安装教程:/home/yu/develop/hadoop-2.7.1/bin:/home/yu/develop/hadoop-2.7.1/sbin
hadoop组成
hadoop主要包括HDFS系统和MapReduce两个部分。
HDFS文件系统
hdfs文件系统特点:1.数据冗余,硬件容错
2.流式数据访问。不允许修改,写一次读多次,想修改只能删除再写
3.适合大容量文件,不适合大量小文件,因为文件每次读取都需要访问NameNode,NameNode会产生过大的负载
4.不适合交互式,延迟较大
5.不支持多个用户同时写一个文件
hdfs文件被分成块进行存储,hdfs系统块默认大小为64MB块是文件存储的逻辑单元
NameNode是管理节点,存放元数据。
元数据主要存储两种表:1.文件与数据块的映射表 2.数据块与数据节点的映射表
还存在二级NameNode定期元同步数据映像文件、修改日志,NameNode发生故障时二级NameNode转正
DataNode是HDFS的工作节点,存放数据块
1.HDFS中每个数块存三份,分布在两个机架的三个节点
2.心跳检测:DataNode定期向NameNode放心跳消息
MapReduce并行计算模型
1.MapReduce概念
Map:将一个大的任务分解成许多小任务,进行并行处理
Reduce:将结果合并
2..job和task
一个作业成为job,一个job完成过程要拆分成多个task,task又分为JobTask和MapTask两类
3..hadoop Mapreduce体系结构
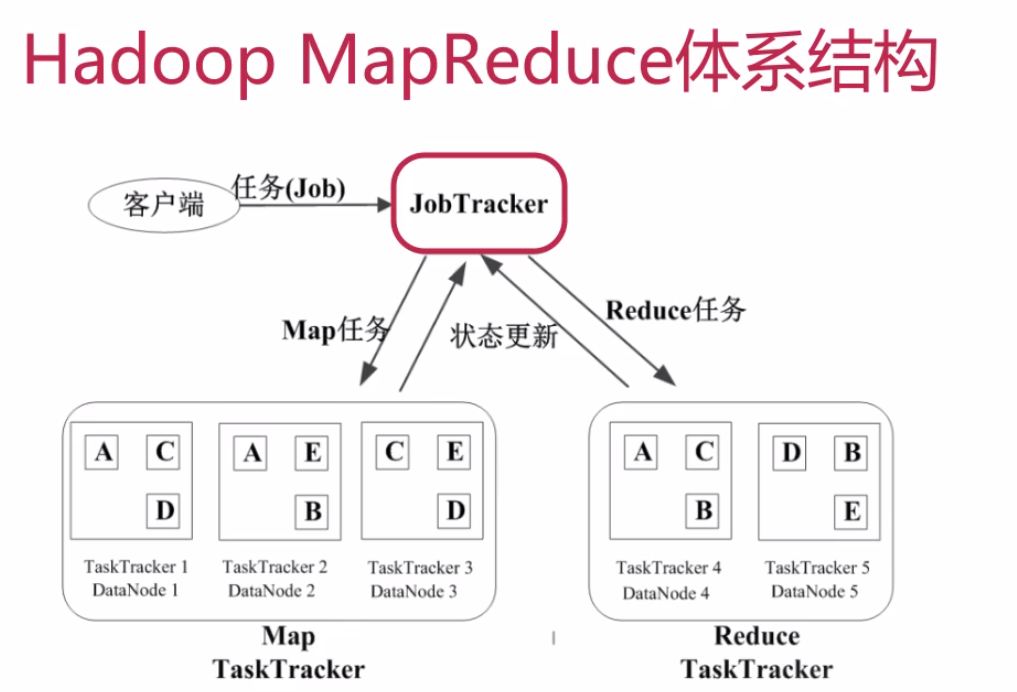
(1)Jobtracker
a.作业调度
b.分配任务、监控任务执行进度
c.监控Tasktracker运行情况
(2)TaskTracker
a.执行任务
b.汇报任务状态
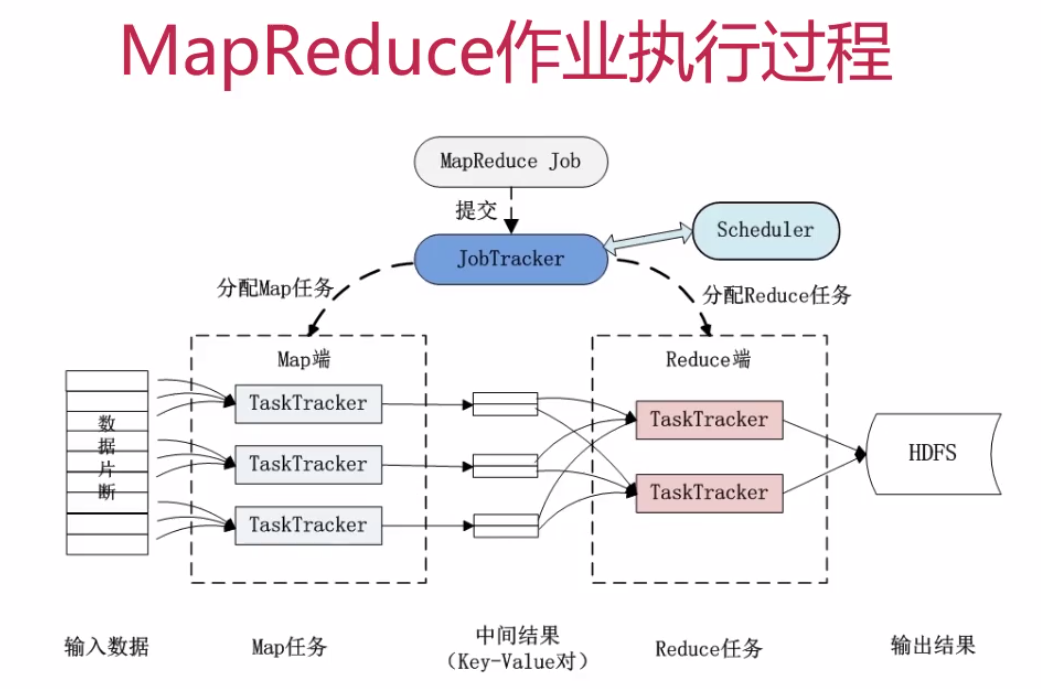
4.MapReduce作业执行过程
4.容错机制
a.重复执行
b.推测执行
当一个节点执行过慢时会使用另一个节点与其共同计算相同的任务,当有一个节点完成时,另一个节点不在进行计算。