一、数据清洗
1.预处理
2.去除、补全有缺失值的数据
3.去除、修改数据格式和内容错误的数据
4.去除、修改逻辑错误的数据
5.去除不需要的数据
6.关联性验证
1.预处理
1.1选择数据处理工具:可选择python
1.2查看数据集数据特征:
包括字段解释、数据来源、背景等一切可以描述数据的信息;通过人工查看的方式,对数据做一个比较直观的了解,比如,.head、.description、.shape、.axis .column等等。
2.去除、补全有缺失值的数据
缺失值处理主要包括以下四个步骤:
确定缺失值范围
考察每个字段的缺失比例,按照缺失比例和字段重要性分别指定不同的策略。
1)重要性高,缺失率低:通过计算进行填充;通过经验或者业务知识估计
2)重要性高、缺失率高:尝试其他渠道获取数据;使用字段通过计算获取;去除字段,并在结果中标明
3)重要性低、缺失率低:不作处理或者简单填充
4)重要性低、缺失率高:去除该字段。
删除字段时:先抽取部分数据删除字段,建立模型,查看模型效果,效果不错,再到全部数据上进行删除字段操作。删除一些丢失率高以及重要性低的数据可以降低模型训练复杂度,同时又不会降低模型的效果。
填充缺失值时:
1)以业务知识或经验推测填充
2)以同一字段指标的计算结果(均值、中位数、众数等)填充
3)以不同字段指标的计算结果推测填充,比如通过身份证号码计算年龄,通过收货地址来推测家庭住址、通过访问的IP地址来推测家庭/公司/学校的住址等。
去除不需要的字段
填充缺失内容
重新获取数据
3.去除、修改数据格式和内容错误的数据
格式内容问题主要有以下几类:
1)时间、日期、数值、半全角等显示格式不一致:直接将数据转换为一类格式,该问题一般出现在多个数据源整合的情况下。
2)内容中有不该存在的字符:最典型的的是头部、尾部的空格问题,需要以半自动校验加半人工方式来找出问题,并去除不需要的字符
3)内容与该字段应有的内容不符:比如姓名写成了性别、身份证号写成手机号等
4.去除、修改逻辑错误的数据
通过简单的逻辑推理发现数据中的问题数据,防止分析结果走偏:
1)数据去重
2)去除、替换不合理的值
3)去除、重构不可靠的字段值(修改矛盾的内容)
5.去除不需要的数据
字段属性越多,模型的构建就会越慢,所以有时候可以考虑不要的字段进行删除操作。要注意备份原始数据。
6.关联性验证
如果数据有多个来源,有必要进行关联性验证。通过验证数据之间的关联性来选择比较正确的特征属性。比如:汽车的线下购买信息和电话客服问卷信息,两者间可通过姓名和手机号进行关联操作,匹配两者之间的车辆信息是否为同一辆,如果不是,那么就需要进行数据调整。
二、 文本特征属性转换
机器学习的模型算法输入的数据必须是数值型的,所以文本要进行数据转换,即,文件变为数据:
1.词袋发(BOW/TF)
该模型忽略了文本的语法和语序,用一组无序的单词来表达一段文字或者一个文档,词袋法中使用单词在文档中出现的次数(频率)来表示文档。

词集法(SOW)
词袋法的一种变种,与词袋法原理一样,文档中的单词来表示文档的一种模型,区别在于:词袋法使用的是单词的频数,而词集法使用的是单词是否出现,如果出现赋值为1,否则为0.

2.TF-IDF
不同单词对于文本而言具有不同的重要性,那么,如何评估一个单词对于一个文本的重要性呢:
单词的重要性随着它在文本中出现的次数成正比增加,单词出现的次数越多,该单词对于文本的重要性就越高。
同时单词的重要性会随着在语料库中出现的频率成反比下降,也就是单词在语料库中出现的频率越高,表示该单词常见,对文本的重要性越低,比如常用语:is 、no等。
TF-IDF是一种用于信息检索与数据挖掘常用的加权技术,TF是词频,IDF是逆向文件频率。反映语料库中单词对文档的重要程度。
假设单词用t表示,文档用d表示,语料库用D表示,那么N(t,D)表示包含t的文档数量,|D|表示文档数量,|d|表示文档d中的所有单词数量。N(t,d)表示在文档d中出现的次数。


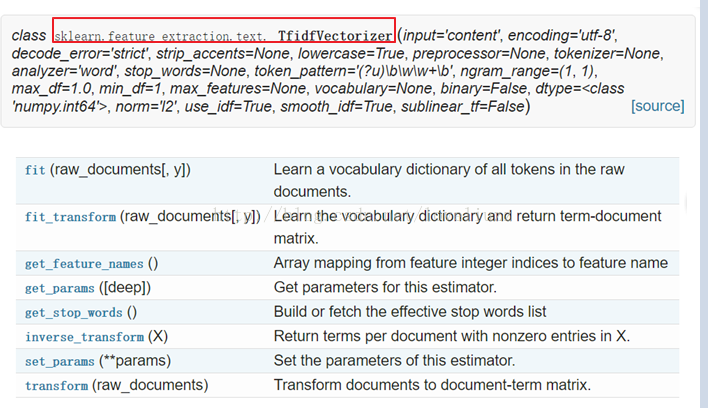
scikit中,所有转换方式均位于模块:sklear.feature_extraction.text。同时提供了一种对TF-IDF公式改版的公式。

参数如下:
CountVectorizer

HashingVectorizer

TfidfVectorizer

TfidfTransformer
Word2Vec
通过对文档中所有单词进行分析,获得单词间的关联程度,从而获取词向量,最终形成一个词向量矩阵,对词向量矩阵的分析:分类、聚类、相似性计算等等,是一种在NLP和大数据中应用比较多的一种文本转换数值型向量方式。
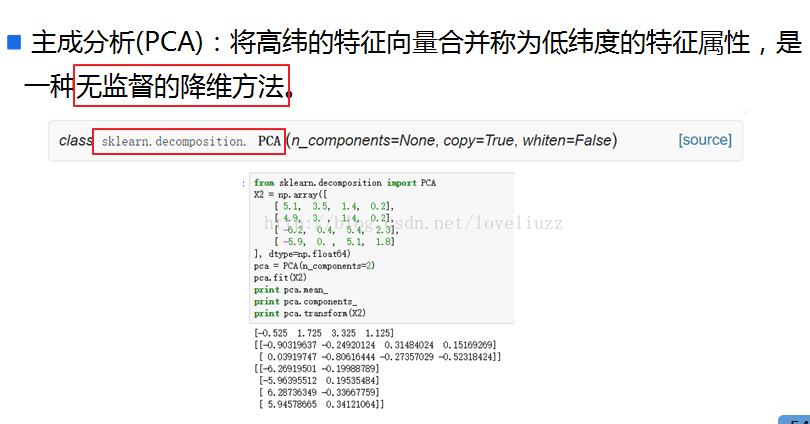
特征选择
太多的特征存在会导致模型构建效率低,模型效果差,需要选择出影响最大的特征属性作为最后构建模型的特征属性列表。
通常从两方面来选择特征:
1)特征是否发散:如果一个特征不发散,比如方差解决于零,也就是说这样的特征对于样本没有什么区分。
2)特征与目标的相关性:如果与目标相关性比较高,应当优先选择。
特征选择的方法主要有以下三种:
Filter:过滤法,按照发散性或者相关性对各个特征进行评分,常用的有方差选择法、相关系数法、卡方检验、互信息法等
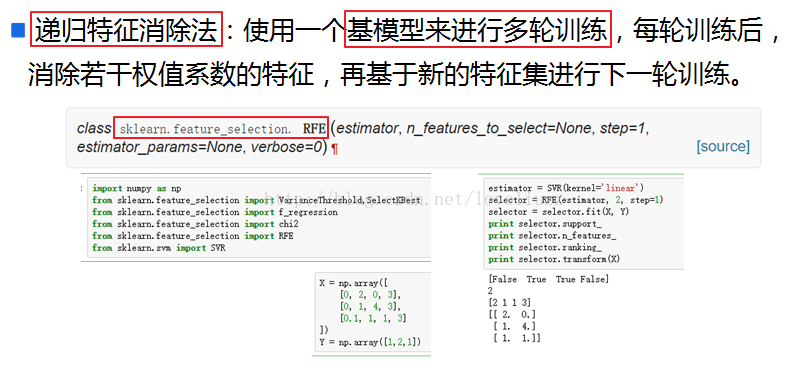
Wrapper:包装法 根据目标函数(通常是预测效果评分),每次选择若干特征或者排除若干特征,常用方法主要是递归特征消除法。
Embedded:嵌入法,先使用某些机器学习算法和模型进行训练,得到各个特征的权重系数,根据系数从大到小选择特征,常用基于惩罚项的特征选择法。
1)方差选择法:
先计算各个特征属性的方差值,然后根据阈值,获取方差大于阈值的特征。

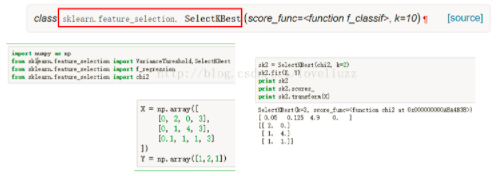
卡方检验:检查定性自变量对定性因变量的相关性


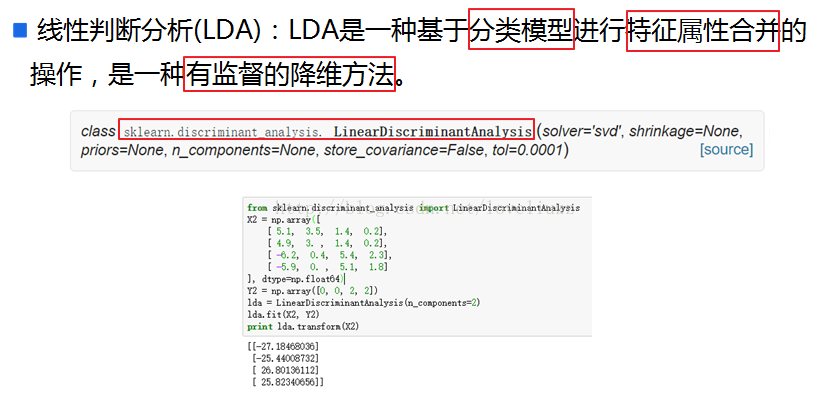

学习自:https://blog.csdn.net/loveliuzz/article/details/78833835