目录:
一、为什么要对JS代码进行保护?
二、js代码保护前世今生
三、js虚拟保护方案与技术原理
四、总结
一、为什么要对JS代码进行保护?
1.1、H5应用场景
由于H5的跨平台优势,大大提高了用户体验,无需下载,只需要点开就可以观看,不需要下载后占据内存,简化流程。在传播的效率上也得到了很大的提升,可以通过微信平台的朋友圈、微信群、公众号等渠道得到了最大化的曝光,收获爆火的热度和话题度。但是在一定程度上,H5要实现以上各种应用功能,其实是JavaScript赋予了它更强大的能力。
1.2、目前存在的风险
JavaScript(简称“JS”)是一种具有函数优先的轻量级,解释型或即时编译型的高级编程语言。虽然它是作为开发Web页面的脚本语言而出名的,但是它也被用到了很多非浏览器环境中,JavaScript基于原型编程、多范式的动态脚本语言,并且支持面向对象、命令式和声明式(如函数式编程)风格。
如今各种h5应用场景越来越多也变得越来越复杂,满足了用户的各种需求,但是也存在一些安全方面的问题,比如:电商、金融、小游戏、小程序、招聘网站、旅游都存在登录、注册、支付、交易、信息展示等功能,如果这些业务所依赖的js代码被人轻易的破解、哪么应用将面临的安全问题有,商品信息被恶意爬取、价格、评分、评论信息盗取、原创内容盗取、羊毛党实现商品自动秒杀、批量注册小号领取优惠券,黄牛恶意占座,广告点击欺诈等等。
由于js脚本语言特性,代码是公开透明,由于这个原因,至使JS代码是不安全的,任何人都可以直接获取源代码阅读、分析、复制、盗用,甚至篡改。如果不想让js代码被恶意篡改攻击,保障业务的安全。那么使用JS保护是必需的。
1.3、如何对JS代码进行保护?
目前主流的方式是使JS代码不可读,增加攻击者理解代码功能复杂度,代码变得难也阅读之后,攻击者往往会进行动态跟踪调试,通过逆向还原出原始代码,或分析出程序功能。因此,使JS代码不可分析,增加反调式从防破解角度来看效果不佳。
随着浏览器技术的发展,动态调试器的功能越来越完善,把代码变得难也阅读这些保护方法很难起到很好的保护效果。 故该方案将js源码编译生成自定义指令集并通过实现一个虚拟机来模拟解释执行自定义指令的方法防止被破解、篡改,该方案由于是将js源码转换成自定义的任意指令,将原本比较容易理解的代码转换成只能自己虚拟机才能读懂与执行的指令,这样黑客无法通过直接反编译该指令分析或修改代码逻辑,攻击者需了解自定义指令细节,才能分析程序逻辑。避免了黑客直接通过获取前端js代码就能破解、篡改代码逻辑,从而极大提升了js代码的安全防破解能力。
二、js代码保护前世今生
2.1、现有产品介绍
360加固保H5加固
通过对JavaScript代码进行混淆加密、压缩等方式,保证H5的核心代码无法被破解和查看,从而降低非法篡改、恶意利用的风险。
爱加密H5移动应用安全加固
控制流平坦化、垃圾指令注入、常量字符串加密、常数加密、二元表达式加密、代码压缩、函数变量名混淆、禁止控制台输出
顶像H5代码混淆
H5代码除了混淆加密之外,顶象还独家提供H5接口Native化的保护,因H5代码即使混淆之后仍有可能存在被破解的情况,所以对H5中重要的接口提供保护之外,还将原本JS或H5代码Native为C/C++代码,极大增大破解的难度。
jscrambler
jscrambler是国外一家JavaScript保护领域老牌的安全公司,产品主要功能:具有多态性混淆、代码锁定和自我防御功能的Web和混合应用程序的弹性JavaScript保护。受保护的代码极难进行反向工程,并防止调试/篡改尝试。
jshaman
萨满科技是国内最专注于Web前端安全的JS代码保护团队。
Jshaman是专业的JS代码在线加密平台。
JShaman的含意是什么?
JShaman = JS + Shaman,即:JS萨满。
在传统的世界观,或游戏概念中。萨满巫师具有治愈、辅助、守护的含意。
那么我们想赋予“JS萨满”的寓意是:治愈JS代码公开透明的缺陷、辅助JS开发、守护JS产品。
产品主要功能:
使JS代码不可读
因为JS代码是公开透明的,所以其安全问题的根本出自于可读性,使代码不可读成为了JS保护的首要需求。JS混淆,可以实现JS代码不可读化。
使JS代码不可分析
除了可读性之外,被跟踪分析是JS面临的另一个重大安全问题,一份不可读的代码仍有被攻击者动态跟踪调试以分析出技术原理的可能性。
使JS代码每次被调用(引用),代码自身可自动发生变异,变化为与之前完全不同的代码(功能完全不变,只是代码形式变异),以此杜绝代码被动态分析调试!
平展控制流
通过打乱函数执行流程,随机插入无用代码、函数等方式,改变原有的程序执行流程,进而达到防止代码被静态分析的目的。 明文字符加密
包括对变量名进行不易读重命名、对字符进行阵列化加密等,使代码中容易被攻击者参考的明文内容变的不可见,使代码分析更难以进行。
Js2x
JavaScript多态保护引擎、压缩代码、自我保护、平展控制流、多态、JS虚拟机字节码技术。
SecurityWorker
SecurityWorker提供完全隐匿且兼容ECMAScript 5.1的类WebWorker的安全可信环境,帮助保护你的核心Javascript代码不被破解。
SecurityWorker不同于普通的Javascript代码混淆,我们使用 独立Javascript VM + 二进制混淆opcode核心执行的方式防止您的代码被开发者工具调试、代码反向。
2.2、主流保护方案
js压缩:
将脚本进行编码,插入无用代码,干扰显示大量换行、注释、字符串等,运行时解码再eval执行。
运行环境监测:
代码自检验:计算某片断代码hash,运行时比较hash值是否相同来检测代码是否被篡改。
调试器检测:检测是否有调试特征、控制台是否打开、检测debugger指令是否执行。
字符串混淆
去除尽可能多的有意义信息,删除注释、空格、换行、冗余符号,变量重命名,变成a、b、c、1、2、3等,属性重命名,变成 a.a、a.b() ,将无用代码移除。
样例如下:
(function(a, b, c, d, e, f, g, ……) { if (a[b] === c) { d[e][f](g, ……) …… }
流程混淆
对代码流程进行混淆,因为在代码开发的过程中,为了使代码逻辑清晰,便于维护和扩展,会把代码编写的逻辑非常清晰。这样攻击者也比较容易分析,一段代码从输入,经过各种if/else分支,顺序执行之后得到不同的结果,流程混淆是将这些执行流程和判定流程进行混淆,让攻击者没那么容易摸清楚代码的执行逻辑。
简单举例说明下,有如下没有混淆的代码:
(function () { console.log(1); console.log(2); console.log(3); console.log(4); console.log(5); })();
流程如图1所示:
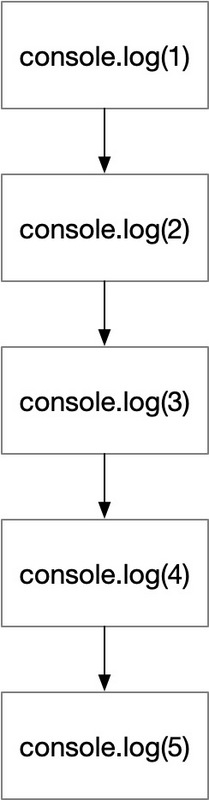
图1
混淆过后代码如下:
(function () {
var flow = '3|4|0|1|2'.split('|'), index = 0;
while (!![]) {
switch (flow[index++]) {
case '0':
console.log(3);
continue;
case '1':
console.log(4);
continue;
case '2':
console.log(5);
continue;
case '3':
console.log(1);
continue;
case '4':
console.log(2);
continue;
}
break;
}
}());
混淆过后的流程如图2所示: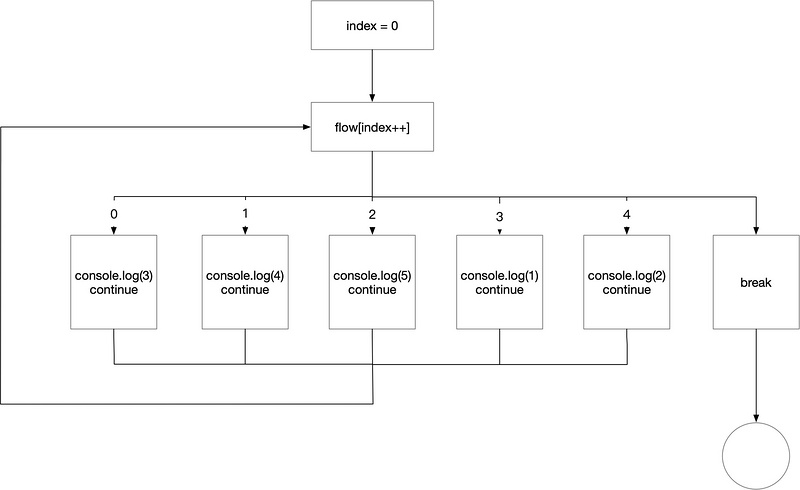
图2
从上图上看代码变了,所有的代码都挤到了一层当中,这样做的好处在于在让攻击者无法直观,或通过静态分析的方法判断哪些代码先执行哪些后执行,必需要通过动态运行才能记录执行顺序,增加了分析的负担。
三、js虚拟保护方案与技术原理
3.1、jsvmp总体架构
整体架构流程是服务器端通过对JavaScript代码词法分析 -> 语法分析 -> 语法树->生成AST->生成私有指令->生成对应私有解释器,将私有指令加密与私有解释器发送给浏览器,就开始一边解释,一边执行,如图3所示:
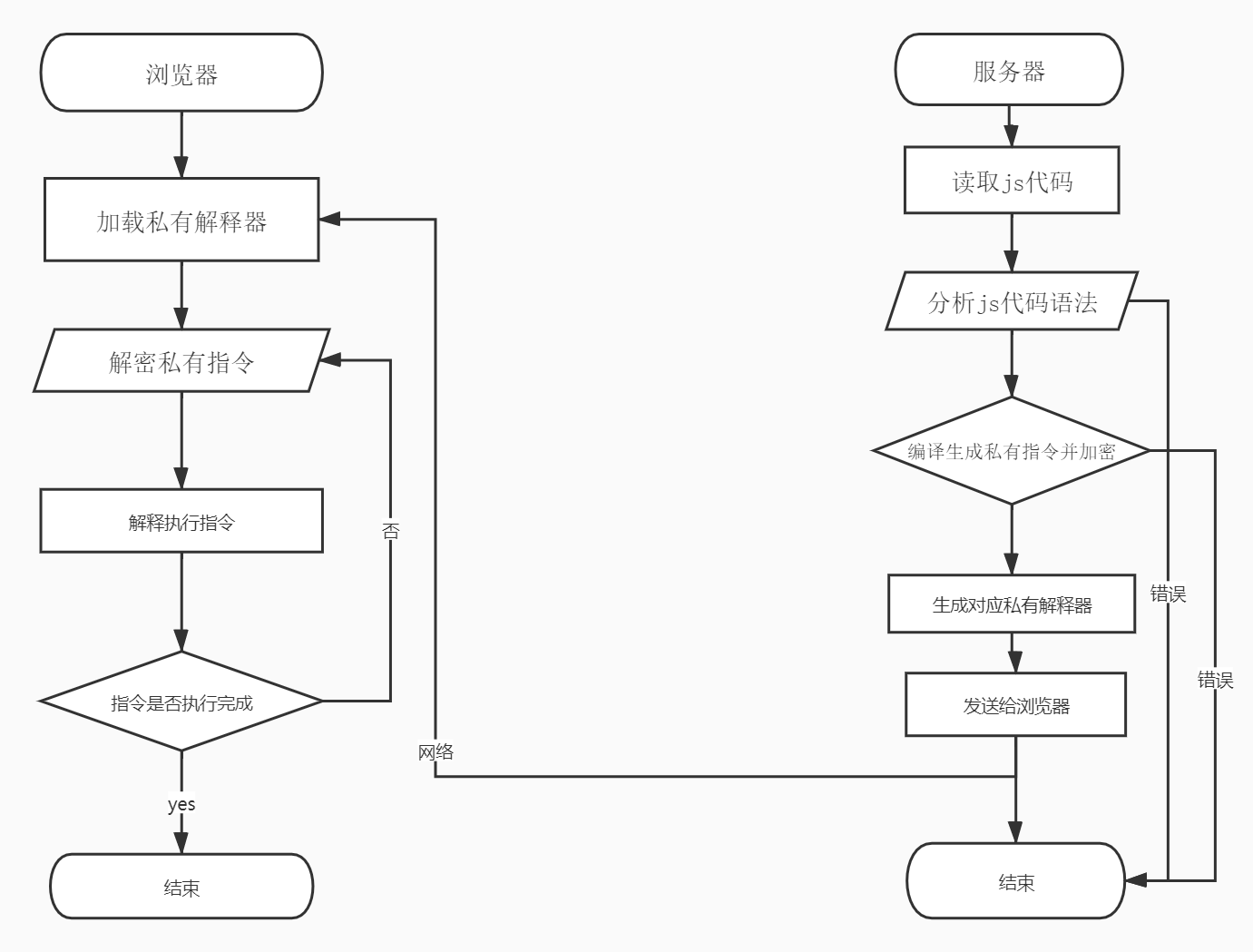
图3
3.2、指令生成原理
指令生成流程
分为如下几个步骤:
第一步:读取分析整个源代码
第二步:编译器扫描函数声明和变量声明,做语法分析,有错则报语法错误
处理函数声明:如果出现函数命名冲突,会进行覆盖
处理变量声明:如果出现变量命名冲突,会忽略
第三步:将扫描到的函数和变量保存到一个对象中。
第四步:根据对象生成字段码。
整体流程如图4所示
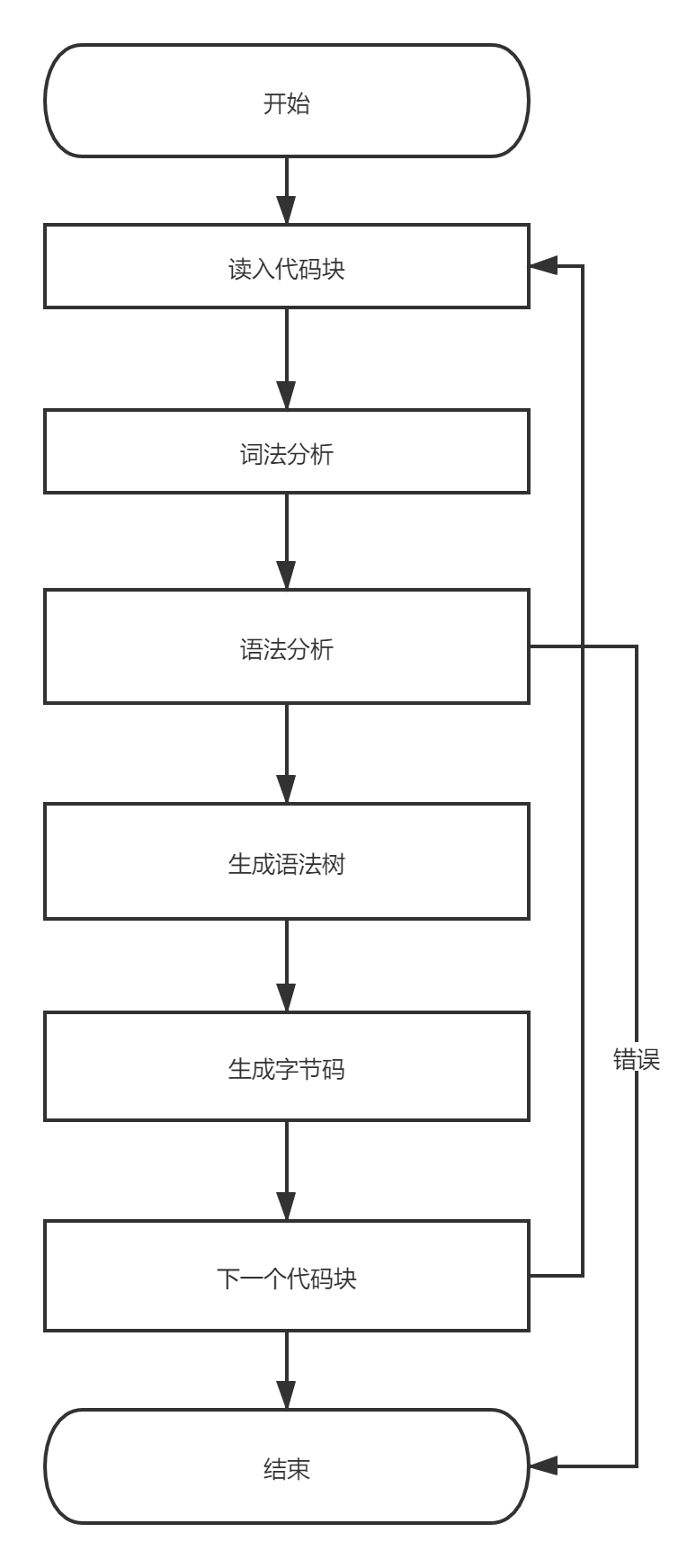
图4
什么是编译器
简单来说,编译器的功 能就是当一段代码经过编译器的词法分析、语法分析等阶段之后,会生成一个树状结构的“抽象语法树(AST)”,该语法树的每一个节点都对应着代码当中不同含义的片段。
示例代码:
function func(a) { var c = 10; var s = 22; var m = c + s; return b => a * b + m; } var ret = func(2); print(ret(4));
上面代码通过编译后生成语法树如下:
[ FunctionDeclaration { name: 'func', params: [ 'a' ], body: [ VariableDeclaration { name: 'c', value: IntegerLiteral { value: 10 } }, VariableDeclaration { name: 's', value: IntegerLiteral { value: 22 } }, VariableDeclaration { name: 'm', value: BinaryExpression { lhs: IdentifierExpression { name: 'c' }, op: '+', rhs: IdentifierExpression { name: 's' } } }, ReturnStatement { value: FunctionDeclaration { name: null, params: [ 'b' ], body: [ ReturnStatement { value: BinaryExpression { lhs: BinaryExpression { lhs: IdentifierExpression { name: 'a' }, op: '*', rhs: IdentifierExpression { name: 'b' } }, op: '+', rhs: IdentifierExpression { name: 'm' } } } ], asExpression: true } } ], asExpression: false }, VariableDeclaration { name: 'ret', value: CallExpression { expr: IdentifierExpression { name: 'func' }, args: [ IntegerLiteral { value: 2 } ] } }, ExpressionStatement { expr: CallExpression { expr: IdentifierExpression { name: 'print' }, args: [ CallExpression { expr: IdentifierExpression { name: 'ret' }, args: [ IntegerLiteral { value: 4 } ] } ] } } ]
字节码bycode生成
解析语法树生成对应的自定义指令过程如下:
compile(ctx) { const functionLabel = ctx.bc.newLabel(); ctx.bc.write(OpCodes.OP_NEWFUNCTION); functionLabel.address(); const innerCtx = ctx.with({ scope: new Scope(ctx.scope), fn: { arity: this.params.length, bindings: [], }, }); const innerScope = innerCtx.scope; const skip = ctx.bc.newLabel(); if (this.name !== null) { (this.asExpression ? innerCtx : ctx).scope.declareVariable(this.name); } for (const param of this.params) { innerScope.declareParameter(param); } ctx.bc.write(OpCodes.OP_JMP); skip.address(); functionLabel.label(); for (const statement of this.body) { statement.compile(innerCtx); } const { instructions } = ctx.bc; if (instructions[instructions.length - 3] !== OpCodes.OP_RET) { new ReturnStatement(new IntegerLiteral(0)).compile(innerCtx); } skip.label(); for (const variable of innerCtx.fn.bindings) { IdentifierExpression.compileAccess(ctx, { ...variable, scopeNum: variable.scopeNum - 1, }); ctx.write([ OpCodes.OP_BINDVAR, ]); } } }
将bycode用一种中间肋记符(汇编语法)表示如下:
0: OP_NEWFUNCTION 6 3: OP_JMP 58 6: OP_CONST 10 9: OP_CONST 22 12: OP_LOAD0 0 15: OP_LOAD1 0 18: OP_ADD 19: OP_NEWFUNCTION 25 22: OP_JMP 45 25: OP_ENCFUNCTION 0 28: OP_LOADBOUND 0 31: OP_LOADARG0 0 34: OP_MUL 35: OP_ENCFUNCTION 0 38: OP_LOADBOUND 1 41: OP_ADD 42: OP_RET 1 45: OP_LOADARG0 0 48: OP_BINDVAR 49: OP_LOAD 2 0 54: OP_BINDVAR 55: OP_RET 1 58: OP_CONST 2 61: OP_LOAD 2 0 66: OP_CALL 67: OP_CONST 4 70: OP_LOAD 3 0 75: OP_CALL 76: OP_LOAD0 0 79: OP_CALL 80: OP_POP 81: OP_HALT
最后再将汇编转换成最终的bycode码如下:
[ 42, 0, 6, 36, 0, 58, 2, 0, 10, 2, 0, 22, 8, 0, 0, 9, 0, 0, 20, 42, 0, 25, 36, 0, 45, 44, 0, 0, 46, 0, 0, 11, 0, 0, 24, 44, 0, 0, 46, 0, 1, 20, 47, 0, 1, 11, 0, 0, 45, 7, 0, 2, 0, 0, 45, 47, 0, 1, 2, 0, 2, 7, 0, 2, 0, 0, 43, 2, 0, 4, 7, 0, 3, 0, 0, 43, 8, 0, 0, 43, 1, 0 ]
上面的示例js代码就被编译生成一堆看起来无意义的数字,这样攻击者基本不可能从这些数字中推断出程序的逻辑。只有解释器能明白它代表的意义。
3.3、解释器原理
什么是解释器
如同翻译人员不仅能看懂一门外语,也能对其艺术加工后把它翻译成母语一样,人们把能够将代码转化成AST的工具叫做“编译器”,而把能够将AST翻译成目标语言并运行的工具叫做“解释器”。
在编译原理的课程中,我们思考过这么一个问题:如何让计算机运行算数表达式1+2+3:
当机器执行的时候,它会将表达式翻译成这样的机器码:
1 PUSH 1 2 PUSH 2 3 ADD 4 PUSH 3 5 ADD
而需要运行这段机器码的程序,就是解释器。
解释器运行过程
解释器的运行过程跟计算器差不多。解释器也是一个段代码,你输入一个“表达式”,它内部进行计算后就输出一个 “值”,像这样:
比如,你输入表达式 '(+ 1 2) ,它就输出值,整数3。表达式是一种“表象”或者“符号”,而值却更加接近“本质”或者“意义”。我们“解释”了符号,得到它的意义,这解释器的运行过程。流程如图5所示:
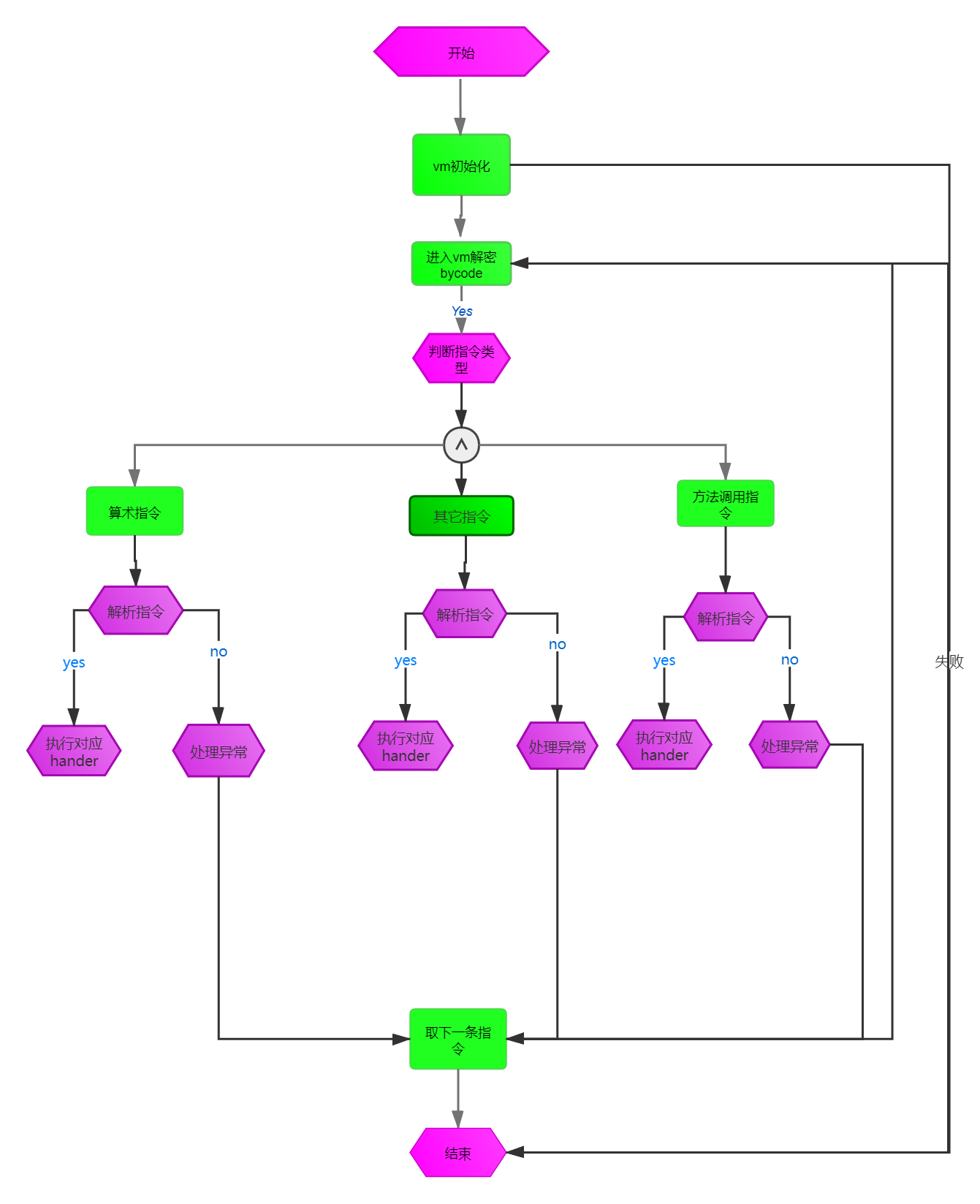
图5
其实电脑CPU就是一个解释器,它专门解释执行机器语言。当我们点击程序图标打开对应的程序时,CPU就开始解释程序中的代码。
解释js编译生成的bycode字解释器代码如下:
op = read(); switch (op) { case OpCodes.OP_PUSH: return push(); case OpCodes.OP_POP: pop(); break; case OpCodes.OP_CONST: push(value.makeInteger(read16())); break; case OpCodes.OP_ADD: add(); break; case OpCodes.OP_SUB: sub(); break; case OpCodes.OP_CONSTTRUE: push(value.makeBoolean(true)); break; case OpCodes.OP_CONSTFALSE: push(value.makeBoolean(false)); break; case OpCodes.OP_LOAD: push(stack[localOffset(read16(), read16())]); break; case OpCodes.OP_LOAD0: push(stack[localOffset(0, read16())]); break;
整个解释过程也是用js代码完成,只是真正的js代码被转换成了bycode码,无法直接看出它的逻辑,这样就很难直接分析它的意义与篡改代码逻辑。
四、总结
4.1、性能
由于性能原因,只能尽可能保护核心算法模块,因为当用户对应用体积敏感或是要求极高的执行效率时,这样做最终代码尽可能小及提高执行效率,这样在极端条件下也不影响用户体验。
4.2、安全
整个过程中,由于是将js明文代码生成的opcode设计是私有不公开的,所以已经不存在明文的Javascript代码了,因此安全性得到了极大的提升。
与此同时,加上精简了opcode的设计,一个数字对应原来的一句js明文,使得生成的opcode体积小于原有的Javascript代码。
注:本文并非认为其它产品技术实现方案不行,只是在不同场景下不同的用户问题更适合使用某种方案,并没有绝对完美的方案。该方案虽然解决了己有产品的许多问题,但其同样也不是最完美的方案。
欢迎关注公众号
