一、数据分类
1、结构化数据:有固定类型或者有固定长度的数据
数据库中的数据(mysql,oracle等), 元数据(就是windows中的数据)。数据库中数据通过sql语句可以搜索,元数据(windows中的)通过windows提供的搜索栏进行搜索
2、非结构化数据:没有固定类型和固定长度的数据
world文档中的数据, 邮件中的数据。Word文档使用ctrl+F来搜索
3、顺序扫描法
Ctrl+F中是使用的顺序扫描法,拿到搜索的关键字,去文档中,逐字匹配,直到找到和关键字一致的内容为止
优点: 如果文档中存在要找的关键字就一定能找到想要的内容
缺点: 慢, 效率低
4、全文检索算法(倒排索引算法)
将文件中的内容提取出来, 将文字拆封成一个一个的词(分词), 将这些词组成索引(字典中的目录), 搜索的时候先搜索索引,通过索引找文档,这个过程就叫做全文检索
分词: 去掉停用词(a, an, the ,的, 地, 得, 啊, 嗯 ,呵呵),因为搜索的时候搜索这些词没有意义,将句子拆分成词,去掉标点符号和空格
优点: 搜索速度快
缺点: 因为创建的索引需要占用磁盘空间,所以这个算法会使用掉更多的磁盘空间,这是用空间换时间
原理
相当于字典,分为目录和正文两部分,查询的时候通过先查目录,然后通过目录上标注的页数去正文页查找需要的内容
二、Lucene简介
apache旗下的顶级项目,是一个全文检索工具包,可以使用它来构建全文检索引擎系统,但是它不能独立运(JDK要求1.7)
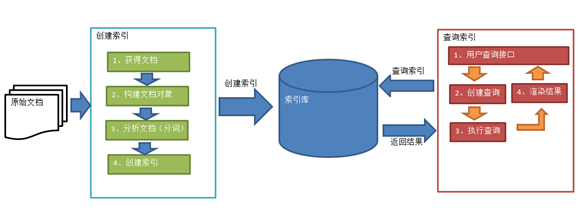
1、全文检索引擎系统
放在tomcat下可以独立运行,对外提供全文检索服务
2、应用领域
(1)互联网全文检索引擎(比如百度, 谷歌, 必应)
(2)站内全文检索引擎(淘宝, 京东搜索功能)
(3)优化数据库查询(因为数据库中使用like关键字是全表扫描也就是顺序扫描算法,查询慢)
三、Lucene结构
Lucene包括索引和文档(K-V)
1、索引(Index)
域名:词 这样的形式,它里面有指针执行这个词来源的文档
索引库:放索引的文件夹
词元(Term):就是一个词, 是Lucene中词的最小单位
2、文档(Document)
Document对象,一个Document中可以有多个Field域对象,Field域对象中是key-value键值对的形式:有域名和域值
一个document就是数据库表中的一条记录, 一个Filed域对象就是数据库表中的一行一列,这是一个通用的存储结构
创建索引和所有时所用的分词器必须一致
创建索引
用Luke可查看创建完成的索引
java -jar lukeall-4.10.3.jar
@Test public void testIndexCreate() throws Exception{ //创建文档列表,保存多个Docuemnt List<Document> docList = new ArrayList<Document>(); //指定文件所在目录 File dir = new File("E:\searchsource"); //循环文件夹取出文件 for(File file : dir.listFiles()){ //文件名称 String fileName = file.getName(); //文件内容 String fileContext = FileUtils.readFileToString(file); //文件大小 Long fileSize = FileUtils.sizeOf(file); //文档对象,文件系统中的一个文件就是一个Docuemnt对象 Document doc = new Document(); //第一个参数:域名 //第二个参数:域值 //第三个参数:是否存储,是为yes,不存储为no /*TextField nameFiled = new TextField("fileName", fileName, Store.YES); TextField contextFiled = new TextField("fileContext", fileContext, Store.YES); TextField sizeFiled = new TextField("fileSize", fileSize.toString(), Store.YES);*/ //是否分词:要,因为它要索引,并且它不是一个整体,分词有意义 //是否索引:要,因为要通过它来进行搜索 //是否存储:要,因为要直接在页面上显示 TextField nameField = new TextField("fileName", fileName, Store.YES); //是否分词: 要,因为要根据内容进行搜索,并且它分词有意义 //是否索引: 要,因为要根据它进行搜索 //是否存储: 可以要也可以不要,不存储搜索完内容就提取不出来 TextField contextField = new TextField("fileContext", fileContext, Store.NO); //是否分词: 要, 因为数字要对比,搜索文档的时候可以搜大小, lunene内部对数字进行了分词算法 //是否索引: 要, 因为要根据大小进行搜索 //是否存储: 要, 因为要显示文档大小 LongField sizeField = new LongField("fileSize", fileSize, Store.YES); //将所有的域都存入文档中 doc.add(nameField); doc.add(contextField); doc.add(sizeField); //将文档存入文档集合中 docList.add(doc); } //创建分词器,StandardAnalyzer标准分词器,标准分词器对英文分词效果很好,对中文是单字分词 Analyzer analyzer = new IKAnalyzer(); //指定索引和文档存储的目录 Directory directory = FSDirectory.open(new File("E:\dic")); //创建写对象的初始化对象 IndexWriterConfig config = new IndexWriterConfig(Version.LUCENE_4_10_3, analyzer); //创建索引和文档写对象 IndexWriter indexWriter = new IndexWriter(directory, config); //将文档加入到索引和文档的写对象中 for(Document doc : docList){ indexWriter.addDocument(doc); } //提交 indexWriter.commit(); //关闭流 indexWriter.close(); }
索引搜索
@Test public void testIndexSearch() throws Exception{ //创建分词器(创建索引和所有时所用的分词器必须一致) Analyzer analyzer = new IKAnalyzer(); //创建查询对象,第一个参数:默认搜索域, 第二个参数:分词器 //默认搜索域作用:如果搜索语法中指定域名从指定域中搜索,如果搜索时只写了查询关键字,则从默认搜索域中进行搜索 QueryParser queryParser = new QueryParser("fileContext", analyzer); //查询语法=域名:搜索的关键字 Query query = queryParser.parse("fileName:web"); //指定索引和文档的目录 Directory dir = FSDirectory.open(new File("E:\dic")); //索引和文档的读取对象 IndexReader indexReader = IndexReader.open(dir); //创建索引的搜索对象 IndexSearcher indexSearcher = new IndexSearcher(indexReader); //搜索:第一个参数为查询语句对象, 第二个参数:指定显示多少条 TopDocs topdocs = indexSearcher.search(query, 5); //一共搜索到多少条记录 System.out.println("=====count=====" + topdocs.totalHits); //从搜索结果对象中获取结果集 ScoreDoc[] scoreDocs = topdocs.scoreDocs; for(ScoreDoc scoreDoc : scoreDocs){ //获取docID int docID = scoreDoc.doc; //通过文档ID从硬盘中读取出对应的文档 Document document = indexReader.document(docID); //get域名可以取出值 打印 System.out.println("fileName:" + document.get("fileName")); System.out.println("fileSize:" + document.get("fileSize")); System.out.println("============================================================"); } }
四、域(Field)
在文档Document对象中的Field,为K-V键值对
1、是否分词
分词的作用是为了索引
需要分词: 文件名称, 文件内容
不需要分词: 不需要索引的域不需要分词,还有就是分词后无意义的域不需要分词,比如: id, 身份证号
2、是否索引
索引的的目的是为了搜索
需要搜索的域就一定要创建索引,只有创建了索引才能被搜索出来
不需要搜索的域可以不创建索引
需要索引: 文件名称, 文件内容, id, 身份证号等
不需要索引: 比如图片地址不需要创建索引, e:\xxx.jpg,根据图片地址搜索无意义
3、是否存储
存储的目的是为了显示
是否存储看个人需要,存储就是将内容放入Document文档对象中保存出来,会额外占用磁盘空间, 如果搜索的时候需要马上显示出来可以放入document中也就是要存储,
这样查询显示速度快, 如果不是马上立刻需要显示出来,则不需要存储,因为额外占用磁盘空间不划算
4、域的类型
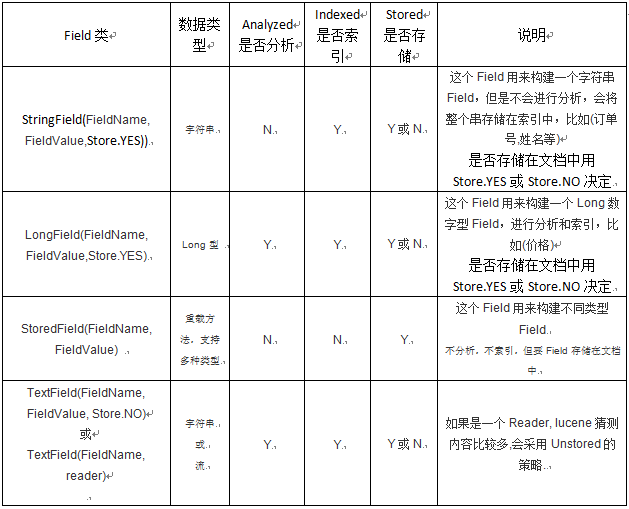
注意:Lucene底层的算法,钱数是要分词的,因为要根据价钱进行对比
五、中文分词器
1、自带
StandardAnalyzer:单字分词:就是按照中文一个字一个字地进行分词
CJKAnalyzer:二分法分词:按两个字进行切分
SmartChineseAnalyzer:对中文支持较好,但扩展性差,扩展词库,禁用词库和同义词库等不好处理
2、第三方
IK-analyzer
stopword.dic停止字典和扩展字典ext.dic,修改后保存为UTF-8
导入IKAnalyzer2012FF_u1.jar
加配置文件ext.dic、IKAnalyzer.cfg.xml、stopword.dic
六、索引的维护
1、删除文档
可以根据某个域的内容进行删除,还可以一次删除所有
@Test public void testIndexDel() throws Exception{ //创建分词器,StandardAnalyzer标准分词器,标准分词器对英文分词效果很好,对中文是单字分词 Analyzer analyzer = new IKAnalyzer(); //指定索引和文档存储的目录 Directory directory = FSDirectory.open(new File("E:\dic")); //创建写对象的初始化对象 IndexWriterConfig config = new IndexWriterConfig(Version.LUCENE_4_10_3, analyzer); //创建索引和文档写对象 IndexWriter indexWriter = new IndexWriter(directory, config); //删除所有 //indexWriter.deleteAll(); //根据名称进行删除 //Term词元,就是一个词, 第一个参数:域名, 第二个参数:要删除含有此关键词的数据 indexWriter.deleteDocuments(new Term("fileName", "apache")); //提交 indexWriter.commit(); //关闭 indexWriter.close(); }
2、更新文档
更新就是按照传入的Term进行搜索,如果找到结果那么删除,将更新的内容重新生成一个Document对象
如果没有搜索到结果,那么将更新的内容直接添加一个新的Document对象
/** * 更新就是按照传入的Term进行搜索,如果找到结果那么删除,将更新的内容重新生成一个Document对象 * 如果没有搜索到结果,那么将更新的内容直接添加一个新的Document对象 * @throws Exception */ @Test public void testIndexUpdate() throws Exception{ //创建分词器,StandardAnalyzer标准分词器,标准分词器对英文分词效果很好,对中文是单字分词 Analyzer analyzer = new IKAnalyzer(); //指定索引和文档存储的目录 Directory directory = FSDirectory.open(new File("E:\dic")); //创建写对象的初始化对象 IndexWriterConfig config = new IndexWriterConfig(Version.LUCENE_4_10_3, analyzer); //创建索引和文档写对象 IndexWriter indexWriter = new IndexWriter(directory, config); //根据文件名称进行更新 Term term = new Term("fileName", "web"); //更新的对象 Document doc = new Document(); doc.add(new TextField("fileName", "xxxxxx", Store.YES)); doc.add(new TextField("fileContext", "think in java xxxxxxx", Store.NO)); doc.add(new LongField("fileSize", 100L, Store.YES)); //更新 indexWriter.updateDocument(term, doc); //提交 indexWriter.commit(); //关闭 indexWriter.close(); }
七、搜索(查询)
1、TermQuery:根据词进行搜索(只能从文本中进行搜索)
@Test public void testIndexTermQuery() throws Exception{ //创建分词器(创建索引和所有时所用的分词器必须一致) Analyzer analyzer = new IKAnalyzer(); //创建词元:就是词, Term term = new Term("fileName", "apache"); //使用TermQuery查询,根据term对象进行查询 TermQuery termQuery = new TermQuery(term); //指定索引和文档的目录 Directory dir = FSDirectory.open(new File("E:\dic")); //索引和文档的读取对象 IndexReader indexReader = IndexReader.open(dir); //创建索引的搜索对象 IndexSearcher indexSearcher = new IndexSearcher(indexReader); //搜索:第一个参数为查询语句对象, 第二个参数:指定显示多少条 TopDocs topdocs = indexSearcher.search(termQuery, 5); //一共搜索到多少条记录 System.out.println("=====count=====" + topdocs.totalHits); //从搜索结果对象中获取结果集 ScoreDoc[] scoreDocs = topdocs.scoreDocs; for(ScoreDoc scoreDoc : scoreDocs){ //获取docID int docID = scoreDoc.doc; //通过文档ID从硬盘中读取出对应的文档 Document document = indexReader.document(docID); //get域名可以取出值 打印 System.out.println("fileName:" + document.get("fileName")); System.out.println("fileSize:" + document.get("fileSize")); System.out.println("============================================================"); } }
2、QueryParser:根据域名进行搜索,可以设置默认搜索域,推荐使用. (只能从文本中进行搜索)
//创建查询对象,第一个参数:默认搜索域, 第二个参数:分词器 //默认搜索域作用:如果搜索语法中指定域名从指定域中搜索,如果搜索时只写了查询关键字,则从默认搜索域中进行搜索 QueryParser queryParser = new QueryParser("fileContext", analyzer); //查询语法=域名:搜索的关键字 Query query = queryParser.parse("fileName:web");
3、NumericRangeQuery:从数值范围进行搜索
@Test public void testNumericRangeQuery() throws Exception{ //创建分词器(创建索引和所有时所用的分词器必须一致) Analyzer analyzer = new IKAnalyzer(); //根据数字范围查询 //查询文件大小,大于100 小于1000的文章 //第一个参数:域名 第二个参数:最小值, 第三个参数:最大值, 第四个参数:是否包含最小值, 第五个参数:是否包含最大值 Query query = NumericRangeQuery.newLongRange("fileSize", 100L, 1000L, true, true); //指定索引和文档的目录 Directory dir = FSDirectory.open(new File("E:\dic")); //索引和文档的读取对象 IndexReader indexReader = IndexReader.open(dir); //创建索引的搜索对象 IndexSearcher indexSearcher = new IndexSearcher(indexReader); //搜索:第一个参数为查询语句对象, 第二个参数:指定显示多少条 TopDocs topdocs = indexSearcher.search(query, 5); //一共搜索到多少条记录 System.out.println("=====count=====" + topdocs.totalHits); //从搜索结果对象中获取结果集 ScoreDoc[] scoreDocs = topdocs.scoreDocs; for(ScoreDoc scoreDoc : scoreDocs){ //获取docID int docID = scoreDoc.doc; //通过文档ID从硬盘中读取出对应的文档 Document document = indexReader.document(docID); //get域名可以取出值 打印 System.out.println("fileName:" + document.get("fileName")); System.out.println("fileSize:" + document.get("fileSize")); System.out.println("============================================================"); } }
4、BooleanQuery:组合查询,可以设置组合条件,not and or.从多个域中进行查询
must相当于and关键字,并且
should,相当于or关键字或者
must_not相当于not关键字, 非
注意:单独使用must_not 或者 独自使用must_not没有任何意义
@Test public void testBooleanQuery() throws Exception{ //创建分词器(创建索引和所有时所用的分词器必须一致) Analyzer analyzer = new IKAnalyzer(); //布尔查询,就是可以根据多个条件组合进行查询 //文件名称包含apache的,并且文件大小大于等于100 小于等于1000字节的文章 BooleanQuery query = new BooleanQuery(); //根据数字范围查询 //查询文件大小,大于100 小于1000的文章 //第一个参数:域名 第二个参数:最小值, 第三个参数:最大值, 第四个参数:是否包含最小值, 第五个参数:是否包含最大值 Query numericQuery = NumericRangeQuery.newLongRange("fileSize", 100L, 1000L, true, true); //创建词元:就是词, Term term = new Term("fileName", "apache"); //使用TermQuery查询,根据term对象进行查询 TermQuery termQuery = new TermQuery(term); //Occur是逻辑条件 //must相当于and关键字,是并且的意思 //should,相当于or关键字或者的意思 //must_not相当于not关键字, 非的意思 //注意:单独使用must_not 或者 独自使用must_not没有任何意义 query.add(termQuery, Occur.MUST); query.add(numericQuery, Occur.MUST); //指定索引和文档的目录 Directory dir = FSDirectory.open(new File("E:\dic")); //索引和文档的读取对象 IndexReader indexReader = IndexReader.open(dir); //创建索引的搜索对象 IndexSearcher indexSearcher = new IndexSearcher(indexReader); //搜索:第一个参数为查询语句对象, 第二个参数:指定显示多少条 TopDocs topdocs = indexSearcher.search(query, 5); //一共搜索到多少条记录 System.out.println("=====count=====" + topdocs.totalHits); //从搜索结果对象中获取结果集 ScoreDoc[] scoreDocs = topdocs.scoreDocs; for(ScoreDoc scoreDoc : scoreDocs){ //获取docID int docID = scoreDoc.doc; //通过文档ID从硬盘中读取出对应的文档 Document document = indexReader.document(docID); //get域名可以取出值 打印 System.out.println("fileName:" + document.get("fileName")); System.out.println("fileSize:" + document.get("fileSize")); System.out.println("============================================================"); } }
5、MatchAllDocsQuery:查询出所有文档
@Test public void testMathAllQuery() throws Exception{ //创建分词器(创建索引和所有时所用的分词器必须一致) Analyzer analyzer = new IKAnalyzer(); //查询所有文档 MatchAllDocsQuery query = new MatchAllDocsQuery(); //指定索引和文档的目录 Directory dir = FSDirectory.open(new File("E:\dic")); //索引和文档的读取对象 IndexReader indexReader = IndexReader.open(dir); //创建索引的搜索对象 IndexSearcher indexSearcher = new IndexSearcher(indexReader); //搜索:第一个参数为查询语句对象, 第二个参数:指定显示多少条 TopDocs topdocs = indexSearcher.search(query, 5); //一共搜索到多少条记录 System.out.println("=====count=====" + topdocs.totalHits); //从搜索结果对象中获取结果集 ScoreDoc[] scoreDocs = topdocs.scoreDocs; for(ScoreDoc scoreDoc : scoreDocs){ //获取docID int docID = scoreDoc.doc; //通过文档ID从硬盘中读取出对应的文档 Document document = indexReader.document(docID); //get域名可以取出值 打印 System.out.println("fileName:" + document.get("fileName")); System.out.println("fileSize:" + document.get("fileSize")); System.out.println("============================================================"); } }
6、MultiFieldQueryParser:可以从多个域中进行查询,只有这些域中有关键词的存在就查询出来
@Test public void testMultiFieldQueryParser() throws Exception{ //创建分词器(创建索引和所有时所用的分词器必须一致) Analyzer analyzer = new IKAnalyzer(); String [] fields = {"fileName","fileContext"}; //从文件名称和文件内容中查询,只有含有apache的就查出来 MultiFieldQueryParser multiQuery = new MultiFieldQueryParser(fields, analyzer); //输入需要搜索的关键字 Query query = multiQuery.parse("apache"); //指定索引和文档的目录 Directory dir = FSDirectory.open(new File("E:\dic")); //索引和文档的读取对象 IndexReader indexReader = IndexReader.open(dir); //创建索引的搜索对象 IndexSearcher indexSearcher = new IndexSearcher(indexReader); //搜索:第一个参数为查询语句对象, 第二个参数:指定显示多少条 TopDocs topdocs = indexSearcher.search(query, 5); //一共搜索到多少条记录 System.out.println("=====count=====" + topdocs.totalHits); //从搜索结果对象中获取结果集 ScoreDoc[] scoreDocs = topdocs.scoreDocs; for(ScoreDoc scoreDoc : scoreDocs){ //获取docID int docID = scoreDoc.doc; //通过文档ID从硬盘中读取出对应的文档 Document document = indexReader.document(docID); //get域名可以取出值 打印 System.out.println("fileName:" + document.get("fileName")); System.out.println("fileSize:" + document.get("fileSize")); System.out.println("============================================================"); } }