了解了一下spark和scala之后,最后还是决定使用伪分布式的hadoop来安装,因为昨天尝试hadoop完全分布式安装的时候虚拟机被我调整了不少东西,因此我选择把虚拟机全部删除重新下载,然而在重新配置过程中ubuntu虚拟机总是出现安装错误,究其原因是我不够耐心导致在安装某环节的时候直接退出了(昨天安装的时候因为在切屏做别的事情所以没有注意),直到晚上才下好虚拟机,今天主要是在tensorflow方面的学习。
手里下载好的视频资源对应版本是tensorflow1.0的缘故(上上篇博客已经提过),在测试学习的时候实在是有很多不便,因此我在b站重新找了一个2.0版本的视频进行对照学习,今天学习的主要是梯度下降算法和多层感知器(初探)。
梯度下降算法:
梯度下降的主要目的是通过迭代找到目标函数的最小值,或者收敛最小值,通俗点说就是计算梯度(微分),极值那里的梯度为0(都知道)。根据视频所说这里会牵扯到一个局部极小值的概念,但要注意的是这个概念在深度学习中不算问题,因为随机初始化后计算梯度时总会算出最小的那个极值点来将这个局部极值点顶掉,而那个最小值就是我们所要的结果。tensorflow2.0版本中实现梯度下降是非常容易的,下面给出测试过程:
首先是数据集:
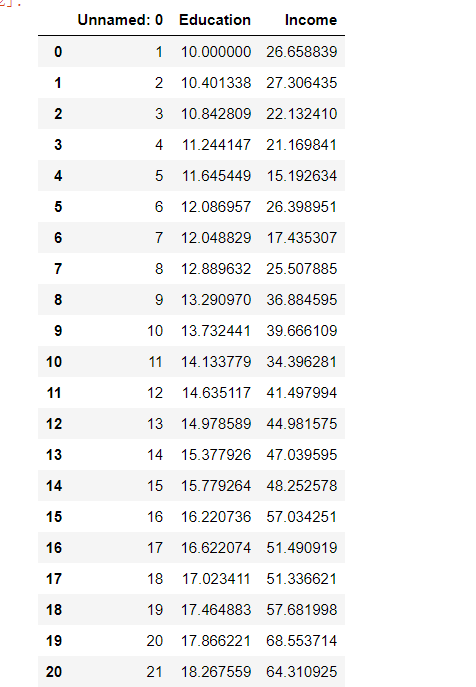
咱们可以用图表来显示一下:

可以看到依稀有一点线性的意思了,那么接下来构造训练模型:
import tensorflow as tf x = data.Education y = data.Income model = tf.keras.Sequential() model.add(tf.keras.layers.Dense(1, input_shape=(1,))) model.summary()

#优化:梯度下降算法 model.compile(optimizer='adam', loss='mse' ) #训练 history = model.fit(x, y, epochs=5000)
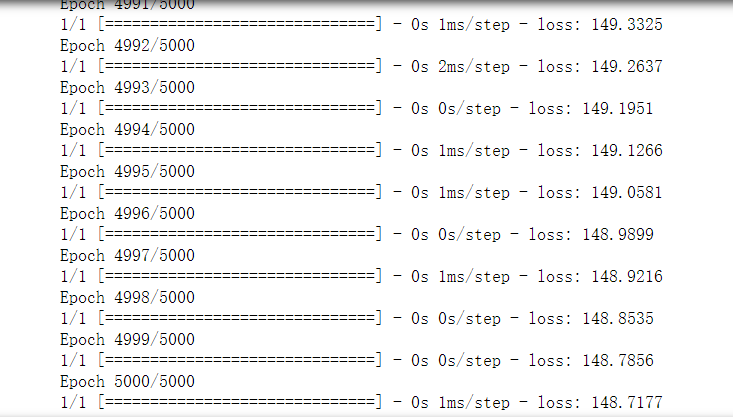
这里设置训练了5000次,可以看到loss的值一直在减小。注意loss='mse',MSE的意思是均方误差。optimizer='adam',adam是常用算法,术语解释为:是对RMSProp优化器的更新.利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率。
#预测 model.predict(x)

预测结果如图示。如果想预测一个确定的值的话就这么写:

多层感知器
多层感知器的概念参考了神经网络,具体的思路理解的还不是很透彻,最开始的神经网络是单层神经元,但由于神经元要求数据必须是线性可分的,而单层神经元里异或问题无法找到一条直线分割两个类,因此引出了多层神经元。这里等之后我理解透彻的时候会再度讨论,首先给出多层感知器的简图:

此外在构造多层感知器的时候需要使用激活函数,本次测试中使用relu激活。
由于测试数据是自己编的,不是那么规范,因此看上去有些乱:




这是一个对广告在电视节目,录音节目,报纸上销售的一个统计
代码如下:
import pandas as pd import numpy as np import matplotlib.pyplot as plt %matplotlib inline data = pd.read_csv('dataset/Advertising.csv') #取行(除去第一点和最后一点) x = data.iloc[:, 1:-1] #取最后一点 y = data.iloc[:, -1] #TV,radio,newspaper三个字段,因此input_shape第一个参数为3 #激活函数relu model = tf.keras.Sequential([tf.keras.layers.Dense(10, input_shape=(3,), activation='relu'), tf.keras.layers.Dense(1)])
仿照上边梯度下降的例子,先看一下model
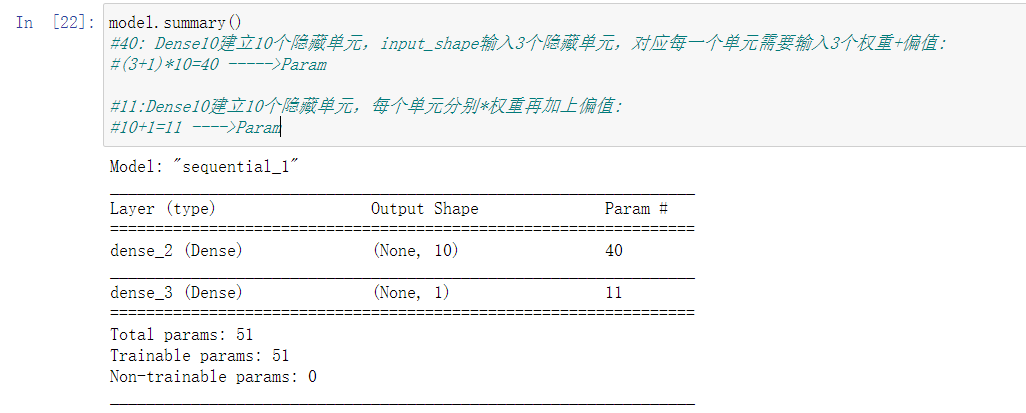
注释的内容结合多层感知器简图来理解,对应的是隐含层部分。
优化和训练不用多说:
#优化 model.compile(optimizer='adam', loss='mse') #训练 model.fit(x, y, epochs=100)

loss依然是递减的
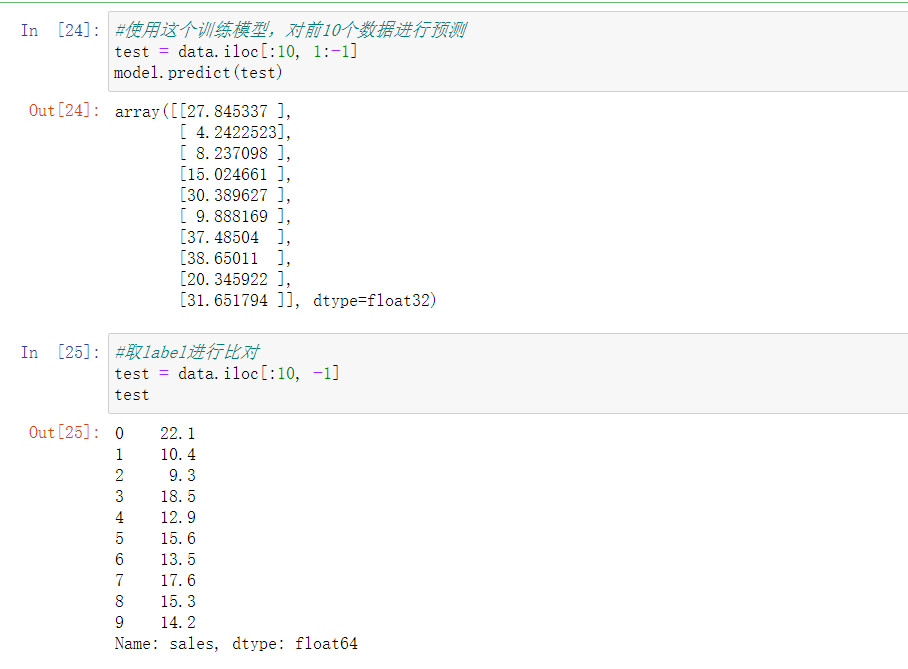
最后是预测结果比对,其实使用训练集训练出来的模型在预测时最好使用新的数据来进行,我这里比对使用的训练集数据,差距过大可能跟训练次数少有关(才100次),而且训练集的数据是瞎编的,从图示阶段就能看得出来,看不出线性的苗头。
今天学习的内容就这么多,明天尝试配置好spark和scala,同时继续学习tensorflow的相关知识。