系数据库有derby和mysql。元数据对于Hive十分重要,因此Hive支持把metastore服务独立出来,安装到远程的服务器集群里,从而解耦Hive服务和metastore服务,保证Hive运行的健壮性;
- Thrift服务:thrift是facebook开发的一个软件框架,它用来进行可扩展且跨语言的服务的开发,Hive集成了该服务,能让不同的编程语言调用hive的接口。
客户端组件:
- CLI:command line interface,命令行接口。
- Thrift客户端:上面的架构图里没有写上Thrift客户端,但是Hive架构的许多客户端接口是建立在thrift客户端之上,包括JDBC和ODBC接口。
- WEBGUI:Hive客户端提供了一种通过网页的方式访问hive所提供的服务。这个接口对应Hive的hwi组件(hive web interface),使用前要启动hwi服务。