本文由 网易云 发布。
前言
Impala是一个MPP架构的查询系统,为了做到平台化服务,首先需要考虑就是如何做到资源隔离,多个产品之间尽可能小的甚至毫无影响。对于这种需求,最好的隔离方案无疑是物理机器上的隔离,A产品使用这几台机器,B产品使用那几台机器,然后前端根据产品路由到不同集群,这样可以做到理想中的资源隔离,但是这样极大的增加了部署、运维等难度,而且无法实现资源的共享,即使A产品没有任务在跑,B产品也不能使用A产品的资源,这无疑是一种浪费。毛主席教导我们浪费是可耻的,所以我们要想办法在充分利用资源的情况下实现产品之间的资源隔离,这其实是一个非常有难度的工作。
YARN
在大数据生态圈,谈到资源管理(Resource Management)和隔离(Resource Isolation),第一反应想到的肯定是YARN,它是自Hadoop2.0开始并且一直使用的一种资源管理系统, YARN主要通过集中式的资源管理服务Resource Manager管理系统中全部的资源(主要是CPU和内存),然后为每一个产品或者业务定义一个队列,该队列中定义了提交到该队列下的任务最大申请的资源总量;当一个任务提交到Resource Manager之后,它会启动一个ApplicationMaster 来负责该任务的资源申请和调度,然后根据任务需要的资源需求,向Resource Manager申请资源,Resource Manager 根据当前队列中资源剩余情况判断是否授予资源,如果当前队列资源已经被用尽则该任务需要等待直到有资源释放,等到ApplicationMaster申请到资源之后则请求NodeManager启动包含一定资源的Container,Container利用cgroups轻量级的隔离方案实现,为了根据不同的使用场景YARN也集成了不同的分配和调度策略,典型的有Capacity Scheduler和Fair Scheduler。
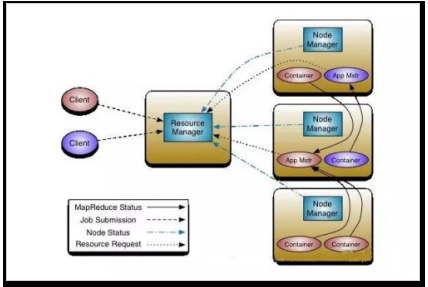
上图展示了客户端提交任务到YARN的流程,平时在提交MR、spark任务时也是通过这种方式,但是对于MPP架构的系统,它的查询响应时间由最慢的节点运行时间决定,而为了提升查询性能,又需要尽可能多的节点参与计算,而YARN上的任务每次都是启动一个新的进程,启动进程的时间对于批处理任务是可以接受的,毕竟这种任务运行时间比较久,而对于追求低延迟的Ad-hoc查询而言代价有点大了,很可能出现进程启动+初始化时间大于真正运行的时间。
除了使用原生的yarn调度,impala也尝试过使用一个称之为Llama(Long-Lived Application Master)的服务实现资源的管理和调度,它其实是YARN上的一个ApplicationMaster,实现impala和yarn之间的协调,当一个impala接收到查询之后,impala根据预估的资源需求向Llama请求资源,后者向YARN的Resource Manager服务申请可用的资源。但是前面提到了,impala为了保证查询速度需要所有的资源同时获得,这样才能推进下一步任务的执行,实际上,Llama实现了这样的批量申请的功能,所以一个查询的进行需要等到一批资源同时到达的时候才能够进行下去,除此之外,Llama还会缓存申请到的资源。但是Llama毕竟还是需要从YARN申请资源并且启动进程,还是会存在延迟比较大的问题,因此,Impala也在2.3版本之后不再支持Llama了。
Impala资源隔离
目前Impala的部署方式仍然是启动一个长时间运行的进程,对于每一个查询分配资源,而在新版本(2.6.0以后),加入了一个称为Admission Control的功能,该功能可以实现一定意义上的资源隔离,下面我们就深入了解一下这个机制,看一下它是如何对于资源进行隔离和控制的。
首先,如果根据impala的架构,所有的SQL查询,从解析、执行计划生成到执行都是在impalad节点上执行的,为了实现Admission Control,需要在impalad配置如下了两个参数:
1. --fair_scheduler_allocation_path 该参数是用来指定fair-scheduler.xml配置文件路径,该文件类似于YARN的fair- scheduler.xml配置,具体配置内容下面再详细讲述;
2. --llama_site_path 该参数用来指定Llama的配置文件llama-site.xml,上面不是说到新版本不用Llama了吗?为什么还要配置它呢,其实这里面的配置项都是一些历史遗留项了吧。
接下来就详细介绍一下如何配置这两个文件,对于第一个文件fair-scheduler.xml,熟悉YARN的都知道该文件实现公平调度器的配置,YARN中的公平调度是如何实现的我不懂,但是文件中基本上需要配置一下每一个队列的资源分配情况,下面是一个配置实例:
<queue name="sample_queue">
<minResources>10000 mb,0vcores</minResources>
<maxResources>90000 mb,0vcores</maxResources>
<maxRunningApps>50</maxRunningApps>
<weight>2.0</weight>
<schedulingPolicy>fair</schedulingPolicy>
<aclSubmitApps>charlie</aclSubmitApps>
</queue>
但是通过impala源码发现impala中用到的每一个队列的配置只有aclSubmitApps和maxResources,前者用于确定该队列可以由哪些用户提交任务,如果用户没有该队列的提交权限(队列中没设置),或者用户没指定队列则提交到default队
列,如果default队列不存在或者用户没有提交到的default队列的权限,则拒绝该请求;后者是用于确定该队列在整个集群中使用的最大资源数,目前impala关注的资源只有memory。在上例中sample_queue队列在整个集群中能够使用的内存大小是90GB,只有charlie用户能够提交到该队列。
既然只用到这两个配置,为什么impala不单独搞一个配置格式呢,而选择直接用fair-schedular.xml呢?我想一方面是为了省去自己写解析类了,直接使用yarn的接口就可以了,另外为以后更加完善做准备。下面再看一下Llama配置中用到了什么配置,配置实例如下:
<property>
<name>llama.am.throttling.maximum.placed.reservations.root.default</name>
<value>10</value>
</property>
<property>
<name>llama.am.throttling.maximum.queued.reservations.root.default</name>
<value>50</value>
</property>
<property>
<name>impala.admission-control.pool-default-query-options.root.default</name>
<value>mem_limit=128m,query_timeout_s=20,max_io_buffers=10</value>
</property>
<property>
<name>impala.admission-control.pool-queue-timeout-ms.root.default</name>
<value>30000</value>
</property>
这些配置的意义如下,具体的配置项则是如下key后面再加上队列名:
//队列中同时在跑的任务的最大个数,默认是不限制的llama.am.throttling.maximum.placed.reservations
//队列中阻塞的任务的最大个数,默认值是200 llama.am.throttling.maximum.queued.reservations
//队列中阻塞的任务在阻塞队列中最大的等待时间,默认值是60s
好了 , 分析完了Admission Control中使用的配置项,用户可以在创建一个session之后通过set REQUEST_POOL=pool_name的方式设置改session的请求提交的队列,当然如果该用户没有该队列的提交权限,之后执行都会失败。下面根据查询的流程看一下impala如何利用这些参数完成资源隔离的 当impala接收到一个查询请求之后,请求除了包含查询SQL之外,还包括一批查询参数,这里我们关心的是该请求提交的队列(REQUEST_POOL参数),它首先根据查询执行的用户和队列参数获得该查询应该提交到的队列,选取队列的规则如下:
1. 如果服务端没有配置fair-scheduler.xml和llama-site.xml,说明没有启动资源控制服务,则所有的请求都提交到一个名为default-pool的默认队列中;
2. 如果该查询没有指定REQUEST_POOL,则将REQUEST_POOL设置为yarn默认队列default。
判断队列名是否存在,然后再根据当前提交任务的用户和队列名判断该用户是否具有提交任务到队列的权限。如果队列名不存在或者该用户无权限提交则查询失败。
查询执行完初始化工作(选择队列只是其中的一部分工作)之后会调用FE的GetExecRequest接口进行执行计划的生成, 生成执行计划的流程大致分为三部:
1. 语法分析生成逻辑执行计划并进行预处理;
2. 根据逻辑执行计划生成单机执行计划;
3. 将单机执行计划转换成物理自行计划,后续再单独介绍这部分。
接着impalad节点会根据执行计划判断该查询是否可以继续执行,只有出现如下几种情况时,查询需要排队:
1. 当前队列中已经有查询在排队,因为阻塞队列是FIFO调度的,所以新来的查询需要直接排队;
2. 已经达到该队列设置的并发查询上线;
3. 当前查询需要的内存不能够得到满足。
前两种条件比较容易判断,对于第三种情况,impala需要知道当前查询需要的内存和当前队列中剩余的内存情况进行判断,这里的内存使用分为两个方面:集群中队列剩余的总内存和单机剩余内存。首先判断队列中剩余内存和当前查询需要在集群中使用的内存是否达到了队列设置的内存上限;然后在判断该查询在每一个impalad节点上需要的内存和该节点剩余内存是否达到设置的内存上限(节点的内存上限是由参数mem_limit设置的)。那么问题又来了,该查询在整个集群需要多少内存,在每一个节点上需要多少内存是如何计算的呢?对于整个集群上需要内存其实就是每一个节点需要的内存乘以需要的节点数,那么核心问题就是该查询需要在每一个节点使用的内存大小。
可能大家和我一样觉得,对于每一个查询需要在每一个节点消耗的内存是根据查询计划预估出来的,但是这样做是非常难的,那么来看一下当前impala是如何做的,对于单节点内存的预估,按照如下的优先级计算查询需要的单机内存:
1. 首先判断查询参数rm_initial_mem是否被设置(可以通过set rm_initial_mem =xxx设置),如果设置了则直接使用该值作为预估值;
2. 然后判断impalad启动的时候是否设置rm_always_use_defaults=true,如果设置了则使用rm_default_memory中配置的内存大小;
3. 接着再判断该session是否设置了mem_limit(可以通过set mem_limit=xx设置,注意它和impalad启动时的mem_limit配置的区别),如果设置则使用该值;
4. 最后根据判断执行计划中是否计算出了每一个节点需要分配的内存大小;
5. 如果以上都没有命中则使用默认的rm_default_memory配置(impalad启动时候的参数),该值默认值是“4GB”。
从上面的的判断逻辑来看,impalad最后才会根据执行计划中预估的值确定每一个节点分配的内存大小,毕竟只是根据统计信息预估出来的信息并不是准确的,对于一些复杂的查询而言,可能是误差非常大的。
好了,通过上面的分析,整个查询审计流程梳理了一遍,但是如果当前资源不能够满足该查询呢?此时就需要将该查询放入队列中,该查询则会阻塞直到满足如下两种条件之一:
1. 该查询所使用的队列拥有了该查询需要的足够的资源;
2. 该查询存放在队列中并超时,超时时间是由队列中的queue_timeout_ms参数设置,如果队列没设置则由impalad启动时的queue_wait_timeout_ms参数决定,默认是60s。
再谈Statestore
我们这里就不深究执行计划中的内存估计是如何计算的了,但是还有一个比较重要的问题:每一个impalad是独立工作的,只有在需要分配任务的时候才会通知其余的impalad执行相应的operation,那么impalad如何知道其他impalad节点的资源状态的?包括每一个队列已使用的内存大小,每一个节点已使用的内存大小等。这就靠我们上一篇文章中介绍的statestored了,在statestored中impalad启动时会注册一个impala-request-queue主题,每一个impalad都是该topic的发布者同时也是订阅者,周期性的发布当前节点的内存使用情况,然后每一个impalad节点再根据topic中最新的信息更新整个集群的资源使用状态。这种交互方式的确挺方便,但是可能存在一定的不确定性,例如某一次impalad与statestored 的网络抖动都有可能导致无法获取到最新的资源使用状态。
硬性限制
impalad使用Admission Control实现了一定意义上的资源隔离,但是这毕竟是软性的,而不是像YARN那种通过cgroup 启动新进程来进行隔离,仍然有可能存在一个比较繁重的查询将整个集群搞垮,对于这种情况作为查询平台我们需要做到即使返回错误也不能影响这个整个集群的服务,此时就需要祭出impala查询的一个关键性参数:mem_limit,对于impalad中的每一个模块,启动时都可以设置mem_limit参数,该参数是每一个执行节点能够分配的最大内存(tcmalloc 管理),而每一个查询也可以设置mem_limit,它表示该查询在每一个节点上最大分配的内存大小,再每一个impalad执行查询(impala中称之为fragment)的时候会分配一个大小为mem_limit的block pool,需要的内存从pool中分配并保存在内存中,如果分配的内存超出pool的大小,则选择一定的block spill到外存中,这部分具体的执行流程也是非常复杂了,可以单独再讲,这部分block在需要的时候再从本地磁盘读取到内存中,需要spill到外存的查询无疑会拖慢查询速度, 但是这很好的保存了整个系统的可用性和稳定性。
总结
在实际部署的时候,我们会根据每一个用户的数据量大小、业务类型分配队列,甚至相同的业务不同时间区间的查询分配不同的队列,并且详细设置该队列中的默认查询参数,尤其是mem_limit参数和最大并发数,这样可以较好的限制租户之间的影响,为了避免恶意用于的使用,可以限制用户自己设置MEM_LIMIT参数,尽可能得保证集群的稳定性。
网易有数:企业级大数据可视化分析平台。面向业务人员的自助式敏捷分析平台,采用PPT模式的报告制作,更加易学易用,具备强大的探索分析功能,真正帮助用户洞察数据发现价值。可点击这里免费试用。
了解 网易云 :
网易云官网:https://www.163yun.com/
新用户大礼包:https://www.163yun.com/gift
网易云社区:https://sq.163yun.com/