任务要求:寻找记录当日全国疫情数据的网站,爬取其中的数据存入数据库,最后像之前数据可视化一样用图表显示数据。
参考博客:https://www.cnblogs.com/dd110343/p/12461824.html
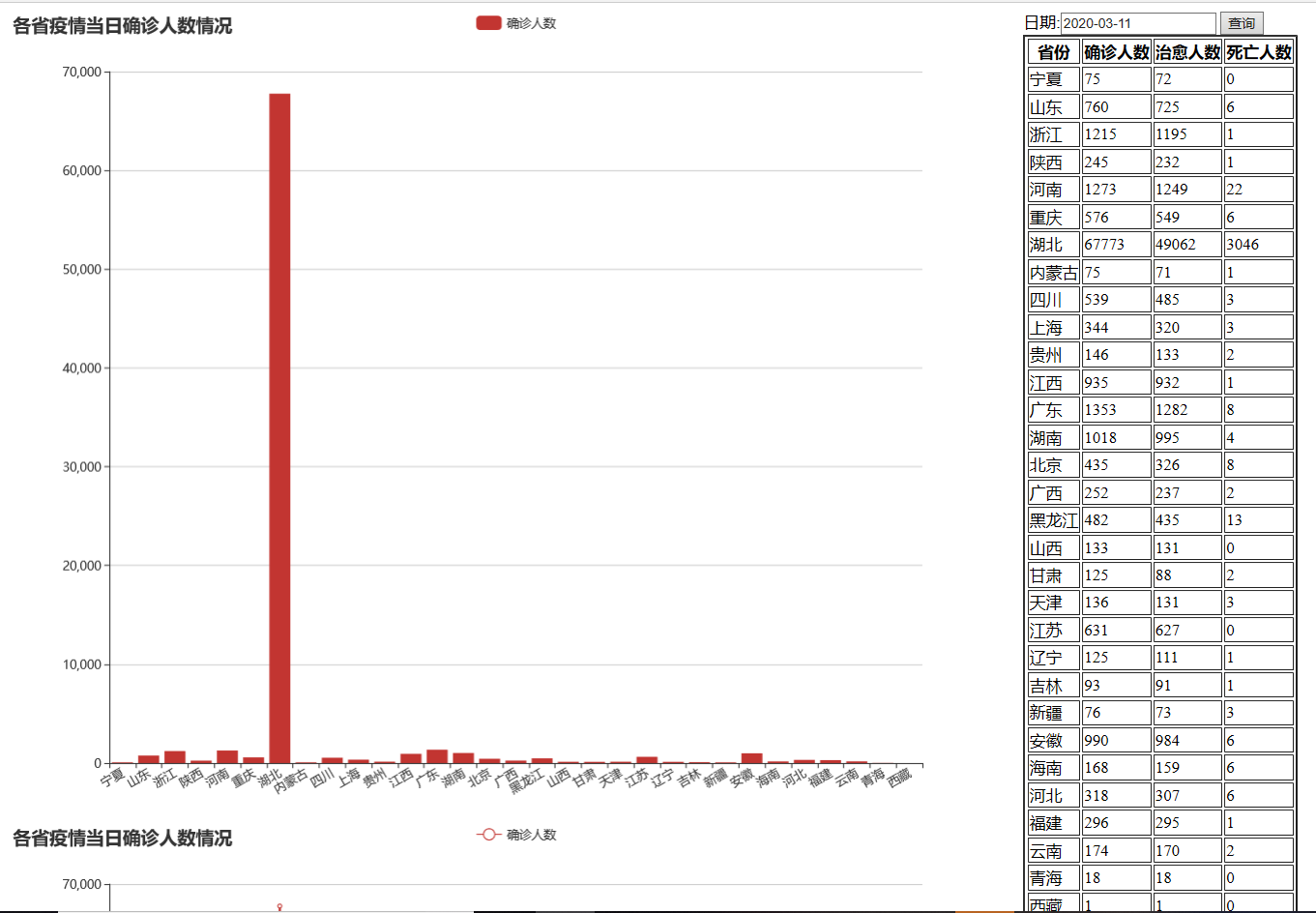
在讲解之前先附上老师要求的表格统计图:
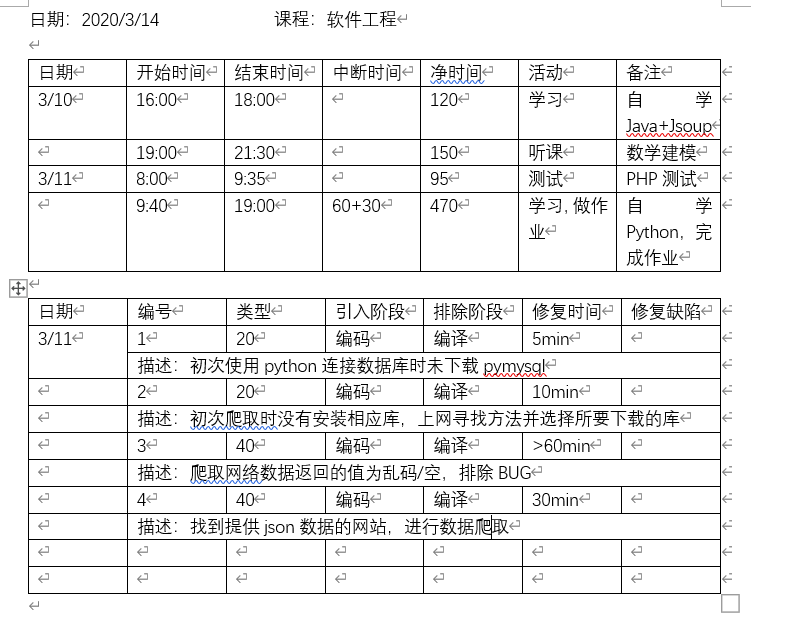
这是我在完成该作业时记录的过程,写得很简略。留作业当天晚上我选择使用Java+Jsoup尝试爬取,但是所选择的网站,当我用Chrome浏览器读取它的HTML代码时,发现其数据是使用jQuery写在<script>里的,由于我不会使用Java+Jsoup将<script>中关于数据的内容单独摘取出来,且舍友已经通过python写出了爬取功能,我就打算用python再试试。python爬取网站的能力很强,代码也十分简单:
1 import requests 2 from bs4 import BeautifulSoup 3 import re 4 import pymysql 5 import json 6 import datetime 7 #记录执行次数 8 num=0 9 #向数据库写入数据 10 def insertdata(data,n): 11 conn=pymysql.connect("localhost","root","Inazuma","paqu",charset='utf8') 12 cur=conn.cursor() 13 sql="INSERT INTO yiqing(Date,Province,City,Confirmed,Cured,Dead) VALUES(%s,%s,%s,%s,%s,%s)" 14 try: 15 cur.execute(sql,data) 16 conn.commit() 17 print(n) 18 except: 19 conn.rollback() 20 print("ERROR") 21 conn.close() 22 #所要爬取的网站的地址 23 url = 'https://raw.githubusercontent.com/BlankerL/DXY-2019-nCoV-Data/master/json/DXYArea.json' 24 #调用requests.get()方法 25 response = requests.get(url) 26 #转换为文本 27 version = response.text 28 #提取其中的json数据 29 jsonData = json.loads(version) 30 #根据数据进行筛选写入 31 for i in range(len(jsonData['results'])): 32 if(jsonData['results'][i]['countryName']=='中国'): 33 province = jsonData['results'][i]['provinceName'] 34 for j in range(len(jsonData['results'][i]['cities'])): 35 confirmed=jsonData['results'][i]['cities'][j]['confirmedCount'] 36 cured=jsonData['results'][i]['cities'][j]['curedCount'] 37 dead=jsonData['results'][i]['cities'][j]['deadCount'] 38 city=jsonData['results'][i]['cities'][j]['cityName'] 39 #使用python中datetime的方法提取时间(yyyy-mm-dd) 40 date=datetime.date.today() 41 #提取数据完成,执行操作,num+1 42 num=num+1 43 #调用入库方法 44 insertdata((date,province,city,confirmed,cured,dead),num)
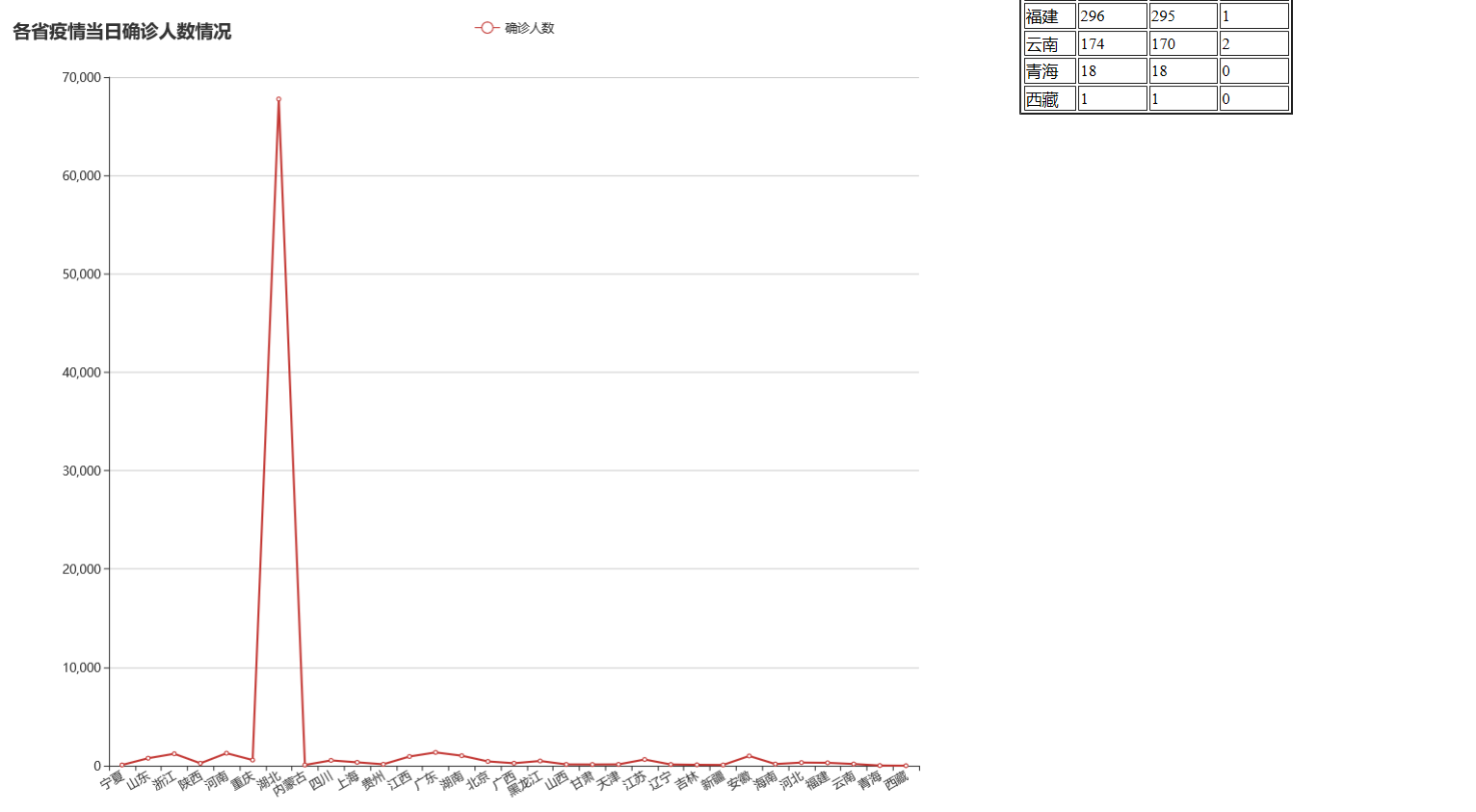
我一开始选择爬取的网站是这个:https://wp.m.163.com/163/page/news/virus_report/index.html?_nw_=1&_anw_=1,但针对其中某<div>控件里<ul>中用于存储数据的的<li>元素数据无法提取出来,针对其<div>的上一级爬取没有问题,整个HTML爬取也能正常显示,但是内部爬取就返回为空。这个BUG我从当天中午一直弄到下午5点左右(3月11号),但还是没有解决,最后在浏览其他资料时偶然看到了上面我给的博客,我发现他爬取的网站是一个纯json数据的文本,提取json数据很简单,最后完成了该任务。当然,我之前爬取网站出现的BUG不可能不管,还在学习中。下面给出在爬取数据后的运行情况以及其可视化显示:
python:

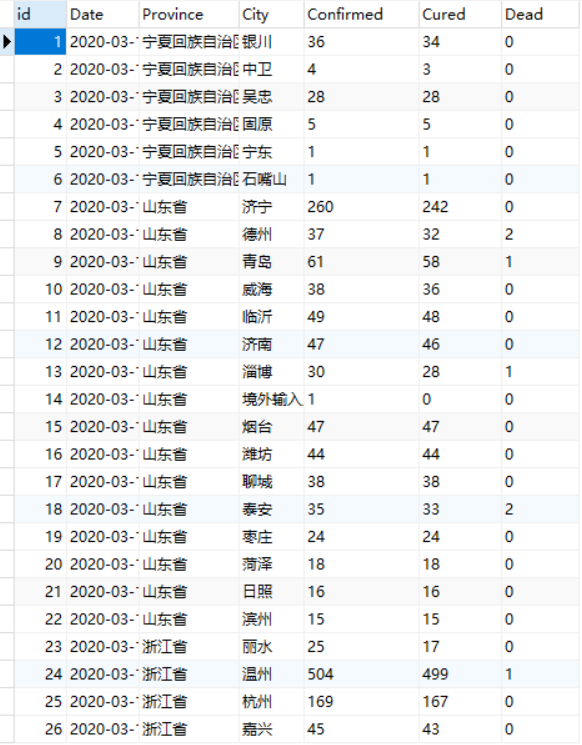
Navicat for MySQL(这里显示部分数据,总计426条(见上图)):
可视化(代码跟上次一样,只是更改了读取的数据库,查询的SQL语句以及HTML中动态插入表格部分的部分代码):‘