本文由 网易云 发布。
原标题:分布式存储系统可靠性-如何估算
作者:孙建良,网易云对象存储负责人
1. 存储系统的可靠性
常规情况下,我们一般使用多副本技术来提高存储系统的可靠性,不论是结构化数据库存储(典型的如MySQL)、文档型NoSQL数据库存储(MongoDB)或者是常规的Blob存储系统(GFS、Hadoop)等。
数据几乎是企业的生命所在,如何较为正确地衡量集群数据的可靠性,如何进行系统设计使得集群数据达到更高的可靠性,这是本文要解答的疑问。
2. 数据丢失与copyset(复制组)
“在999块磁盘3备份系统中,同时坏三块盘情况下的数据丢失概率?”,这个跟存储系统的设计息息相关。我们先考虑两个极端设计下的情况
设计一:把999块磁盘组层333块磁盘对。
在这种设计情况下,只有选中其中一个磁盘对才会发生数据丢失。这种设计中,丢失数据的概率为 333/C(999,3) = 5.025095326058336*e-07。
设计二:数据随机打散到999盘中,极端情况下,随机一块盘上的逻辑数据的副本数据打散在在所有集群中的998块盘中。 这种设计中,丢失数据的概率为 C(999,3)/C(999,3)=1,也就是必然存在。
通过这两种极端的栗子,我们可以看到数据的丢失概率跟数据的打散程度息息相关,为了方便后续阅读,这里我们引入一个新的概念copyset(复制组)。
CopySet:包含一个数据的所有副本数据的设备组合,比如一份数据写入1,2,3三块盘,那么{1,2,3}就是一个复制组。
9个磁盘的集群中,最小情况下的copyset的组合数为3,copysets = {1,2,3}、{4,5,6}、{7,8,9},即一份数据的写入只能选择其中一个复制组,那么只有 {1,2,3}、{4,5,6}或者{7,8,9} 同时坏的情况下才会出现数据丢失。即最小copyset数量为N/R。
系统中最大的copyset的数目为 C(N,R) ,其中R为副本数,N为磁盘的数量。在完全随机选择节点写入副本数据的情况下,系统中的copyset数目会达到最大值C(N,R)。即任意选择R个磁盘都会发生一部分数据的三个副本都在这R个盘上。
磁盘数量N,副本为R的存储系统中,copyset数量S, N/R < S < C(N, R)
3. 磁盘故障与存储系统可靠性估算
3.1 磁盘故障与泊松分布
在正式估算概率之前还需要科普下一个基础的概率学分布:泊松分布。泊松分布主要描述在一个系统中随机事件发生的概率,譬如汽车站台的候客人数的概率,某个医院1个小时内出生N个新生儿的概率等等,更形象的可参见 阮一峰的《泊松分布和指数分布:10分钟教程》)。
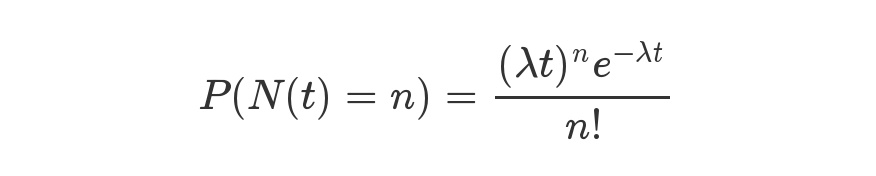
如上为泊松分布的公式。等号的左边,P 表示概率,N表示某种函数关系,t 表示时间,n 表示数量,λ 表示事件的频率。
举个例子:1000块磁盘在1年内出现10块概率为P(N(365) = 10)[注:t的平均单位为天]。λ 为1000块磁盘1天内发生故障磁盘的数量,按照Google的统计,年故障率在8%,那么 λ = 1000*8%/365 。
如上只是损坏N块磁盘的概率统计,那么怎么利用这个信息计算分布式系统中数据的可靠性(即数据丢失概率)的近似估算。
3.2 分布式存储系统中的丢失率估算
3.2.1 T时间内故障率
分布式存储存储系统中如何进行年故障率估算,我们先假定一种情况,T(1年时间内),系统存满数据的情况下,坏盘不处理。这种情况下统计下数据的年故障率。
这里我们先定义一些数据
N:磁盘数量
T:统计时间
K:坏盘数量
S: 系统中copyset数量(复制组的个数)
R:备份数量
如何计算T(1年)时间内数据丢失的概率,从概率统计角度来说就是把T(1年)时间内所有可能出现数据丢失的事件全部考虑进去。包含N个磁盘R副本冗余的系统中,在T时间内可能出现数据丢失数据的事件为坏盘大于等于R的事件,即R,R+1,R+2,… N (即为 K∈[R,N] 区间所有的时间),这些随机事件发生时,什么情况下会造成数据丢失?没错就是命中复制组的情况。
K个损坏情况下(随机选择K个盘情况下)命中复制组的概率为
p = X/C(N,K) 其中X为随机选择K个磁盘过程中命中复制组的组合数。
那么系统出现K个磁盘损坏造成数据丢失的概率为
Pa(T,K) = p * P(N(T)=K)
最后系统中T时间内出现数据丢失的概率为所有可能出现数据丢失的事件的概率加起来。
Pb(T) = Σ Pa(T,K) ; K∈[R,N]
3.2.2 分布式系统衡量年故障率
以上我们假设在一年中,不对任何硬件故障做恢复措施,那么t用一年代入即可算出此种系统状态下的年故障率。但是在大规模存储系统中,数据丢失情况下往往会启动恢复程序,恢复完了之后理论上又是从初始状态的随机事件,加入这个因素之后计算可靠性会变得比较复杂。
理论上大规模存储系统中坏盘、恢复是极其复杂的连续事件,这里我们把这个概率模型简化为不同个单位时间T内的离散事件进行统计计算。只要两个T之间连续事件的发生概率极小,并且T时间内绝大部份坏盘情况能够恢复在T时间内恢复,那么下个时间T能就是重新从新的状态开始,则这种估算能够保证近似正确性。T的单位定义为小时(即),那么1年可以划分为365/24/T个时间段,那么系统的年故障率可以理解为100%减去所有单位T时间内都不发生故障的概率。
即系统整体丢失数据的概率为:
Pc = 1 - (1-Pb(T))**(365*24/T)
4 参考文献:
了解 网易云 :
网易云官网:https://www.163yun.com/
新用户大礼包:https://www.163yun.com/gift
网易云社区:https://sq.163yun.com/