目录
2.5 列表(list)
2.5.1 索引和切片
列表的索引和切片,用法和字符串的索引和切片一模一样,区别在于,面临二维或多维列表时,会有多重索引和切片,思路就是「一层一层往里剥」。
L = [1, 2, 3, 4, [9, 8, 7, 6]]
len(L)
L[4]
L[4][1]
L[4][::-1]
2.5.2 常用方法
2.5.2.1 添加元素
| 方法 | 含义 | 原地操作? |
|---|---|---|
| append(x) | 将元素x添加至列表尾部 | 是 |
| extend(L) | 将列表L中所有元素添加至列表尾部 | 是 |
| insert(index, x) | 在列表指定位置index处添加元素x,该位置后面元素后移一位 | 新生成 |
| + | 添加元素至列表尾部 | 新生成 |
| * | 拼接字符串 | 新生成 |
alist = [1, 2, 3]
blist = [4, 5, 6]
alist.extend(blist) # blist添加至alist后面,原地操作
alist
alist.append(blist)
alist
# append和+的区别
import time
result = []
start = time.time() # 返回当前时间
for i in range(10000): # 创建一个整数列表
result = result + [i]
print('+添加:', time.time()-start) # 打印列表长度,并计算耗时
result = []
start = time.time()
for i in range(10000):
result.append(i)
print('Append:', time.time()-start)
# append和insert区别
import time
a = []
start = time.time()
for i in range(100000):
a.insert(0, i)
print('Insert:', time.time()-start) # 新生成
a = []
start = time.time()
for i in range(100000):
a.append(i)
print('Append:', time.time()-start) # 原地操作
L = [1, 2, 3, 4, 5, 6]
L*3 # 通过乘实现复制
2.5.2.2 删除元素
| 方法 | 含义 | 原地操作? |
|---|---|---|
| remove(x) | 删除首次出现的指定元素x | 是 |
| pop(index) | 删除指定index元素,并返回该元素的值,index默认-1 | 是 |
| clear(index) | 删除列表中所有元素,保留列表对象 | 是 |
| del | 删除列表中元素或整个列表 | / |
| 赋值 | 对列表中元素或整个列表进行赋值,也算一种删除 | 是 |
拓展:删除列表重复元素有两种思路:
- for循环中的i基于内容去遍历,用i in list[:]
- for循环中的i基于index去遍历,用i in range(len(list)-1, -1, -1)
L = [1, 2, 3, 4, 4, 5, 6]
L.remove(4) # 原地操作
L
# 删除重复元素法1
x = [3, 4, 5, 5, 6]
for i in x[:]: # 采用切片的方式
print(i)
if i == 5:
x.remove(i)
print(x)
# 删除重复元素法2
x = [3, 4, 5, 5, 6]
for i in range(len(x)-1, -1, -1): # 从后向前的顺序
print(i)
if x[i] == 5:
del x[i]
print(x)
L = [2, 3, 4, 5]
L.pop(2) # 实现两个功能:取出4,把4从原列表删除
L = [2, 3, 4, 5]
L.clear()
L
L = [1, 2, 3, 4, 5]
id(L)
L[0:2] = [6, 6] # 修改多个元素
L
id(L)
L = [1, 2, 3, 4, 5]
del L[1] # 删除第一个
L
del L # 删除整个列表
L
2.5.2.3 计算&排序
| 方法 | 含义 | 原地操作? |
|---|---|---|
| index(x) | 返回列表中第一个值为x元素的下标,若不存在则抛出异常 | / |
| count(x) | 返回指定元素x在列表中出现的次数 | / |
| reverse() | 对列表所有元素进行逆序 | 是 |
| sort(key=,reverse=) | 对列表元素进行排序,key指定排序依据,reverse决定升序降序:True降序、False升序 | 是 |
需要注意,reverse方法和sort方法,都有对应的排序函数:
| 函数 | 含义 | 原地操作? |
|---|---|---|
| reversed(L) | 对列表L所有元素进行逆序,返回是一个迭代器,需要list化显示 | 是 |
| sorted(list, key=, reverse=) | 对列表元素进行排序,key指定排序依据,reverse决定升序降序:True降序、False升序 | 新生成 |
且无论是在sort还是sorted排序中,参数key通常采用匿名函数「lambda」。
x = [3, 4, 5, 6]
x.index(5) # 返回索引,不存在则报错
x.count(10) # 没有返回0,不会报错
x.reverse() # 原地逆序
x
x = [2, 3, 1, 5, 8]
x.sort() # 默认是升序
x
x.sort(reverse=True) # 降序
x
# 自定义排序,使用匿名函数
aList = [[3, 4], [15], [11, 9, 17, 13], [6, 7, 5]]
aList.sort(key=lambda x: len(x), reverse=True) # 按长度排序,lambda函数,匿名函数
aList
x = [1, 2, 3, 4, 5]
list(reversed(x)) # 新生成
student = [['john', 'A', 15], ['jane', 'B', 12], ['dave', 'B', 10]] # 按值进行排序
sorted(student, key=lambda a: a[2], reverse=True)
2.5.2.4 类型转换
字符串和列表经常互相转换,具体方法是list和join:
- 函数
list(str):把字符串转化为列表 - 方法
' '.join(L):把列表转化为字符串
s = 'abcd'
list(s)
x = ['apple', 'peach', 'banana', 'peach', 'pear']
'/'.join(x)
2.5.2.5 复制
常见的复制有三种:赋值、浅拷贝、深拷贝,三者在使用和表现上都存在区别。
2.5.2.5.1 赋值
赋值操作是复制了引用指针,所以数据一方改变,必然导致另一方变化,原理见下图:
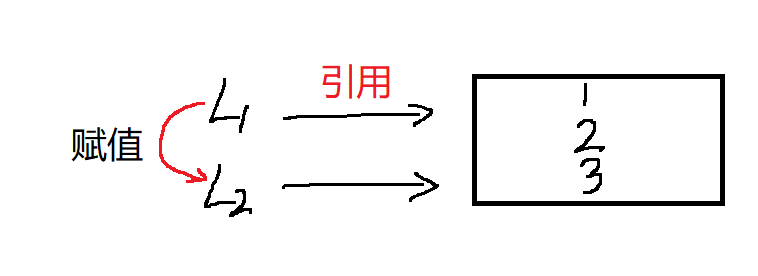
# 实质是复制了引用:一方改变,必然导致另一方变化
L1 = [1, 2, 3, 4]
id(L1)
L2 = L1
L2[0] = 0
L2
id(L2)
L1
2.5.2.5.2 浅拷贝
浅拷贝有4种形式,而不同维度的数据,在浅拷贝后数据的变化也不尽相同,需要分开讨论,原理见下图及代码:
copy()方法- 使用列表生成式
- 用for循环遍历
- 切片
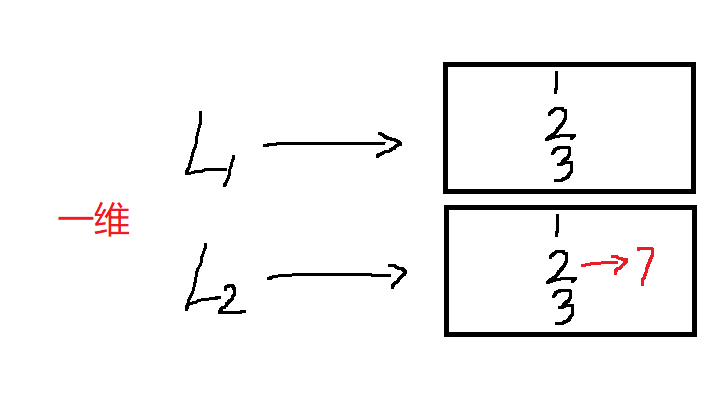

# 一维:原来值和浅拷贝值互不影响
L1 = [1, 2, 3, 4]
L2 = L1[:]
L2[0] = 0
L2
L1
# 二维或多维:分两种情况讨论
x = [1, 2, 3, [4, 5, 6]]
y = x[:]
y[0] = 0 # 复杂子对象不改变:原来值和浅拷贝值互不影响
y
x
x = [1, 2, 3, [4, 5, 6]]
y = x[:]
y[3][2] = 10 # 复杂子对象改变:原来值和浅拷贝值互相影响
y
x
2.5.2.5.3 深拷贝
- 深拷贝是完全的拷贝,原来值和深拷贝值互不影响
- 使用
copy模块中的deepcopy()方法生成
import copy
L1 = [1, 2, 3, [4, 5]]
L2 = copy.deepcopy(L1)
L2[0] = 0
L2
L1 # 原来值和深拷贝值互不影响
2.5.3 内置函数
| 函数 | 含义 | 是否新生成 |
|---|---|---|
| len() | 返回列表中的元素个数 | / |
| max()、min() | 返回列表中的最大、最小元素 | / |
| sum() | 对列表元素进行求和运算 | / |
| zip() | 将多个列表对应位置的元素组合成元组,返回可迭代的zip对象 | 是 |
| enumerate() | 枚举列表元素,返回元组迭代器,元组中元素包含列表下标、元素的值 | 是 |
L = [1, 2, 3, 4, 5, 6]
sum(L)
L1 = ['a', 'b', 'c']
L2 = [1, 2, 3]
list(zip(L1, L2)) # 生成的是元组迭代器
# 把下标和值打印出来
L1 = ['a', 'b', 'c']
for i, j in enumerate(L1):
print(i, j)
2.5.4 列表推导式
- 阅读:先看第一个for,再看第二个for,再看条件判断(if),最后看输出结果(表达式)
- 格式:
- [表达式 for 变量 in 列表]
- [表达式 for 变量 in 列表 if 条件]
- 作用:
- 实现嵌套列表的平铺
- 过滤不符合条件的元素
- 使用多个循环实现多序列元素的任意组合
- 实现矩阵转置
- 使用函数或复杂表达式
- 实现向量的运算
# 用for循环实现
L1 = [1, 2, 3, 4, 5]
L3 = []
for i in L1:
L3.append(i**2)
L3
L1 = [1, 2, 3, 4, 5]
[i**2 for i in L1] # 列表推导式
squar1 = map(lambda x: x**2, L1) # 用map函数实现对L1的指定映射
list(squar1)
# 列表推导式,加上判断条件
L1 = [1, 2, 3, 4, 5]
[i**2 for i in L1 if i > 2]
[[i, j] for i in range(10) for j in range(10) if i == j]
L1 = [1, 2, 3, 4]
L2 = [4, 5, 6, 7]
[L1[i]+L2[i] for i in range(len(L1))]
L1 = [1, 2, 3, 4]
L2 = [4, 5, 6, 7]
[L1[i]+L2[j] for i in range(len(L1)) for j in range(len(L2)) if i == j]
2.6 字典(dictionary)
2.6.1 创建
字典有三种创建方式:
- 直接赋值创建
- 用
dict()函数创建 - 通过给定键值对创建
# 直接赋值创建
addresbook1 = {"小明": "1521055", "小华": "1872345", "小芳": "1389909"}
addresbook1
# 用dict()函数创建
alist = [1, 2, 3]
blist = ['a', 'b', 'c']
dict(zip(alist, blist)) # 将多个列表对应位置的元素组合成元组,返回可迭代的zip对象
# 通过给定键值对创建
dict(name='小明', age=20) # 等号前是键,等号后是值
2.6.2 读取
读取原理:通过key访问value。
| 方法 | 含义 |
|---|---|
| [key] | 以键作为下标读取元素,若不存在则抛出异常 |
| get(x[,y]) | 通过键x访问字典:若x存在返回对应的值;若x不存在返回none;若指定了y则x不存在返回y |
| keys() | 返回键的列表 |
| values() | 返回值的列表 |
| items(x) | 返回元组组成的列表,每个元组由字典的键和相应值组成 |
| copy() | 对字典进行浅复制 |
| clear() | 删除字典所有元素,保留空字典 |
addressbook1 = {"小华": "1872345", "小明": "1521055", "小芳": "1389909"}
addressbook1["小明"] # 通过key访问value
addresbook1.get('小明') # 存在key时,返回对应的值
addresbook1.get('小红') # 不存在key时,返回none
addresbook1.get('小红', 110) # 不存在key时,返回指定的值
addresbook1.keys()
addresbook1.values()
addresbook1.items()
addresbook1.clear()
addresbook1
2.6.3 添加与修改
| 方法 | 含义 |
|---|---|
| update() | 更新信息:把一个字典的键值对添加到另一字典中去,若存在相同的key,则用后者覆盖 |
| pop() | 删除指定key,并返回key对应的值 |
| 指定键为字典赋值 | 若键存在则修改键的值,若键不存在则新增键值对 |
| 值为可变数据类型 | 可进行相应数据类型的操作 |
addresbook1 = {"小明": "1521055", "小华": "1872345", "小芳": "1389909"}
addresbook1['小红'] = '378598345' # 指定键为字典赋值
addresbook1
# 更新信息,若第一个字典的key在第二个字典也存在,则值以第二个字典的为准
addresbook1 = {"小明": "1521055", "小华": "1872345", "小芳": "1389909"}
addresbook2 = {"小华": "23462346", "小李": "0346246457"}
addresbook1.update(addresbook2)
addresbook1
# pop用法和作用同列表中pop一样
addresbook1 = {"小明": "1521055", "小华": "1872345", "小芳": "1389909"}
addresbook1.pop('小明')
addresbook1
# 值可以为可变序列
addresbook1 = {"小明": "1521055", "小华": "1872345",
"小芳": [1389909, 1895436, 2748579]}
addresbook1
addresbook1["小芳"].append(9999999)
addresbook1
2.6.4 字典推导式
字典推导式语法类似于列表推导式,可快速生成符合指定条件的字典,只是外面是{ }。
# 生成键为序号,值为字符串的字典
{i: str(i) for i in range(5)}
# 将两个序列关联生成,生成字典
x = ['A', 'B', 'C', 'D']
y = ['a', 'b', 'b', 'd']
{x[i]: y[i] for i in range(len(x))}
{i: j for i, j in zip(x, y)}
# 随机产生1000个字符,统计字符次数
import string # 导入string模块
import random # 导入random模块
x = string.ascii_letters + string.digits + string.punctuation # 生成字符串
y = [random.choice(x) for i in range(1000)] # 列表推导式
d = dict()
for ch in y:
d[ch] = d.get(ch, 0) + 1 # 不断统计,更新键的值,之前没有值则计1,有则取出加1
d
scores = {"Zhang San": 45, "Li Si": 78, "Wang Wu": 40, "Zhou Liu": 96,
"Zhao Qi": 65, "Sun Ba": 90, "Zheng Jiu": 78, "Wu Shi": 99, "Dong Shiyi": 60}
scores.values()
max(scores.values()) # 最高分
min(scores.values()) # 最低分
sum(scores.values())/len(scores) # 平均分
[name for name, score in scores.items() if score == max(scores.values())] # 最高分同学
[name for name, score in scores.items() if score > (
sum(scores.values())/len(scores))] # 高于平均分同学
2.7 集合(set)
集合最大的应用场景,就是「去重」。
2.7.1 创建
集合有两种常见创建方式:
- 直接赋值创建
set(x)函数创建
a = {1, 2, 3, 4} # 直接赋值创建
a
b = [5, 6, 7, 8] # set()函数创建
set(b)
2.7.2 基本操作
基本操作共有4种:交集(&)、并集(|)、差集(-)、补集(^)。
a = {1, 2, 3, 4}
b = {2, 3}
a & b
a | b
a - b
a ^ b
2.7.3 包含关系测试
包含关系测试常用于两集合关系判断,返回布尔值。
| 方法 | 含义 |
|---|---|
| x.issubset(y) | 判断x是否为y子集 |
| {x}.isdisjoint({y}) | 判断x与y是否没有交集 |
| 用>或<比较大小 | 判断是否是子集 |
a = {1, 2, 3, 4}
b = {2, 3}
b.issubset(a)
b.isdisjoint(a)
a > b
b < a
2.7.4 常用函数和方法
| 方法 | 含义 |
|---|---|
| add(x) | 如果x不在集合中,将x增加到集合 |
| clear() | 移除集合中所有元素 |
| copy() | 浅拷贝 |
| pop() | 随机返回集合中的一个元素,若集合为空则报错 |
| discard(x) | 若x在集合中,移除x;若x不存在,不报错 |
| remove(x) | 若x在集合中,移除x;若x不存在,报错 |
| x in S | 判断x是否是集合S元素 |
| x not in S | 判断x是否不是集合S元素 |
| 函数 | 含义 |
| len() | 返回集合元素个数 |
a = {1, 2, 3, 4}
a.add(5)
a
b=a.copy() # 浅拷贝
b
3 not in b
len(b)