2017-2018-1 20145237 《信息安全系统设计基础》第十四周学习总结
第十章 系统级I/O
教材学习内容总结
10.1 Unix I/O
所有的I/O设备,如网络、磁盘和终端,都被模型化为文件,而所有的输入和输出都被当做对相应文件的读和写来执行。这种将设备优雅地映射为文件的方式,允许Unix内核引出一个简单、低级的应用接口,称为Unix I/O,这使得所有的输人和输出都能以一种统一且一致的方式来执行:
·打开文件。
·改变当前的文件位置。
.读写文件。
.关闭文件。
10.2打开和关闭文件
进程是通过调用。pen函数来打开一个已存在的文件或者创建一个新文件的:
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int open(char *filename, int flags, mode_t mode);
返回:若成功则为新文件描述符,若出错为-1.
如何访问文件:
O_RDONLY:只读。
O_WRONLY:只写。
O_RDWR:可读可写。

10.3读和写文件
应用程序是通过分别调用read和wri七e函数来执行输人和输出的。
#include <unistd.h>
ssize_t read(int fd, void *buf size_t n);
返回:若成功则为读的字节数,若EOF则为0,若出错为-1。
ssize_t write(int fd, const void *buf,size_t n)
返回:若成功则为写的字节数,若出错则为-1。
read函数从描述符为fd的当前文件位置拷贝最多n个字节到存储器位置buf。
返回值一1表示一个错误,而返回值0表示EOF。否则,返回值表示的是实际传送的字节数量。
10.4用RIO包健壮地读写
RIO提供了两类不同的函数:
.无缓冲的输入输出函数。这些函数直接在存储器和文件之间传送数据,没有应用级缓冲。它们对将二进制数据读写到网络和从网络读写二进制数据尤其有用。
.带缓冲的输入函数。这些函数允许你高效地从文件中读取文本行和二进制数据,这些文件的内容缓存在应用级缓冲区内,类似于为像printf这样的标准I/O函数提供的缓冲区。
通过调用rio_readn和rio_writen函数,应用程序可以在存储器和文件之间直接传送数据。
#include"csapp.h"
ssize_t rio_readn(int fd, void *usrbuf,size_t n);
ssize_t rio_writen(int fd, void *usrbuf,size_t n);
返回:若成功则为传送的字节数,若EOF则为0(只对rio_readn而言),若出错则为-1.
10.5读取文件元数据
应用程序能够通过调用stat和fstat函数,检索到关于文件的信息(有时也称为文件的元数据( metadata)) .
#include <unistd.h>
#include <sys/stat.h>
int stat(const char *filename struct stat *buf);
int fstat(int fd, struct stat *buf);
返回:若成功则为0,若出错则为-1
10.6共享文件
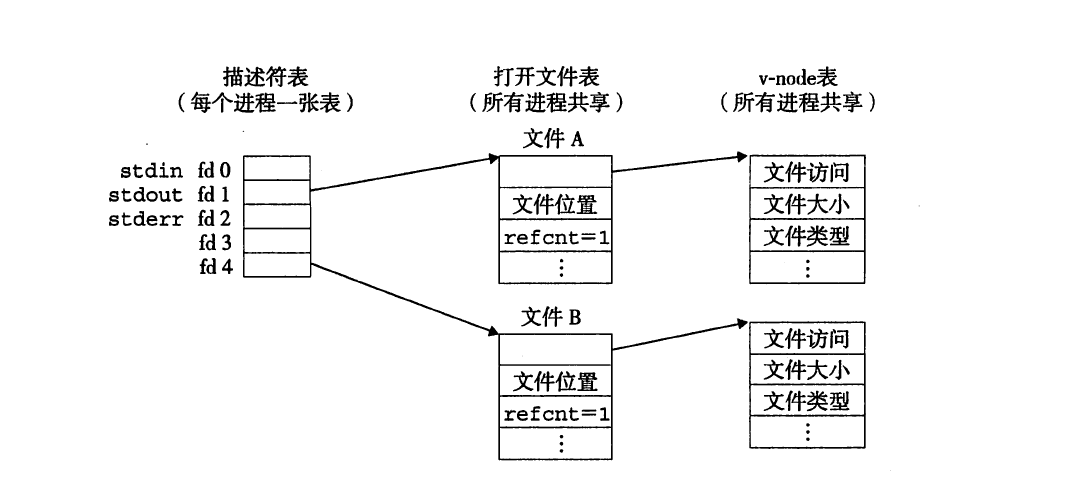
描述符表:每个进程都独立的描述符表。
文件表:打开文件的集合时由一张文件表来表示的,所有的进程共享这张表。每个文件表的表项组成包括有当前位置,引用计数。
v-node表:同文件表一样,所有的进程共享这张表。
10.10小结
Unix提供了少量的系统级函数,它们允许应用程序打升、夫团、读和写文件,提取文件的G数据,以及执行I/O重定向。Unix的读和写操作会出现不足值,应用程序必须能正确地预计n处理这种情况。应用程序不应直接调用Unix I/O函数,而应该使用RIO包,RIO包通过反复气行读写操作,直到传送完所有的请求数据,自动处理不足值。
Unix内核使用三个相关的数据结构来表示打开的文件。描述符表中的表项指向打开文件表户的表项,而打开文件表中的表项又指向v-node表中的表项。每个进程都有它自己单独的描述子表,而所有的进程共享同一个打开文件表和v-node表。理解这些结构的一般组成就能使我们誓楚地理解文件共享和I/O重定向。
标准I/O库是基于Unix I/O实现的,并提供了一组强大的高级I/O例程。对于大多数应用程荞而言,标准I/O更简单,是优于Unix I/O的选择。然而,因为对标准I/O和网络文件的一些相工不兼容的限制,Unix I/O比标准I/O更适用于网络应用程序。
课后部分作业及实现
练习题10.1
Unix进程生命周期开始时,打开的描述符赋给了stdin(描述符0), stdout(描述符1)和stderr(描述符2)。open函数总是返回最低的未打开的描述符,所以第一次调用open会返回描述符3。调用close函数会释放描述符3。最后对open的调用会返回描述符3,因此程序的输出是“fd2=3 ".
练习题10.3
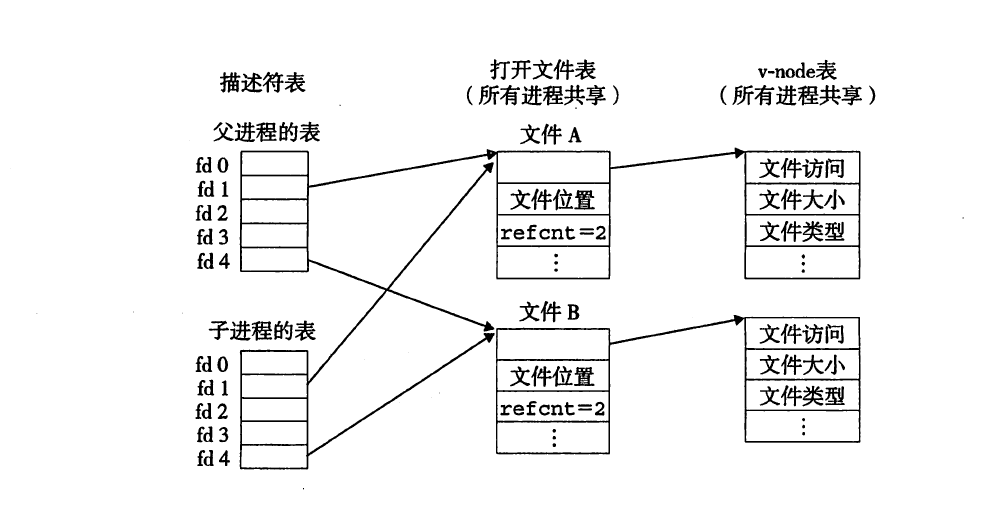
子进程会继承父进程的描述符表,以及所有进程共享的同一个打开文件表。因此,描述符fd在父子进程中都指向同一个打开文件表表项。当子进程读取文件的第一个字节时,文件位置加1。因此,父进程会读取第二个字节,而输出就是c=o
练习题10.4
重定向标准输入(描述符0)到描述符5,我们将调用dup2 (5, 0)或者等价的dup2(5,STDIN FILENO)。
练习题10.5
因为将fd1重定向到了fd2,所以输出是c=o
代码托管
结对及互评
点评模板:
- 博客中值得学习的或问题:
- xxx
- xxx
- ...
- 代码中值得学习的或问题:
- xxx
- xxx
- ...
- 其他
本周结对学习情况
- [20155208](博客链接)
- 结对照片
- 结对学习内容
- XXXX
- XXXX
- ...
其他(感悟、思考等,可选)
xxx
xxx
学习进度条
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 | |
| 第一周 | 200/200 | 2/2 | 20/20 | |
| 第二周 | 300/500 | 2/4 | 18/38 | |
| 第三周 | 500/1000 | 3/7 | 22/60 | |
| 第四周 | 300/1300 | 2/9 | 30/90 |
尝试一下记录「计划学习时间」和「实际学习时间」,到期末看看能不能改进自己的计划能力。这个工作学习中很重要,也很有用。
耗时估计的公式
:Y=X+X/N ,Y=X-X/N,训练次数多了,X、Y就接近了。
-
计划学习时间:XX小时
-
实际学习时间:XX小时
-
改进情况:
(有空多看看现代软件工程 课件
软件工程师能力自我评价表)