一、linux内核源代码
首先来看一下这次实验中用到的Linux内核源代码:
http://codelab.shiyanlou.com/xref/linux-3.18.6/
根据电子课堂的讲述,我从中看到了一些值得注意的几个关键目录
/arch
- 该目录中包含和硬件体系结构相关的代码,每种平台占一个相应的目录。
- 和32位PC相关的代码存放在x86目录下。
- 每种平台至少包含3个子目录:kernel(存放支持体系结构特有的特征实现)、lib(存放体系结构特有的对通用函数的实现)、mm(存放体系结构特有的内存管理程序的实现),除了这3个子目录之外,大多数体系结构在必要的情况下还有一个boot子目录,包含了在这种硬件平台上启动内核所使用的部分或全部平台特有代码。
/init
- 内核启动相关代码 -> main.c
- Linux内核启动初始化的起点就位于main.c中的函数start_kernel,相当于普通程序的main函数。
/kernel
- 存放linux内核最核心的代码,用于实现系统的核心模块,包括进程管理、进程调度器、中断处理、系统时钟管理、同步机制等。
- 该目录中的代码实现这些核心模块的主体框架,独立于具体的平台和系统架构。
- 核心模块与平台相关的代码放在arch/中。
(这些是我看了觉得重要,从网上找到的具体注解,还有一些其他的目录项,会随着今后使用慢慢展开)
二、实验过程
首先使用实验楼的虚拟机打开shell
1.cd LinuxKernel/
2.qemu -kernel linux-3.18.6/arch/x86/boot/bzImage -initrd rootfs.img
完成启动内核的操作:

其中用到的语句的用处就是启动linux的内核。
qemu -kernel (该版本的Kernel所在路径) -initrd (rootfs.img)**
qemu :相当于打开一个虚拟机
kernel:启动一个内核,位置由其后的文件名指定。
initrd指令:挂了一个ramdisk虚拟硬盘,是内核的重要补充,rootfs.img就是这个虚拟硬盘,内有分区,然后启动其中的init.init是由之前编译而成,gcc -o命名为init。
三、详细分析从start_kernel到init进程启动的过程
start_kernel()函数,相当于C中的main:
void start_kernel(void)
{
………………
page_address_init();
// 内存相关的初始化
trap_init();
mm_init();
………………
// 调度初始化
sched_init();
………………
rest_init(); //其他初始化函数
}
rest_init() 函数:
void rest_init(void)
{
int pid;
………………
kernel_thread(kernel_init, NULL, CLONE_FS);
numa_default_policy();
pid = kernel_thread(kthreadd, NULL, CLONE_FS | CLONE_FILES);
rcu_read_lock();
kthreadd_task = find_task_by_pid_ns(pid, &init_pid_ns);
rcu_read_unlock();
complete(&kthreadd_done);
init_idle_bootup_task(current);
schedule_preempt_disabled();
cpu_startup_entry(CPUHP_ONLINE);
}
rest_init()这个函数调用系统函数 kernel_thread() 创建 1 号进程,即 init 进程,是用户态所有进程的父亲。然后,新建 kthreadd 进程,是内核态所有进程的父亲。最后,通过 cpu_startup_entry 函数启动 0 号进程。
分析过程:
首先,几乎所有的内核模块均会在start_kernel进行初始化。在start_kernel中,会对各项硬件设备进行初始化,包括一些page_address、tick等等,直到最后需要执行的rest_init中,会开始让系统跑起来。那rest_init这个过程中,会调用kernel_thread()来创建内核线程kernel_init,它创建用户的init进程,初始化内核,并设置成1号进程,这个进程会继续做相关的系统初始化。然后,start_kernel会调用kernel_thread并创建kthreadd,负责管理内核中得所有线程,然后进程ID会被设置为2。最后,会创建idle进程(0号进程),不能被调度,并利用循环来不断调号空闲的CPU时间片,并且从不返回。
四、使用gdb跟踪调试内核
在刚刚的基础后进行本次实验:
1.qemu -kernel linux-3.18.6/arch/x86/boot/bzImage -initrd rootfs.img -s -S # 关于-s和-S选项的说明:
2.# -S freeze CPU at startup (use ’c’ to start execution)
3.# -s shorthand for -gdb tcp::1234 若不想使用1234端口,则可以使用-gdb tcp:xxxx来取代-s选项
另开一个shell窗口:
1.gdb
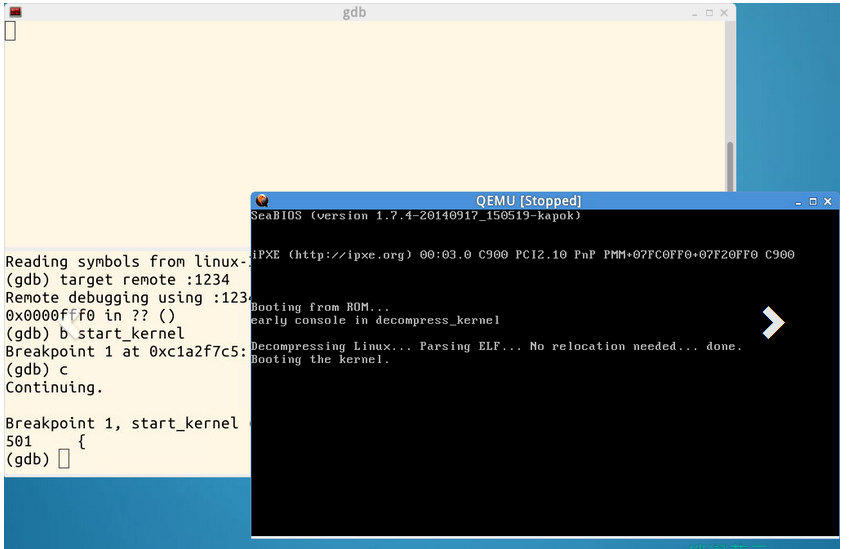
2.(gdb)file linux-3.18.6/vmlinux # 在gdb界面中targe remote之前加载符号表
3.(gdb)target remote:1234 # 建立gdb和gdbserver之间的连接,按c 让qemu上的Linux继续运行
4.(gdb)break start_kernel # 断点的设置可以在target remote之前,也可以在之后
实验时的截图使用gdb跟踪调试内核从start_kernel到init进程启动
用b设置断点,用c继续运行到下一个断点:
五、实验总结:
这次实验有很多不满意的地方,首先我没有成功的在自己的计算机上搭出环境,仍然用的课程中所给的实验楼。当然没有搭出环境的一个重要原因就是我的Linux非常容易崩溃,经常输入密码进入之后就只显示蓝屏,而不显示界面,这其中貌似有我操作不当的原因,还有就是通过查询,发现我所下载版本的Linux与虚拟机选定的环境存在不兼容导致的,之后我下载了其他版本的Linux,目前还未崩溃过,不过本次实验没能来得及在自己的电脑上完成环境的搭建工作;
经过课上老师的讲解,以及多次的实践让我对于gdb的调试过程有了一个较为详细的了解,其中下图是我找到的有关gdb调试相关的基础操作,程序的调试某种程度上说比程序的编写所占比重更大,因此我们应当对于调试的相关步骤熟练掌握,不要总通过在程序中写printf("a")这种方式来找到程序中的问题,而是应当通过设置断点,条件断点等方式,找到程序的问题,对于程序中变量值输出方面的练习做的相对较少,接下来我会重点熟悉这方面,真正做到编程调试工作的熟练掌握。

六、教材笔记
本周重点关注了教材中第4章和第6章的内容,主要讲述了Linux的进程调度方式和内核的数据结构。
进程的调度来讲整体与过去所学的操作系统中的内容近似,将进程分为了就绪,阻塞,执行多种状态对进程进行相应的操作,并且对不同的进程标明不同的优先级,按照相应的调度算法去执行相应的进程。其中时间片的分配是进程调度最重要需要做完善的地方,如果为每个进程分配固定的时间片,就要注意时间片的大小,时间片过大就会造成进程的大量等待,感受不到多个进程并发执行,而时间片过短又会造成进程调度耗时过长,影响进程的正常运转。而书中重点讲述了Linux的调度实现所采用的CFS调度算法,它重点的采用了选择运行最少的进程作为下一个运行的进程,而不再采用分配给每个进程时间片的做法,每个进程都按其权重在全部可运行进程中所占比例的“时间片”来运行。
而在Linux内核的数据结构的讲述中我看到了相应的一些常见的数据结构:链表、队列、映射、二叉树。其中数据结构的具体实现和描述对于我来说还是相对熟识的,而其中新了解的就是大o符号和大Ɵ符号的使用。大o符号用来描述函数的增长率,我们通过这样的一种函数计算的方式去找到一个算法的执行上限;而大Ɵ符号描述的则更为具体,它所寻找的是最小的上限,虽然我们在大多时候将大o理解为相同的功能,但是实际上大Ɵ符号描述的才是最小上限。这两个函数及其重要,我们通过其评价算法和内核组件在多用户、处理器、进程、网络连接,以及其他环境下伸缩度的重要指标。