概论
一、什么是数据库:
数据库就是存储数据的仓库,其本质是一个文件系统,数据按照特定的格式将数据存储起来,用户可以对数据库中的数据进行增加,修改,删除及查询操作。
二、MySQL数据库:
MySQL数据库. MySQL 是一种 开放源代码 的关系型 数据库管理 系统(RDBMS),使用最常用的数据库管理语言-- 结构化查询语言(SQL)进行数据库管理。MySQL是开放源代码的,因此任何人都可以在General Public License的许可下下载并根据个性化的需要对其进行修改。MySQL因为其速度、可靠性和适应性而备受关注。大多数人都认为在不需要事务化处理的情况下,MySQL是管理内容最好的选择。
三、Oracle数据库:
Oracle 数据库产品为客户提供成本优化的高性能版 Oracle 数据库、全球领先的融合多模型数据库管理系统以及 In-memory、NoSQL 和 MySQL 数据库。客户可以在本地部署环境中通过 Oracle 公有云本地化解决方案使用 Oracle 自治数据库,也可以在 Oracle 云基础设施中使用 Oracle 自治数据库,从而简化关系数据库环境并减少管理工作量。
四、MySQL和Oracle的区别:
①Oracle是大型的数据库而Mysql是中小型数据库;
②Oracle支持大并发,大访问量;
③安装占用的内存也是有差别,Mysql安装完成之后占用的内存远远小于Oracle所占用的内存,并且Oracle越用所占内存也会变多;
④Mysql是开源的,Oracle是收费的,且价格昂贵。
五、什么是字符集
在计算机底层,比如说你的名字“小萌”在计算机中并不是文字的形式,而是一串二进制数字,如“011001100110…”人类只认识文字,可惜计算机只认0和1,双方都不能妥协,那就必须要有一个从文字到0、1的映射了。从我们可以看到的文字到0、1的映射称为编码,反过来从0、1到文字叫解码。ASCII、UTF-8这些就是字符集,字符集就是字符的集合。
六、UTF-8
U:因为计算机是美国人发明的所以一开始只支持英文字符,不支持中文、韩文、日文等字符,所以为了统一世界上大多数人的字符,比如中文的GB2312,Unicode应运而生。
UTF:Unicode Transformation Formats(Unicode转换格式)。
UNF-8:这个“Unicode转换格式”是为了解决“码点”在计算机存储方式而设计的。“码点”经过映射后得到的二进制串的转换格式单位称之为“码元”(Code Unit)。“码点”就是一串二进制数,“码元”就是切分这个二进制数的方法。举个例子,如果有一个字符的码点二进制表示有n字节(n*8个二进制数),其码元为8位(1个字节),那么其拥有码元n个。字节也叫比特(Byte),8bit(位)=1Byte(字节),1024Byte(字节)=1KB,1024KB=1MB,一个字节等于8位二进制,储存一个英文字母和阿拉伯数字=2字节,储存一个汉字=2字节。
七、排序规则:
排序规则:是指对指定字符集下不同字符的比较规则。其特征有以下几点:
①两个不同的字符集不能有相同的排序规则。
②两个字符集有一个默认的排序规则。
③有一些常用的命名规则。如_ci结尾表示大小写不敏感(caseinsensitive),_cs表示大小写敏感(case sensitive),_bin表示二进制的比较(binary)。
八、utf-8默认的排序规则:
①utf8_general_ci 不区分大小写,这个你在注册用户名和邮箱的时候就要使用;
②utf8_general_cs 区分大小写,如果用户名和邮箱用这个就会照成不良后果;
③utf8_bin:字符串每个字符串用二进制数据编译存储。区分大小写,而且可以存二进制的内容;
④utf8_general_ci校对速度快,但准确度稍差;
⑤utf8_unicode_ci准确度高,但校对速度稍慢。
建库表
一、数据库
1.创建数据库
语法格式:create database 数据库名
举例:建立一个叫Staff的数据库
create database Staff
2.显示数据库
语法格式:show databases like '%数据库名%'
举例:显示Staff数据库
show databases like '%Staff%'
3.删除数据库
语法格式:drop database 数据库名
举例:删除已创建的Staff数据库
drop database Staff
二、表格
1.创建表格
语法格式:create table 表名(列名1 数据类型和长度 约束条件,列名2 数据类型和长度 约束条件......)charset='utf-8;
create table test_data (Number int(255) auto_increment primary key not null , Sname varchar(255) not null,Sjob varchar(255) default null ,Sentry_date date default null,Scentre varchar(255) default null,Sdepartment varchar(255) default null,Ssalary int(255) default null,Sbonus int(255) default null,Seducation varchar(255) default null)engine=innodb DEFAULT charset=utf8;

补充:
①主键约束(primary key):数据唯一,且不为空。(数据唯一:同一列不能重复)
创建表时直接添加在值后加约束
单一约束:create table 表名( 列名1 列值1 primary key,...);
联合约束:create table 表名(列名1 列值1, 列名2 列值2, .... 列名n 列值n, primary key(列名1,列名2); )
创建表后,补充约束alter table 表名 add primary key(列名1);
删除约束:alter table 表名 drop primary key;
②非空约束:not null。
alter table 表名 modify 字段名 字段类型 not null;
③默认值约束:default。
添加约束:create table 表名( 列名1 列值1 约束,列名2 列值2 约束 default 默认值, .... )
alter table 表名 alter 列名 set default 默认值;
④唯一约束(unique):数据唯一,可以为null。
添加约束:create table 表名( 列名1 列值1 约束条件,列名2 列值2 unique, ....)
后期追加: alter table 表名 add unique(列名);
⑤自动增长(auto_increment(MySQL),identity(SQLServer),sequence(oracle)):数据必须为整型和主键,被删除行不影响后续自增数。
2.显示表
show tables like '%表名%';--显示已创建的表
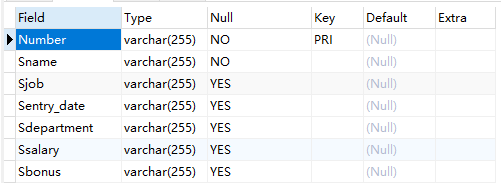
desc 表名;--显示表的结构
Tybe:字段表示的是列的数据类型
Null:字段表示这个列是否为空值
key:可能看到PRI(主键)、MUL(普通的b-tree索引)、UNI(唯一索引)
Default:列的默认值
Extra:其他信息
3.修改表
rename table 旧表名 to 新表名
4.删除表
drop table 表名
5.清空表数据:
truncate 表名
三、列(字段)
1.修改列名:
语法格式:alter table 表名 change 列名 新列名 数据类型
举例:将test_data表格的Sjob列名修改为job
alter table test_data change Sjob job varchar(255)
2.删除列:
语法格式:alter table 表名 drop column 列名
举例:删除test_data表格的Sjob列
alter table test_data drop column Sjob
3.增加列:
语法格式:alter table 表名 add 列名 数据类型
举例:在test_data表格里面增加一列Sjob
alter table test_data add Sjob varchar(255)
补充:alter是数据操纵,中文解释为改变
四、补充知识:
MySQL中默认添加了一个名为 information_schema 的数据库,该数据库中的表都是只读的,不能进行更新、删除和插入等操作,也不能加载触发器,因为它们实际只是一个视图,不是基本表,没有关联的文件。information_schema.schemata: 该数据表存储了mysql数据库中的所有数据库的库名
information_schema.tables: 该数据表存储了mysql数据库中的所有数据表的表名
information_schema.columns: 该数据表存储了mysql数据库中的所有列的列名
五、请写出下列sql语句
1、创建一个名为spon的数据库,并查询数据库,最后删除数据库。
create database spon
show databases like ‘spon'
drop database spon
2、创建一个名为test的表格,包含num、name、salary、Sdate,要求num为主键且自增长,name为唯一的字符串,salary为不为空的整数,Sdate为默认为空的日期格式,并重新命名为demo,最后删除表格。
create table test (num int(255) auto_increment primary key not null,name varchar(255) unique,salary int(255) not null,Sdate date default null)
rename table test to demo
drop table demo
3、请写出在test表格中增加一个为bonus的整数字段,并修改为Sbonus,最后删除字段。
alter table test add bonus int(255)
alter table test change bonus Sbonus int(255)
alter table test drop column Sbonus
本次使用的数据库表信息如下:
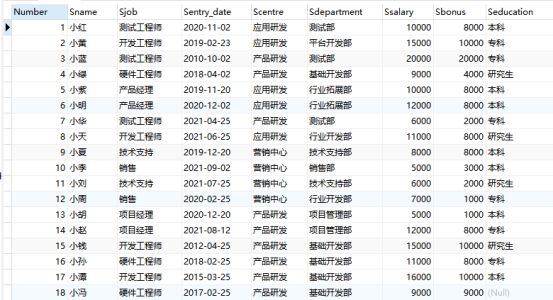
test_data
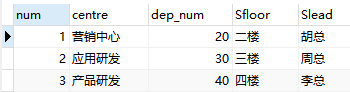
test_datas
增删改查
一、增加
语法格式:insert into 表名 (列1,列2.....,列n)values (值1,值2,.....,列n)
举例:小红以本科学历从2020年11月2日入职应用研发测试部测试工程师一职,月薪资10000,年终奖8000,请将信息录入到test_data表格里面。
insert into test_data (Sname,Sjob,Sentry_date,Scentre,Sdepartment,Ssalary,Sbonus,Seducation)values ('小红','测试工程师','20201102','应用研发','测试部','10000','8000','本科')
二、修改
语法格式:update 表名 set 列1=修改的值1,列2=修改的值2..... where 列=参照值
举例:小红在工作中做出积极贡献,月薪提高为12000,年终奖提高为11000。
update test_data set Ssalary=12000,Sbonus=10000 where Sname='小红'
三、删除
语法格式:delete from 表名 / delete from 表名 where 列=参照值
举例:小红离职后行政需要把小红的数据删除
delete from test_data where Sname='小红'
rollback回退
四、查找
语法格式:select * from 表名(星号(*)代表全部列的数据,也可以为列名只查找想要的列)
举例:总经理想查看公司所有人的信息
select * from test_data
举例:总经理想查看所有人的姓名和工资情况
select Sname,Ssalary from 表名
五、请写出下列sql语句
1.2020年7月1日小廖从本科毕业后以月薪6000入职到营销中心销售部销售一职,年终奖6000,请将信息添加到test_data表格中。
insert into test_data (Sname,Sjob,Sentry_date,Scentre,Sdepartment,Ssalary,Sbonus,Seducation)values ('小廖','销售','20200701','营销中心','销售部','6000','6000','本科')
2.小廖入职一年后,因表现好,公司领导决定要给她月薪加1000,年终奖加2000,请将信息修改到test_data表格中。
update test_data set Ssalary=7000,Sbonus=8000 where Sname='小廖'
3.俩个月后小廖离职,行政将小廖信息删除,请将信息修改到test_data表格中。
delete from test_data where Sname='小廖'
条件查询
一、带条件查询(where)
语法:select 字段列表 from 表名 where 条件表达式
1.等于查询 =
举例:查看工作岗位是测试工程师的人员信息
select * from test_data where Sjob='测试工程师'
2.不等于查询(> ,< , >= ,<= ,!= )
举例:查看工资大于等于10000的员工信息
select * from test_data where Ssalary>=10000
举例:查看不是应用研发中心的员工信息
select * from test_data where Scentre!='应用研发'
举例:查看在2020年以后入职的员工信息
select * from test_data where Sentry_date>'20200101'
3.指定范围查询 BETWEEN 值1 and 值2 和not BETWEEN 值1 and 值2
举例:查看年终奖金在8000到12000之间的员工信息
select * from test_data where Sbonus BETWEEN 8000 and 12000
举例:查看薪资不在8000到12000之间的员工信息
select * from test_data where Ssalary not BETWEEN 8000 and 12000
4.like模糊查询
% 表示0个或多个字符
_表示1个字符
举例:查找名字里面包含红的员工信息
select * from test_data where Sname like '%红%'
select * from test_data where Sname like '_红%'
select * from test_data where Sname like '_红'
5. 查询在某个集合中 not in和in
举例:查询工资是8000和10000的
select * from test_data where Ssalary in(8000,10000)
6.is null 为空 is not null
举例:查看学历为空的员工信息
select * from test_data where Seducation is null
7.not 取反
举例:查看学历不为空的员工信息
select * from test_data where Seducation is not null
8.多条件查询 and且 or 或
举例:查看学历为本科,工资大于8000的员工
select * from test_data where Seducation='本科' and Ssalary>8000
举例:查看学历为本科或者工资大于8000的员工
select * from test_data where Seducation='本科' or Ssalary>8000
二、子查询
含义:查询中嵌套查询
语法格式:
①子查询是一个数据,在where 子句中直接可使用={子查询}
②子查询是多个数据,在where子句中需要使用 列 in(子查询)
举例:查看公司工资最高的员工的所有信息。
select * from test_data where Sbonus in (select max(Sbonus) from test_data)
三、请写出下列sql语句
1.请查找入职日期在2019年1月1日以后的员工信息。
select * from test_data where Sentry_date>20190101
2.请查询入职日期在2019年1月1日至2020年12月30日之间的员工信息。
select * from test_data where Sentry_date between 20190101 and 20201230
3.请查询工资不在8000和10000的员工信息。
select * from test_data where Ssalary not in(8000,10000)
4.请查询学历信息为空的员工信息。
select * from test_data where Seducation is null
5.请查询部门里面带测试俩个字的员工信息。
select * from test_data where Sdepartment like '%测试%'
6.请查询应用研发中心测试部的员工信息。
select * from test_data where Scentre='应用研发' and Sdepartment='测试部'
7.查看工资最低的员工的所有信息。
select * from test_data where Sbonus in (select min(Sbonus) from test_data)
函数
一、最大值
语法格式:select max(列) from 表名
举例:查找公司薪资最高的员工及其薪资
select Sname,max(Ssalary) from test_data
二、最小值
语法格式:select min(列) from 表名
举例:查找公司薪资最低的员工及其薪资
select Sname,min(Ssalary) from test_data
三、求和
语法格式:select sum(列) from 表名
举例:计算公司一个月需要发多少工资
select sum(Ssalary) from test_data
四、平均值
语法格式:select avg(列) from 表名
举例:求公司平均薪资和平均奖金
select avg(Ssalary),avg(Sbonus) from test_data
五、数数
语法格式:select count(列) from 表名
举例:求公司总人数
select count(Sname) from test_data
六、长度
语法格式:select length(列) from 表名
length: 一个汉字是算三个字符,一个数字或字母算一个字符。
举例:求岗位和薪资的长度
select length(Ssalary),length(Sjob) from test_data
七、取别名
语法格式:select 列 as 列别名 from test_data
举例:查找员工的薪资并给薪资取别名为salary
select Ssalary as salary from test_data
八、表达式
语法格式:select 列 (+-*/)数 from test_data
举例:求公司员工的年薪(包括奖金)
select Sname,Ssalary*12+Sbonus from test_data
九、去重复
语法格式:select distinct(列) from test_data
举例:求公司有那些中心
select distinct(Scentre) from test_data
十、升序
语法格式:select * from 表名 order by 基准列 asc
举例:按公司薪资由低到高进行排序
select * from test_data order by Ssalary asc
十一、降序
语法格式:select * from 表名 order by 基准列 desc
举例:按公司薪资由高到低进行排序
select * from test_data order by Ssalary desc
十二、返回指定的记录数
语法格式:select * from 表名 limit n
举例:按公司薪资由高到低进行排序,只显示前3行
select * from test_data order by Ssalary desc limit 3
举例:按公司薪资由高到低进行排序,只显示第3行到第10行
select * from test_data order by Ssalary desc limit 2,8
举例:按公司薪资由高到低进行排序,只显示第10行到最后一行
select * from test_data order by Ssalary desc limit 10,-1
十三、请写出下列sql语句
1.求应用研发的最高年终奖和最低年终奖分别是多少。
select max(Sbonus),min(Sbonus) from test_data where Scentre='应用研发'
2.计算每个员工的年薪(月薪*12+年终奖)并且取名为Year_salary。
select Sname,Ssalary*12+Sbonus as Year_salary from test_data
3.求应用研发中心总人数。
select count(Sname) from test_data where Scentre='应用研发'
4.求显示应用研发员工薪资按降序排列的第2到第5条记录。
select * from test_data where Scentre='应用研发' order by Ssalary desc limit 2,4
5.求每月应用研发需要发多少工资,及其平均工资。
select sum(Ssalary),avg(Ssalary) from test_data where Scentre='应用研发'
分组
一、分组
语法格式:列1,列2,聚合...from 表名 group by 列1,列2....
解释:
1.按照字段分组,表示此字段相同的数据会被放到一个组中;
2.分组后,分组的依据列会显示在结果集中,其他列不会显示在结果集中;
3.可以对分组后的数据进行统计,做聚合运算(sum,max,min,avg);
4.聚合:在一个行的集合(一组行)上进行操作,对每个组给一个结果。
举例:查看每个中心有多少人
select Scentre,count(Sname)
from test_data
group by Scentre
举例:查看每个中心的每个部门有多少人
select Scentre,Sdepartment,count(Sname)
from test_data
group by Scentre,Sdepartment
举例:查看每个部门最高的工资是多少
select Scentre,Sdepartment,max(Ssalary)
from test_data
group by Scentre,Sdepartment
举例:查找每个部门最早入职和最晚入职的员工日期
select Scentre,Sdepartment,min(Sentry_date),max(Sentry_date)
from test_data
group by Scentre,Sdepartment
举例:查找每个部门工资大于8000的最早入职和最晚入职的员工日期
select Scentre,Sdepartment,min(Sentry_date),max(Sentry_date)
from test_data where Ssalary>8000
group by Scentre,Sdepartment
举例:查找每个部门工资大于8000的最早入职和最晚入职的员工日期,只显示每个部门人数大于1的部门
select Scentre,Sdepartment,min(Sentry_date),max(Sentry_date)
from test_data where Ssalary>8000
group by Scentre,Sdepartment
having count(Sdepartment)>1
5.where和having区别:
having一般在group by后面,筛选完组后的数据进行二次筛选,可以用聚合函数
where在聚合前进行筛选数据,不可以用聚合函数。
二、请写出下列sql语句
1.查看每个中心入职最早的员工。
select Sname,Scentre,min(Sentry_date)
from test_data
group by Scentre
2.查看每个中心一个月需要发多少工资。
select Scentre,sum(Ssalary)
from test_data
group by Scentre
3.查看每个中心本科生和研究生总共的人数。
select Scentre,count(Sname)
from test_data where Seducation='本科' or Seducation='研究生'
group by Scentre
4.查看每个中心本科生和研究生总共的人数,只显示人数大于3的中心。
select Scentre,count(Sname)
from test_data where Seducation='本科' or Seducation='研究生'
group by Scentre
having count(Sname)>3
多表关联查询
create table test_datas (Sdepartment varchar(255) default null,dep_num int(255) not null, Sfloor varchar(255) not null,Slead varchar(255) default null)engine=innodb DEFAULT charset=utf8;
一、等值连接查询(内连接)
语法结构:select a.*,b.* from a,b where a.sno=b.sno and a.score>60
select a.*,b.* from a join b on a.sno=b.sno where a.score>60
举例:查看所有的员工信息及其中心编号、楼层和领导信息
select test_data.*,test_datas.* from test_data,test_datas where test_data.Scentre=test_datas.centre
select test_data.*,test_datas.* from test_data join test_datas on test_datas.centre=test_data.Scentre
只显示相交的部分

二、左右连接(外连接)
select a.*,b.* from a left join b on a.sno=b.sno where a.score>60
select a.*,b.* from a right join b on a.sno=b.sno where a.score>60
举例:左连接查询中心相等的俩个表格
select test_data.*,test_datas.* from test_data right join test_datas on test_datas.centre=test_data.Scentre
左连接:a表中的数据全部都显示,而b表中的数据符合条件的才会显示,不符合条件的会以 null 进行填充。
右连接:b表中的数据全部都显示,而a表中的数据符合条件的才会显示,不符合条件的会以 null 进行填充。
update test_datas set centre='制造中心' where dep_num=30
三、内连接和外连接的区别:
内连接查询操作列出与连接条件匹配的数据行;
外连接,返回到查询结果集合中的不仅包含符合连接条件的行,而且还包括左表(左外连接)、右表(右外连接)或两个边接表(全外连接)中的所有数据行。
四、左连接与右连接的区别:
相同点:都属于外连接;
不同点:左连接以左边表为基准表,右连接以右边表为基准表,没有数据则用null补充;
左连接关键字为left join,右连接关键字为right join。
五、请写出下列sql语句
1.请写出每个员工的领导和楼层。
select test_data.Sname,test_datas.Sfloor,test_datas.Slead from test_data,test_datas where test_data.Scentre=test_datas.centre
2.请写出入职日期在2020年1月1日以后的员工部门编号(左连接)。
select test_data.Sname,test_datas.dep_num from test_data left join test_datas on test_data.Scentre=test_datas.centre where Sentry_date>20200101
3.请写出部门编号大于20的员工领导信息(右连接)。
select test_data.Sname,test_data.Scentre,test_data.Sdepartment,test_datas.Slead from test_data right join test_datas on test_data.Scentre=test_datas.centre where dep_num>20