参考链接:
https://www.jianshu.com/p/caa4b923117c
https://blog.csdn.net/papaaa/article/details/78821631
1.CountVectorizer
CountVectorizer会将文本中的词语转换为词频矩阵,它通过fit_transform函数计算各个词语出现的次数,通过get_feature_names()可获得所有文本的关键词,通过toarray()可看到词频矩阵的结果。
代码如下:
from sklearn.feature_extraction.text import CountVectorizer texts=["dog cat fish","dog cat cat","fish bird", 'bird'] cv = CountVectorizer() cv_fit=cv.fit_transform(texts) print("文本的关键词: ", cv.get_feature_names()) print("词频矩阵: ", cv_fit.toarray()) print("cv_fit: ", cv_fit)
返回的结果为稀疏矩阵:

2.TfidfTransformer
TfidfTransformer用于统计vectorizer中每个词语的TF-IDF值。代码如下:
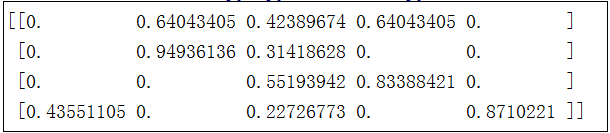
from sklearn.feature_extraction.text import CountVectorizer from sklearn.feature_extraction.text import TfidfTransformer texts=["dog cat fish","dog cat cat","dog fish", 'dog pig pig bird'] cv = CountVectorizer() cv_fit=cv.fit_transform(texts) transformer = TfidfTransformer() tfidf = transformer.fit_transform(cv_fit) print (tfidf.toarray())
输出结果为:
3.TfidfTransformer
将原始文档的集合转化为tf-idf特性的矩阵,相当于CountVectorizer配合TfidfTransformer使用的效果。
即TfidfVectorizer类将CountVectorizer和TfidfTransformer类封装在一起。
代码如下:
from sklearn.feature_extraction.text import TfidfVectorizer texts=["dog cat fish","dog cat cat","dog fish", 'dog pig pig bird'] tv = TfidfVectorizer(max_features=100, ngram_range=(1, 1), stop_words='english') X_description = tv.fit_transform(texts) print(X_description.toarray())
结果为:

可观察到输出的结果和上面的结果是一毛一样的。
ngram_range=(1, 1)也可以改为(2,3),这就是2-gram.
stop_words暂时只支持英文,即”english”