0x00 前言
大部分内容来自参考连接的内容,只是一种爬取内容的思路。
在很久以前自己会有爬取zone-h做目标测试的需求,但是总是有各种反爬限制。而且个别网址还有前端自动生成内容的功能,使用JavaScript可以很方便的让我们得到自己想要得结果做数据整理。
- 会用到DOM属性如下:
document.getElementsByClassName() 返回文档中所有指定类名的元素集合,作为 NodeList 对象。
document.getElementById() 返回对拥有指定 id 的第一个对象的引用。
document.getElementsByName() 返回带有指定名称的对象集合。
document.getElementsByTagName() 返回带有指定标签名的对象集合。
- js截取指定字符前面或后面的内容
function getCaption(obj,state) {
var index=obj.lastIndexOf("-");
if(state==0){
obj=obj.substring(0,index);
}else {
obj=obj.substring(index+1,obj.length);
}
return obj;
}
var data = 'aaa-bbb'
//截取符号前面部分
getCaption(data,0) //输出aaa
//截取符号后面部分
getCaption(data,1) //输出bbb
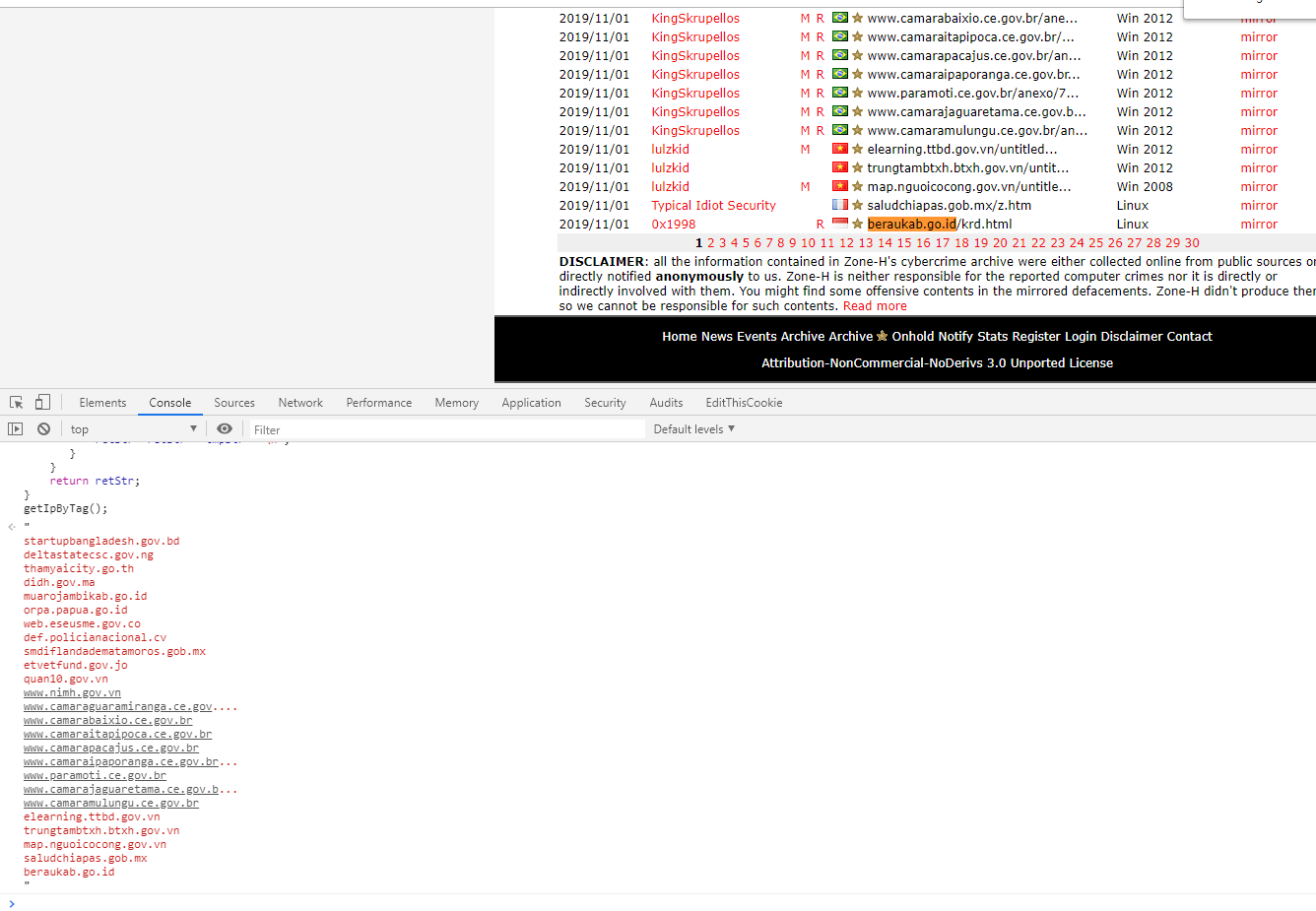
0x01 提取zone-h结果
function getIpByTag(){
var trVal = document.getElementsByTagName("tr");
var retStr="
";
var tmpStr="";
for(var i=1;i< trVal.length-4;i++)
{
tmpStr = trVal[i].getElementsByTagName('td')[7].innerHTML.trim();
var index = tmpStr.indexOf('/');
if(index>0)
{
retStr= retStr + tmpStr.substring(0,index) + "
";}
else
{
retStr= retStr + tmpStr+ "
";
}
console.log(i,tmpStr)
}
return retStr;
}
getIpByTag();
0x02 提取Shodan结果ip
Shadan
//方法1:获取标签提取
console.log(document.getElementsByClassName("ip")[0].firstChild.innerHTML)
function getIpByTag()
{
var ip = document.getElementsByClassName("ip");
var str = "
";
for(var i=0; i < ip.length; i++)
{
var node = ip[i].firstChild;
str = str + node.innerHTML + "
";
}
return str;
}
getIpByTag();
//方法2:正则提取
function getIpByTag(){
var tag = document.getElementsByClassName("span9")[0];
var re = new RegExp();
var str = tag.innerHTML;
var re = /d+.d+.d+.d+/g;
var arr = str.match(re);
console.log(arr);
//数组去重
arr.sort();
for(var i = 0; i < arr.length-1;) {
//用当前的元素与他的前一个元素进行对比
if(arr[i] == arr[i + 1]) {
//如果相同的话,就删除掉第i个元素
arr.splice(i, 1);
}else{ i++;}
}
console.log(arr);
0x03 抓取Google结果
Google
console.log(document.getElementsByClassName("r")[0.].firstChild.href)
function getIpByTag()
{
var r = document.getElementsByClassName("r");
var str = '
';
for(var i=0;i< r.length;i++)
{
str = str + r[i].firstChild.href + '
';
}
return str;
}
getIpByTag();
0x04 提取百度结果
Baidu
console.log(document.getElementsByClassName("t")[0].getElementsByTagName('a')[0].href)
function getIpByTag()
{
var t = document.getElementsByClassName("t");
var str = '
';
for(var i=0;i< t.length;i++)
{
str = str + '"' + t[i].getElementsByTagName('a')[0].href + '",
';
}
str = str.substring(0,str.length-2)
str = str + '
'
return str;
}
getIpByTag();
将百度加密后的url转成真正的地址:
import requests
urlList = [
"http://www.baidu.com/link?url=M1SN1OPmF9xM43i4jwjeDVvn-uD-i7xOf1nDxZDdIh4iCQRPXnmJnpzEFaRpcLNbSzXJGnlGiRClt_kX_KjXo_",
"http://www.baidu.com/link?url=9J00kAi9Fu07zxr4q4v_WZ2b0lW6WM-eIuzzcRtKQSS8Hd2u7hqAyBYyDOm1JbAwGgrUAubK8cR3V2_7RFJ1j_",
"http://www.baidu.com/link?url=kJuAmhEDNtu9VT5tpF_Grdi5fv246Dyf6ESnWqyBrR9HZD8BniQXVqOEinUox_hn",
"http://www.baidu.com/link?url=9Zlb9C0SnpP01To84341TBe2Tr1888CY8vkv86ZJAB94GoDO0II9m19lJpAKmSlm",
"http://www.baidu.com/link?url=e-jNCpBOgKCFOAGakRSt7jsqeKM4Z7kAKxmzFXyizOybrMP3Ig5MVmIHd6cwgsug",
"http://www.baidu.com/link?url=mhPGHLye4mCUdZOKGZz-RY_d7vzNThy_ifVZ8qGpAkvEGYUspJKT5wvHX0LSvPVd",
"http://www.baidu.com/link?url=NOw1rL9Juxdl-_FYexMJq8n1I3vliWRPjMAVZT8YQ-S9nHOXn-EuI8YnIz6-8EXF",
"http://www.baidu.com/link?url=3iCH4yJeE6UA_Pura3WMiNcoLBOYKePK0teNAwELb3667oy-RXOSuanprur6GjUN",
"http://www.baidu.com/link?url=w_7v1e_uvw8YSQyZEA-SN1vnIIljpmknKaVLTtdZqxM8qLXi0C0LwLAUQJyrZYTY8aU4DjPnXtQeUQlP-zqzXK",
"http://www.baidu.com/link?url=DjXRm8KwbnSAOaPtt3NtR7XzwCnWizbgJDxeC9DPB0GBeSJIiYb2ObZHQ5mLsYjP"
]
for someurl in urlList:
response = requests.get(someurl)
if response.history:
print(response.url)
else:
print("Request was not redirected")
参考
[1] 使用Chrome console提取页面数据
https://www.cnblogs.com/liun1994/p/7265828.html
[2] Google浏览器URL采集的一种思路
https://blog.csdn.net/qq_29647709/article/details/84379170
[3] 使用浏览器控制台抓取信息
https://lufe1.cn/2017/09/20/使用浏览器控制台抓取信息/
[4] js截取指定字符前面或后面的内容
https://blog.csdn.net/caiyongshengCSDN/article/details/88420416