教材学习内容总结
虚拟存储器
- 虚拟存储器是计算机系统最重要的概念之一,它是对主存的一个抽象
-
虚拟存储器的三个重要能力:
•它将主存看成是一个存储在磁盘上的地址空间的高速缓存,在主存中只保存活动区域,并根据需要在磁盘和主存之间来回传送数据,通过这种方式,高效的使用了主存 •它为每个进程提供了一致的地址空间,从而简化了存储器管理 •它保护了每个进程的地址空间不被其他进程破坏
物理和虚拟寻址
- 计算机系统的主存被组织成一个由M个连续的字节大小的单元组成的数组,每字节都有一个唯一的物理地址PA。
- 根据物理地址寻址的是物理寻址。
- 虚拟存储器被组织为一个由存放在磁盘上的N个连续的字节大小的单元组成的数组。
- 使用虚拟寻址时,CPU通过生成一个虚拟地址VA来访问主存,这个虚拟地址在被送到存储器之前先转换成适当的物理地址(这个过程叫做地址翻译,相关硬件为存储器管理单元MMU)
地址空间
- 地址空间是一个非负整数地址的有序集合:{0,1,2,……}
- 线性地址空间:地址空间中的整数是连续的。
- 虚拟地址空间:CPU从一个有 N=2^n 个地址的地址空间中生成虚拟地址,这个地址空间成为称为虚拟地址空间。
- 地址空间的大小由表示最大地址所需要的位数来描述。N=2^n:n位地址空间
- 主存中的每个字节都有一个选自虚拟地址空间的虚拟地址和一个选自物理地址空间的物理地址。
虚拟存储器作为缓存的工具
- 虚拟存储器——虚拟页VP,每个虚拟页大小为P=2^平字节
- 物理存储器——物理页PP,也叫页帧,大小也为P字节。
-
任意时刻,虚拟页面的集合都被分为三个不相交的子集:
•未分配的:VM系统还没分配/创建的页,不占用任何磁盘空间。 •缓存的:当前缓存在物理存储器中的已分配页 •未缓存的:没有缓存在物理存储器中的已分配页DRAM缓存的组织结构
-
需要知道,这种缓存结构:
•不命中处罚很大 •是全相联的——任何虚拟页都可以放在任何的物理页中。 •替换算法精密 •总是使用写回而不是直写。页表
- 页表是一个数据结构,存放在物理存储器中,将虚拟页映射到物理页
-
页表就是一个页表条目PTE的数组,组成为:
有效位+n位地址字段 - 如果设置了有效位:地址字段表示DRAM中相应的物理页的起始位置,这个物理页中缓存了该虚拟页
-
如果没有设置有效位:
(1)空地址: 表示该虚拟页未被分配 (2)不是空地址: 这个地址指向该虚拟页在磁盘上的起始位置。缺页
- 缺页:就是指DRAM缓存不命中。
- 缺页异常:会调用内核中的缺页异常处理程序,选择一个牺牲页。
- 页:虚拟存储器的习惯说法,就是块
- 交换=页面调度:磁盘和存储器之间传送页的活动
-
按需页面调度:直到发生不命中时才换入页面的策略,所有现代系统都使用这个。
虚拟存储器中的局部性
- 局部性原则保证了在任意时刻,程序将往往在一个较小的活动页面集合上工作,这个集合叫做工作集/常驻集
- 所以只要程序有良好的时间局部性,虚拟存储器系统就能工作的相当好
-
颠簸:工作集大小超出了物理存储器的大小
虚拟存储器作为存储器管理的工具
- 操作系统为每个进程提供了一个独立的页表,也就是一个独立的虚拟地址空间
- 抖个虚拟页面可以映射到同一个共享物理页面上。
- 存储器映射:将一组连续的虚拟页映射到任意一个文件中的任意位置的表示法
- VM简化了链接和加载、代码和数据共享,以及应用程序的存储器分配
虚拟存储器作为存储器保护的工具
-
PTE的三个许可位:
•SUP:表示进程是否必须运行在内核模式下才能访问该页 •READ:读权限 •WRITE:写权限
地址翻译
-
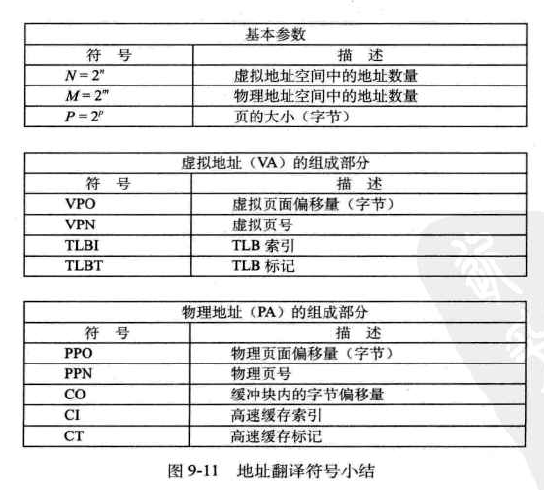
- 地址翻译就是一个N元素的虚拟地址空间VAS中的元素和一个M元素的物理地址空间PAS中元素之间的映射
- 页面基址寄存器PTBR指向当前页表
- MMU利用VPN选择适当的PTE
- PPO=VPO
-
当页面命中时,CPU动作:
•处理器生成虚拟地址,传给MMU •MMU生成PTE地址,并从高速缓存/主存请求得到他 •高速缓存/主存向MMU返回PTE •MMU构造物理地址,并把它传给高速缓存/主存 •高速缓存/主存返回所请求的数据给处理器 -
处理缺页时:
•处理器生成虚拟地址,传给MMU •MMU生成PTE地址,并从高速缓存/主存请求得到他 •高速缓存/主存向MMU返回PTE •PTE中有效位为0,触发缺页异常 •确定牺牲页 •调入新页面,更新PTE •返回原来的进程,再次执行导致缺页的指令,会命中结合高速缓存和虚拟存储器来看
- 首先,在既使用SRAM高速缓存又使用虚拟存储器的系统中,大多数系统选择物理寻址
- 主要思路是地址翻译发生在高速缓存之前
-
页表目录可以缓存,就像其他的数据字一样
利用TLB加速地址翻译
-
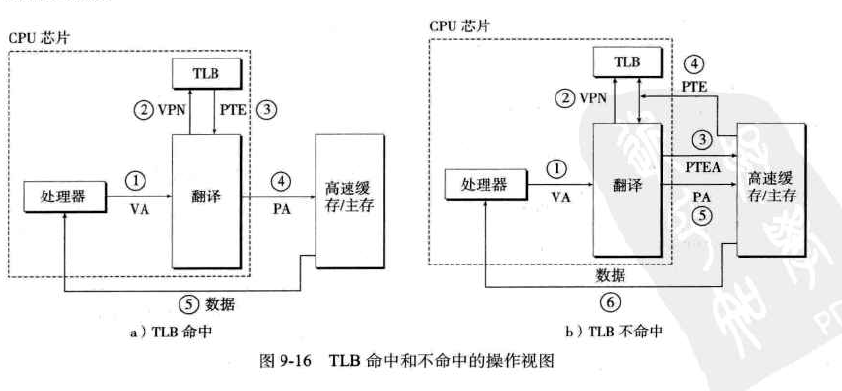
TLB:翻译后备缓冲器,是一个小的、虚拟存储的缓存,其中每一行都保存着一个由单个PTE组成的块
-
步骤:
•CPU产生一个虚拟地址 •MMU从TLB中取出相应的PTE •MMU将这个虚拟地址翻译成一个物理地址,并且将它发送到高速缓存/主存 •高速缓存/主存将所请求的数据字返回给CPU多级页表
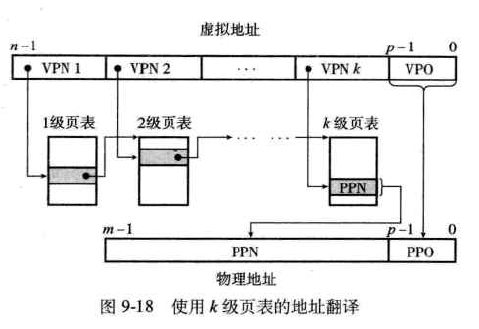
- 多级页表——采用层次结构,用来压缩页表
-
以两层页表层次结构为例,好处是:
•如果一级页表中的一个PTE是空的,那么相应的二级页表就根本不会存在 •只有一级页表才需要总是在主存中,虚拟存储器系统可以在需要时创建、页面调入或调出二级页表,只有最经常使用的二级页表才缓存在主存中。 -
多级页表的地址翻译:
案例研究
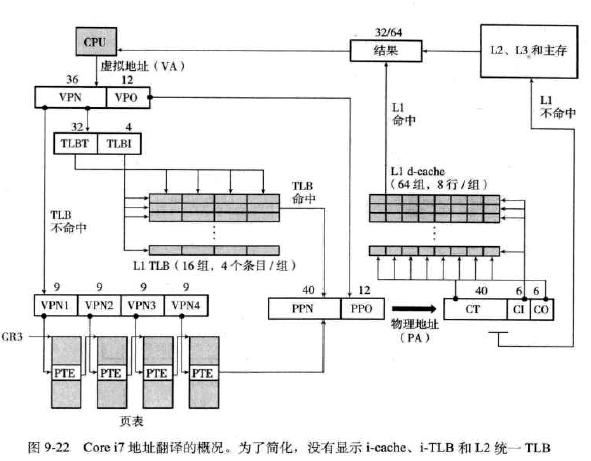
###Core i7地址翻译-
-
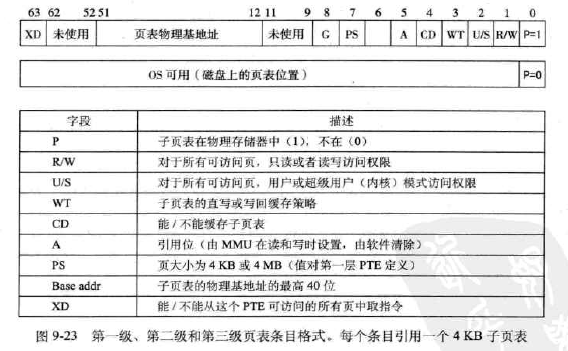
-
PTE有三个权限位:
•R/W位:确定内容是读写还是只读 •U/S位:确定是否能在用户模式访问该页 •XD位:禁止执行位,64位系统中引入,可以用来禁止从某些存储器页取指令 -
缺页处理程序涉及到的位:
•A位,引用位,实现页替换算法 •D位,脏位,告诉是否必须写回牺牲页Linux虚拟存储器系统
-
Linux为每个进程维持了一个单独的虚拟地址空间,如图:
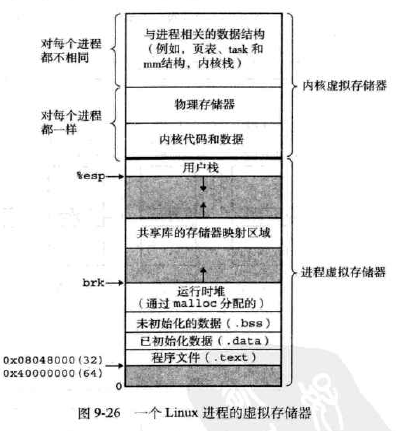
- 内核虚拟存储器包括:内核中的代码和数据结构
- 一部分区域映射到所有进程共享的物理页面,另一部分包含每个进程都不相同的数据。
- 区域:就是已分配的虚拟存储器的连续片
-
区域的例子:
•代码段 •数据段 •堆 •共享库段 •用户栈 •…… - 每个存在的虚拟页面都保存在某个区域中。内核为系统中的每个进程维护一个单独的任务结构task_struct
-
一个具体区域的区域结构包括:
•vm_start:指向起始处 •vm_end:指向结束处 •vm_prot:描述这个区域包含的所有页的读写许可权限 •vm_flags:是共享的还是私有的 •vm_next:指向下一个区域
存储器映射
- 即指Linux通过将一个虚拟存储器区域与一个磁盘上的对象关联起来,以初始化这个虚拟存储器区域的内容的过程。
-
映射对象:
1.Unix文件系统中的普通文件 2.匿名文件(全都是二进制0)共享对象和私有对象
- 共享对象对于所有把它映射到自己的虚拟存储器进程来说都是可见的。即使映射到多个共享区域,物理存储器中也只需要存放共享对象的一个拷贝。
- 私有对象运用的技术:写时拷贝。在物理存储器中只保存有私有对象的一份拷贝
-
fork函数就是应用了写时拷贝技术,至于execve函数
使用mmap函数的用户级存储器映射
-
创建新的虚拟存储器区域
void *mmap(void *start, size_t length, int prot, int flags, int fd, off_t offset); 成功返回指向映射区域的指针,若出错则为- -
删除虚拟存储器:
int munmap(void *start, size_t length); 成功返回0,失败返回-1 -
从start开始删除,由接下来length字节组成的区域
动态存储器分配
- 堆是一个请求二进制0的区域,紧接在未初始化的bss区域后开始,并向上(更高的地址)生长。有一个变量brk指向堆的顶部
-
分配器的两种基本风格:
1.显示分配器-malloc和free 2.隐式分配器/垃圾收集器malloc和free函数
-
系统调用malloc函数,从堆中分配块:
void *malloc(size_t size); 成功返回指针,指向大小至少为size字节的存储器块,失败返回NULL -
系统调用free函数来释放已分配的堆块:
void free(void *ptr); 无返回值 - ptr参数必须指向一个从malloc、calloc或者reallov获得的已分配块的起始位置
-
使用动态存储器分配是因为经常知道程序实际运行时,它们才知道某些数据结构的大小
分配器的要求和目标
-
要求
•处理任意请求序列 •立即响应请求 •只使用堆 •对齐块 •不修改已分配的块 -
目标
•最大化吞吐率(吞吐率:每个单位时间里完成的请求数) •最大化存储器利用率——峰值利用率最大化碎片
- 虽然有未使用的存储器,但是不能用来满足分配请求时,发生这种现象
- 内部碎片发生在一个已分配块比有效载荷大的时候。易于量化。
-
外部碎片发生在当空闲存储器合计起来足够满足一个分配请求,但是没有一个单独的空间块足以处理这个请求时发生。难以量化,不可预测。
隐式空闲链表
-
堆块的格式:由一个字的头部,有效荷载,和可能的额外填充组成。
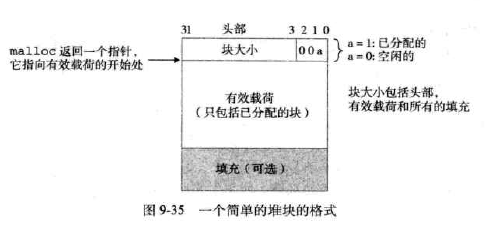
-
将堆组织成一个连续的已分配块和空闲块的序列:
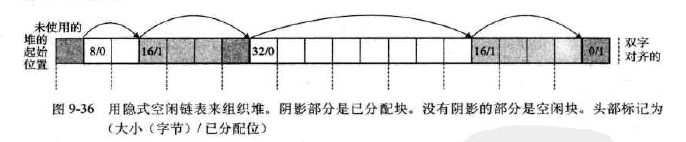
- 空闲块通过头部中的大小字段隐含地连接着,分配器可以通过遍历堆中所有的块,从而间接地遍历整个空闲块的集合。
- 需要:特殊标记的结束块。
-
系统对齐要求和分配器对块格式的选择会对分配器上的最小块大小有强制的要求。
放置已分配的块——放置策略
- 首次适配:从头开始搜索空闲链表,选择第一个合适的空闲块
- 下一次适配:从上一次搜索的结束位置开始搜索
-
最佳适配:检索每个空闲块,选择适合所需请求大小的最小空闲块
申请额外的堆存储器
-
sbrk函数:
void *sbrk(intptr_t incr); 成功则返回旧的brk指针,出错为-1 -
通过将内核的brk指针增加incr来扩展和收缩堆。
合并空闲块
- 合并是针对于假碎片问题的,任何实际的分配器都必须合并相邻的空闲块。
-
有两种策略:
•立即合并 •推迟合并带边界的合并
-
合并的意思是,因为头部的存在,所以向后合并是简单的,但是向前合并是不方便的,所以就在块的最后加一个脚部,作为头部的副本,就方便了合并,具体四种情况如下:
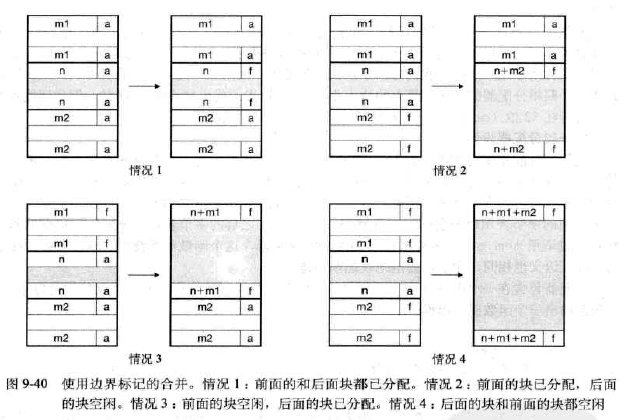
-
空闲块总是需要脚部的。
实现简单的分配器
- 序言块和结尾块:序言块是初始化时创建的,而且永不释放;结尾块是一个特殊的块,总是以它为结束
- 有一个技巧,就是将重复使用的,操作复杂又有重复性的,这些可以定义成宏,方便使用也方便修改。
- 需要注意强制类型转换,尤其是带指针的,非常复杂
-
因为规定了字节对齐方式为双字,就代表块的大小是双字的整数倍,不是的舍入到是。
显式空闲链表
-
区别
(1)分配时间 隐式的,分配时间是块总数的线性时间 但是显式的,是空闲块数量的线性时间。 (2)链表形式 隐式——隐式空闲链表 显式——双向链表,有前驱和后继,比头部脚部好使 -
排序策略:
•后进先出 •按照地址顺序维护分离的空闲链表
- 分离存储,是一种流行的减少分配时间的方法。一般思路是将所有可能的块大小分成一些等价类/大小类
- 分配器维护着一个空闲链表数组,每个大小类一个空闲链表,按照大小的升序排列
- 两种基本方法:简单分离存储和分离适配
-
简单分离存储:每个大小类的空闲链表包含大小相等的块,每个块的大小就是这个大小类中最大元素的大小。
(1)操作 如果链表非空:分配其中第一块的全部 如果链表为空:分配器向操作系统请求一个固定大小的额外存储器片,将这个片分成大小相等的块,并且连接起来成为新的空闲链表。 (2)优缺点 优点:时间快,开销小 缺点:容易造成内部、外部碎片 - 分离适配:每个空闲链表是和一个大小类相关联的,并且被组织成某种类型的显示或隐式链表,每个链表包含潜在的大小不同的块,这些块的大小是大小类的成员。这种方法快速并且对存储器使用很有效率。
- 伙伴系统是分离适配的特例
-
其中每个大小类都是2的幂。这样,给定地址和块的大小,很容易计算出它的伙伴的地址,也就是说:一个块的地址和它的伙伴的地址只有一位不同。优点:快速检索,快速合并