当我们从数据库中获取一写数据后,一般对于列表的排序是经常会遇到的问题,今天总结一下python对于列表list排序的常用方法:
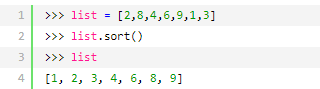
第一种:内建方法sort()
可以直接对列表进行排序
用法:
list.sort(func=None, key=None, reverse=False(or True))
- 对于reverse这个bool类型参数,当reverse=False时:为正向排序;当reverse=True时:为方向排序。默认为False。
- 执行完后会改变原来的list,如果你不需要原来的list,这种效率稍微高点
- 为了避免混乱,其会返回none
例如
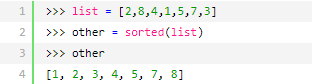
第二种:内建函数sorted()
这个和第一种的差别之处在于:
- sorted()不会改变原来的list,而是会返回一个新的已经排序好的list
- list.sort()方法仅仅被list所定义,sorted()可用于任何一个可迭代对象
用法:
sorted(list)
- 该函数也含有reverse这个bool类型的参数,当reverse=False时:为正向排序(从小到大);当reverse=True时:为反向排序(从大到小)。当然默认为False。
- 执行完后会有返回一个新排序好的list
例如:
扩展用法:
1.Key Function:
从Python2.4开始,list.sort() 和 sorted() 都增加了一个 ‘key’ 参数用来在进行比较之前指定每个列表元素上要调用的函数。
例如:
区分大小写的字符串比较排序:
>>> sorted("This is a test string from Andrew".split(), key=str.lower) ['a', 'Andrew', 'from', 'is', 'string', 'test', 'This']
key应该是一个函数,其接收一个参数,并且返回一个用于排序依据的key。其执行效率很高,因为对于输入记录key function能够准确的被调用。
对于复杂的对象,使用对象的下标作为key。
例如:
>>> student_tuples = [ ... ('john', 'A', 15), ... ('jane', 'B', 12), ... ('dave', 'B', 10), ... ] >>> sorted(student_tuples, key=lambda student: student[2]) # sort by age [('dave', 'B', 10), ('jane', 'B', 12), ('john', 'A', 15)]
使用对象的属性进行操作:
例如:
>>> class Student: ... def __init__(self, name, grade, age): ... self.name = name ... self.grade = grade ... self.age = age ... def __repr__(self): ... return repr((self.name, self.grade, self.age)) >>> >>> student_objects = [ ... Student('john', 'A', 15), ... Student('jane', 'B', 12), ... Student('dave', 'B', 10), ... ] >>> sorted(student_objects, key=lambda student: student.age) # sort by age [('dave', 'B', 10), ('jane', 'B', 12), ('john', 'A', 15)]
前段时间遇到这种情况,那就是列表里面每一个元素不止一个元素(比如:列表里面,元素为元祖类型),我们除了想对第一个关键字排序之外,还想在第一次的基础上面根据第二个关键字进行排序,正好是用到的这种方法:
简化出一个例子:
我们想先排序列表list中元素的第一个关键字,然后在第一个元素的基础上排序按第二个关键字进行排序,看结果:
>>> list = [('d',3),('a',5),('d',1),('c',2),('d',2)] >>> print sorted(list, key = lambda x:(x[0],x[1])) [('a', 5), ('c', 2), ('d', 1), ('d', 2), ('d', 3)]
2.Operator Module Functions
2.Operator Module Functions
这个操作模块有:
operator.itemgetter() ----- 通过下标operator.attrgetter() ----- 通过参数operator.methodcaller() -----python 2.5 被引入,下文详细介绍
使用这几个函数,对于上面 Key Function 的例子处理起来将会更加的简便和快速
先一块介绍 operator.itemgetter() 和 operator.attrgetter() 这俩个,会更加容易理解:
例如:
>>> from operator import itemgetter, attrgetter >>> >>> sorted(student_tuples, key=itemgetter(2)) [('dave', 'B', 10), ('jane', 'B', 12), ('john', 'A', 15)] >>> >>> sorted(student_objects, key=attrgetter('age')) [('dave', 'B', 10), ('jane', 'B', 12), ('john', 'A', 15)]
这个操作模块也允许多层次的进行排序,例如可以先排序 “成绩grand” 再排序 “年龄age”
例如:
>>> sorted(student_tuples, key=itemgetter(1,2)) [('john', 'A', 15), ('dave', 'B', 10), ('jane', 'B', 12)] >>> >>> sorted(student_objects, key=attrgetter('grade', 'age')) [('john', 'A', 15), ('dave', 'B', 10), ('jane', 'B', 12)]
现在回过头来发现,上面在前几天遇到的问题,可以用这个operator.itemgetter进行解决:
>>> list = [('d',3),('a',5),('d',1),('c',2),('d',2)] >>> from operator import itemgetter >>> sorted(list, key=itemgetter(0,1)) [('a', 5), ('c', 2), ('d', 1), ('d', 2), ('d', 3)]
但是还是推荐 1.key function 中的方法,因为为了这一个排序而引入一个库文件,相对来说得不偿失。
下面介绍operator.methodcaller() 函数:
这个函数是对某个对象的使用固定参数进行排序,例如:str.count() 函数可以计算每个字符串对象中含有某个参数的个数,那运用这个函数我就可以通过 str.count() 计算出某个字符的个数从而来确定排序的优先级:
>>> from operator import methodcaller >>> messages = ['critical!!!', 'hurry!', 'standby', 'immediate!!'] >>> sorted(messages, key=methodcaller('count', '!')) ['standby', 'hurry!', 'immediate!!', 'critical!!!']
3.注意事项:
排序的稳定性:
从python2.2版本开始,排序是保障稳定性的,意思就是说,当复杂的排序中,对象有相同的key的时候,会保持原有的顺序不变:
例如:
>>> data = [('red', 1), ('blue', 1), ('red', 2), ('blue', 2)] >>> sorted(data, key=itemgetter(0)) [('blue', 1), ('blue', 2), ('red', 1), ('red', 2)]
可以看到,('blue',1) 和 (‘blue’,2) 的顺序还是维持原来那样不改变。 复杂排序: 这个排序的属性可以让你在一系列的步骤中构建复杂的排序操作。例如上面的例子,排序中,我想先通过 “成绩grand” 进行降序操作,然后再通过“年龄age” 进行升序操作,首先先通过 “年龄age” 排序,然后再通过 “成绩grand” 排序:
>>> s = sorted(student_objects, key=attrgetter('age')) # sort on secondary key >>> sorted(s, key=attrgetter('grade'), reverse=True) # now sort on primary key, descending [('dave', 'B', 10), ('jane', 'B', 12), ('john', 'A', 15)]
4.新增的问题:
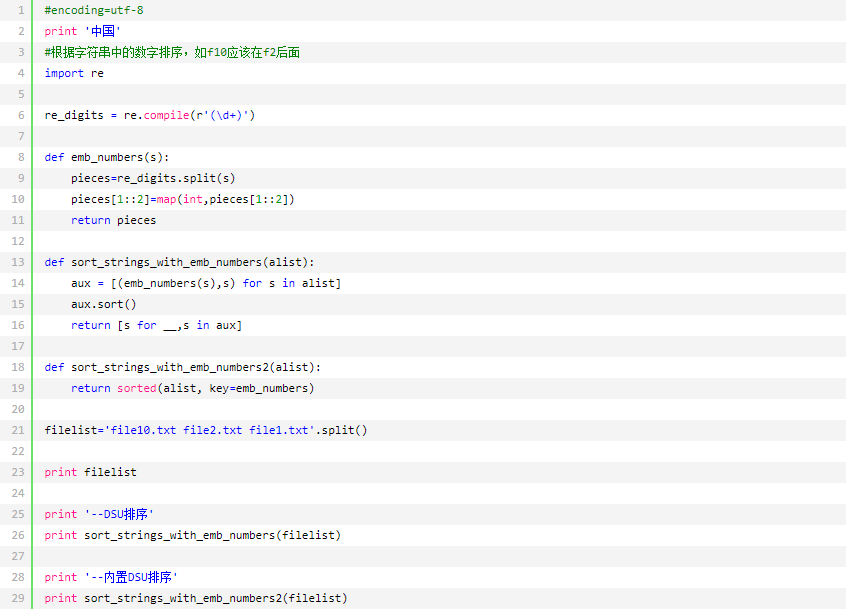
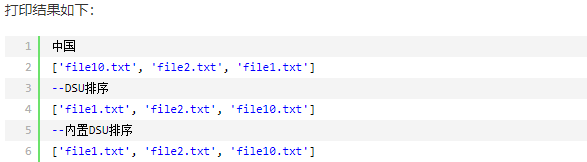
今天遇到了这么一个问题,就是遇到一个字符串的处理问题,比如说 f10 得排在 f2 的后面。找到了这么一种方法,供参考:
参考地址:http://blog.csdn.net/houyj1986/article/details/22966799