MySQL数据库的日志系统共有三种日志,具有不同的作用,承担着不同的角色,共同保障数据库的稳定。它们分别是redo log(重做日志,用于断电后数据的灾后恢复),bin log(归档日志,用于将数据恢复到之前任意时间节点的状态)以及undo log(用于事务提交前的数据回滚)。本文主要对MVCC及undo log进行详细的说明。
- 概念
MVCC的全称是 multi version concurrency control ,即多版本并发控制,通过undo log进行实现, 是innodb实现事务并发与回滚的重要功能。
1.1我们首先需要明确undo log是什么?
undo log不同于binlog和redo log,binlog采用的是逻辑记法,row模式记录的是行的内容,修改前后都有,记两条;statement模式记录的是sql语句。
redo log采用的是逻辑+物理记法,专业术语称为physiological logging,即先记录innnodb需要修改的page页,在对page页里面内容采用逻辑记法,记录page里的哪一行被修改了。
Undo log指的是在对表中的数据进行修改前,需要先把原数据写入undo log日志。对于insert而言,由于原来没有历史数据,所以只需要把该记录的主键ID记入undo log;update和delete则需要将历史数据记入undo log。
Undo log更应该称为记录的备份数据,即在事务未提交之前的时间里的备份数据,一旦事务提交后,没有其它事务引用历史版本了,其对应的undo log也就可以删除了。Undo log的实现原理会在后面进行详述。
1.2我们应该知道为什么需要undo log?
因为若某事务对内存中的某条记录进行修改,其它事务使用该记录时,完全可以从磁盘中取得原始记录。首先是因为page刷盘的策略决定的,如表1-1所示。
表1-1 page刷盘的四种策略
|
未提交事务可以 写入磁盘 已提交事务 必须立刻写入磁盘 |
否 |
是 |
|
是 |
不需要日志 |
Undo log |
|
否 |
Redo log |
Redo log+ Undo log |
由于innodb采用的是第四种策略,未提交的数据也可以刷入磁盘,你不能确定盘中的数据是否为脏数据。
其次,就算能确定磁盘中的数据是否为脏数据,事务将记录读入内存会进行随机IO,影响IO的读取效率,采用undo log将历史数据先写内存,在异步刷入磁盘,都是顺序IO,因此提高了IO效率,redo log也是同理。
-
undo log实现原理
innodb表中记录除了主键ID和列数据外,还有两个隐藏字段。一个叫做DB_TRX_ID,用于记录事务的ID;一个是DB_ROLL_PTR,记录上条记录在undo log中的地址。如下图所示:
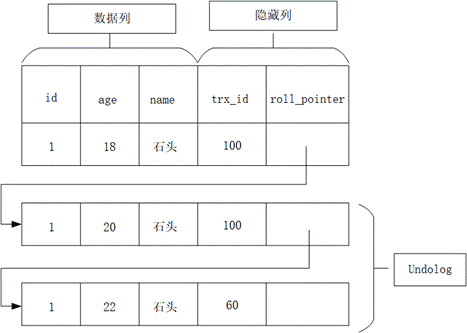
图2-1undo log原理图
如图所示,数据库中的每条记录只要被事务修改,就会将原来的历史数据写入undo log中,因此多个事务是随机向undo log中并行写入的,每条记录都会形成一个版本链。而某一个事务在读取该行记录时是如何知道自己需要读取的版本的?这是通过readview来判断的,设定了判断规则得到事务需要获取的版本。