读书笔记
在学习第九章时,我们对C语言的文件操作进行了回顾温习,而学习第七、八章更像是对文件操作学习的延伸拓展,之前学习的fopen、fclose都是低级别文件操作函数,是最为基础的。在第七章中介绍学习了分区和文件系统之间的关系,文件数据都存储在硬盘当中,硬盘需要分区和格式化才能使用,分区则有不同的标准,书中介绍了格式化分区、挂载分区的命令,并讲解了适用于linux的文件系统EXT2,第八章讲解了许多系统调用进行文件操作的方法。
知识点总结
文件I/O操作:
(1)用户模式下的程序执行操作
FILE Ep = fopen ("file","r");可以打开一个读/写文件流。
( 2 ) fopen()在用户( heap)空间中创建一个FILE结构体,包含一个文件描述符fd、一个fbuf [BLKSIZE]和一些控制变量。
( 3 ) fread(ubuf, size, nitem, fp):将nitem个size字节读取到ubuf上,通过:·将数据从FILE结构体的fbuf上复制到ubuf上,若数据足够,则返回。·如果 fbuf没有更多数据,则执行(4a)。
(4a)发出read(fd,fbuf, BLKSIZE)系统调用,将文件数据块从内核读取到 fbuf上,然后将数据复制到ubuf上,直到数据足够或者文件无更多数据可复制。
( 4b) fwrite(ubuf, size, nitem, fp):将数据从ubuf复制到fbuf。·若(fbuf有空间):将数据复制到fbuf 上,并返回。
·若(fbuf已满):发出 write(fd,fbuf,BLKSIZE)系统调用,将数据块写入内核,然后再次写入fbuf。
这样,fread()/fwrite()会向内核发出read(/write)系统调用,但仅在必要时发出,而且它们会以块集大小来传输数据,提高效率。同样,其他库I/O函数,如 fgetc/fputc、fgetsllputs、fscanf/fprintf等也可以在用户空间内的FILE结构体中对fbuf进行操作。
(5)内核中的文件系统函数:
假设非特殊文件的 read(fd, fbuf[ ], BLKSIZE)系统调用。
(6)在read()系统调用中,fd是一个打开的文件描述符,它是运行进程的f数组中的一个索引,指向一个表示打开文件的OpenTable。
( 7 ) OpenTable包含文件的打开模式、一个指向内存中文件INODE的指针和读/写文件的当前字节偏移量。从 OpenTable的偏移量,
·计算逻辑块编号1bk。
·通过INODE.i_block[ ]数组将逻辑块编号转换为物理块编号blk。
( 8 ) Minode包含文件的内存 INODE。EMODE.i_block[ ]数组包含指向物理磁盘块的指针。文件系统可使用物理块编号从磁盘块直接读取数据或将数据直接写入磁盘块,但将会导致过多的物理磁盘I/O。
(9)为提高磁盘IO效率,操作系统内核通常会使用一组IO缓冲区作为高速缓存,以减少物理I/O的数量。磁盘I/O缓冲区管理将在第12章中讨论。
(9a)对于read(fd, buf, BLKSIZE)系统调用,要确定所需的(dev,blk)编号,然后查询I/O缓冲区高速缓存。
(9b)对于write(fd, fbuf, BLKSIZE)系统调用,要确定需要的(dev,blk)编号,然后查询I/O缓冲区高速缓存。
(10)设备I/O:Io缓冲区上的物理IO最终会仔细检查设备驱动程序,设备驱动程序由上半部分的start_io()和下半部分的磁盘中断处理程序组成。
低级别文件操作:分区、格式化分区、挂载分区
磁盘的基本概念:
扇区为最小的物理存储单位,每个扇区为512字节。
将扇区组成一个圆,那就是柱面,柱面是分区的最小单位。
第一个扇区很重要,里面有硬盘主引导记录(Masterbootrecord,MBR)及分区表,其中MBR占有446字节,分区表占有64字节。
Linux 操作系统的文件权限(rwx)与文件属性(拥有者、群组、时间参数等)。 文件系统通常会将这两部份的数据分别存放在不同的区块,权限与属性放置到 inode 中,至于实际数据则放置到 data block 区块中。 另外,还有一个超级区块 (superblock) 会记录整个文件系统的整体信息,包括 inode 与 block 的总量、使用量、剩余量等。
superblock:记录此 filesystem 的整体信息,包括inode/block的总量、使用量、剩余量, 以及文件系统的格式与相关信息等;
inode:记录文件的属性,一个文件占用一个inode,同时记录此文件的数据所在的 block 号码;
block:实际记录文件的内容,若文件太大时,会占用多个 block 。
EXT2文件系统是Linux系统中广泛使用的文件系统,该文件系统是一种索引式文件系统,它将分区分为inode和block,它会给每个文件分配一个inode,inode中存储文件的一些属性信息,block中存储文件真正的内容,一个block的大小有1k、4k等大小,一个block中只能存储一个文件。
文件系统中存储的最小单元是块(block),一个块的大小是在格式化时确定的。启动块(Boot Block)的大小为1KB,由PC标准规定,用来存储磁盘分区信息和启动信息,任何文件系统都不能修改启动块。
启动块之后才是ext2文件系统的开始,ext2文件系统将整个分区划分成若干个同样大小的块组(Block Group)。
在整体的规划当中,文件系统最前面有一个启动扇区(boot sector),这个启动扇区可以安装启动管理程序, 这是个非常重要的设计,因为如此一来我们就能够将不同的启动管理程序安装到个别的文件系统最前端,而不用覆盖整颗硬盘唯一的 MBR, 这样也才能够制作出多重引导的环境啊!至于每一个区块群组(block group)的六个主要内容说明如后:
每个块组的组成:
1)超级块(Super Block)描述整个分区的文件系统信息,如inode/block的大小、总量、使用量、剩余量,以及文件系统的格式与相关信息。超级块在每个块组的开头都有一份拷贝(第一个块组必须有,后面的块组可以没有)。 为了保证文件系统在磁盘部分扇区出现物理问题的情况下还能正常工作,就必须保证文件系统的super block信息在这种情况下也能正常访问。所以一个文件系统的super block会在多个block group中进行备份,这些super block区域的数据保持一致。
超级块记录的信息有:
1、block 与 inode 的总量(分区内所有Block Group的block和inode总量);
2、未使用与已使用的 inode / block 数量;
3、block 与 inode 的大小 (block 为 1, 2, 4K,inode 为 128 bytes);
4、filesystem 的挂载时间、最近一次写入数据的时间、最近一次检验磁盘 (fsck) 的时间等文件系统的相关信息;
5、一个 valid bit 数值,若此文件系统已被挂载,则 valid bit 为 0 ,若未被挂载,则 valid bit 为 1 。
每个区段与 superblock 的信息都可以使用 dumpe2fs 这个命令查询
2)块组描述符表(GDT,Group Descriptor Table)由很多块组描述符组成,整个分区分成多个块组就对应有多少个块组描述符。
每个块组描述符存储一个块组的描述信息,如在这个块组中从哪里开始是inode Table,从哪里开始是Data Blocks,空闲的inode和数据块还有多少个等等。块组描述符在每个块组的开头都有一份拷贝。
3)块位图(Block Bitmap)用来描述整个块组中哪些块已用哪些块空闲。块位图本身占一个块,其中的每个bit代表本块组的一个block,这个bit为1代表该块已用,为0表示空闲可用。假设格式化时block大小为1KB,这样大小的一个块位图就可以表示1024*8个块的占用情况,因此一个块组最多可以有10248个块。
4)inode位图(inode Bitmap)和块位图类似,本身占一个块,其中每个bit表示一个inode是否空闲可用。 Inode bitmap的作用是记录block group中Inode区域的使用情况,Ext文件系统中一个block group中可以有16384个Inode,代表着这个Ext文件系统中一个block group最多可以描述16384个文件。
5)inode表(inode Table)由一个块组中的所有inode组成。一个文件除了数据需要存储之外,一些描述信息也需要存储,如文件类型,权限,文件大小,创建、修改、访问时间等,这些信息存在inode中而不是数据块中。inode表占多少个块在格式化时就要写入块组描述符中。 在Ext2/Ext3文件系统中,每个文件在磁盘上的位置都由文件系统block group中的一个Inode指针进行索引,Inode将会把具体的位置指向一些真正记录文件数据的block块,需要注意的是这些block可能和Inode同属于一个block group也可能分属于不同的block group。我们把文件系统上这些真实记录文件数据的block称为Data blocks。
!
使用系统调用进行文件操作
简单的系统调用:
access:检查对某个文件的权限
int access(char *pathname, int mode);chdir:更改目录
int chdir(const char *path);chmod:更改某个文件的权限
int chmod(char *path, mode_t mode) ;chown:更改文件所有人
int chown (char *name, int uid, int gid);chroot:将(逻辑)根目录更改为路径名int chroot (char *pathname) ;
getcwd:获取CWD的绝对路径名char *getcwd(char *buf, int size);
mkdir:创建目录
int mkdir (char *pathname, mode_t mode);
rmdir:移除目录(必须为空)
int rmdir(char *pathname );
link:将新文件名硬链接到旧文件名
int link (char *oldpath, char *newpath) ;
unlink:减少文件的链接数;如果链接数达到0,则删除文件int unlink (char *pathname);
symlink:为文件创建一个符号链接
int symlink(char *oldpath,char *newpath);rename:更改文件名称
int rename(char *oldpath, char *newpath);utime:更改文件的访问和修改时间
int utime(char *pathname, struct utimebuf *time)以下系统调用需要超级用户权限。
mount:将文件系统添加到挂载点目录上
intmount(char *specialfile, char *mountDir);
umount:分离挂载的文件系统
int umount (char *dir) ;
mknod:创建特殊文件
6、常用系统调用
stat:获取文件状态信息
open:打开一个文件进行读、写、追加
int open(char *file, int flags, int mode)close:关闭打开的文件描述符
int close(int fd)
read:读取打开的文件描述符
int read(int fd,char buf[ 1, int count)write:写入打开的文件描述符
int write(int fa,char buf[ 1, int count)
lseek:重新定位文件描述符的读/写偏移量int lseek ( int fa, int offset, int whence)
dup:将文件描述符复制到可用的最小描述符编号中int dup(int oldfd) ;
dup2:将oldfd复制到newfd 中,如果newfd已打开,先将其关闭int dup2(int oldfa,int newfd)
link:将新文件硬链接到旧文件
int link(char *o1dPath, char *newPath)
unlink:取消某个文件的链接;如果文件链接数为0,则删除文件int unlink(char *pathname) ;
symlink:创建一个符号链接
int symlink(char *target,char *newpath)
readlink:读取符号链接文件的内容
int readlink(char *path,char *buf, int bufsize)
umask:设置文件创建掩码;文件权限为( mask & ~umask)
7、stat文件状态
stat, fstat, lstat - get file status
int stat(const char *file_name,struct stat *buf) ;int fstat(int filedes,struct stat *buf);
int lstat(const char *file_name,struct stat *buf) ;
描述这些函数会返回指定文件的信息。不需要拥有文件的访问权限即可获取该信息,但是需要指向文件的路径中所有指定目录的搜索权限。
stat按文件名统计指向文件,并在缓冲区中填写stat信息。
lstat与stat相同,除非是符号链接,统计链接本身,而不是链接所引用文件。所以,stat 和 1stat的区别是:stat遵循链接,但 lstat不是。
fstat与 stat相同,也只在文件名处说明filedes(由open ( 2)返回)所指向的打开文件。
最有收获的内容
一、弄清了文件系统与分区之间的关系
主流的分区标准有两种,分别是传统的MBR(Main Boot Record )和新的GPT(GUID Partition Table)。后者功能更强大,解决了许多MBR的限制。 MBR信息存在于硬盘最开始的 512 字节中的。但这512个字节并不是只有硬盘分区表,还有启动加载器等。真正留给分区表的只有64个字节。同志们是字节啊,64个字节,换成汉字只能存32个。 因为分区表的大小限制,导致MBR分区表只能记录4个分区。
但随着硬盘越来越大,人们需要更多的分区,于是发明了扩展分区。扩展分区的意思就是把之前的4个分区中的一个当做扩展部分,不再记录分区信息,换而记录另一张 分区表的位置,而被改变的这个分区,要给它一个新的名字,叫做扩展分区,而未被改变的叫做主分区。因为有了以前的经验,扩展分区中可以记录无数了分区,这些在扩展分区中的分区被叫做逻辑分区。总结起来如图

但由于分区表依然太小,导致无法支持2TB以上的大硬盘。
GPT标准
GPT方案中只有一种分区类型,主分区。磁盘和RAID卷中包含的分区数量没有限制,并且支持2TB以上的大硬盘。
GUID Partition Table (GPT) 是 Unified Extensible Firmware Interface 标准定义的分区规范。使用 GUID 或 Linux 中的 UUID 来定义分区和分区类型。设计上就是为了替换MBR标准的。在MBR标准中提到启动加载器储存在哪512个字节中。那GPT的启动加载器在哪呢?答案是与GPT对应的UEFI标准中规定必须要分出一个ESP分区,用作启动。
Linux下常见的文件系统为ext4,windows下最推荐的文件系统是NTFS
二、如何理解系统调用
在讲到系统调用之前首先要提到操作系统,负责完成所有与硬件因素相关的(硬件相关)和任何用户共需的(应用无关)基本使用工作,老师上课给出了非常生动形象的比喻,硬件相关是管家婆、应用无关是服务生。
关于库函数和系统调用
库函数是高层的,完全运行在用户空间, 为程序员提供调用真正的在幕后完成实际事务的系统调用的更方便的接口。系统调用在内核态运行并且由内核自己提供。标准C库函数printf() 可以被看做是一个通用的输出语句,但它实际做的是将数据转化为符合格式的字符串并且调用系统调用 write() 输出这些字符串。
你可以用高级语言和汇编语言的关系来理解库函数和系统调用的关系
从程序完成的功能来看,函数库提供的函数通常是不需要操作系统的服务,函数是在用户空间内执行的,除非函数涉及到I/O操作等,一般是不会切到核心态的。系统调用 是要求操作系统为用户提供进程,提供某种服务,通常是涉及系统的硬件资源和一些敏感的软件资源等。
函数库的函数,尤其与输入输出相关的函数,大多必须通过Linux的系统调用来完成。因此我们可以将函数库的函数当成应用程序设计人员与系统调用程序之间 的 一个中间层,通过这个中间层,我们可以用一致的接口来安全的调用系统调用。这样程序员可以只要写一次代码就能够在不同版本的linux系统间使用积压种具 体实现完全不同的系统调用。至于如何实现对不同的系统调用的兼容性问题,那是函数库开发者所关心的问题。
从程序执行效率来看,系统调用的执行效率大多要比函数高,尤其是处理输入输出的函数。当处理的数据量比较小时,函数库的函数执行效率可能比较好,因为函数 库的作法是将要处理的数据先存入 缓冲区内,等到缓冲区装满了,再将数据一次写入或者读出。这种方式处理小量数据时效率比较高,但是在进行系统调用时,因为用户进程从用户模式进入系统核心 模式,中间涉及了许多额外的任务的切换工作,这些操作称为上下文切换,此类的额外工作会影响系统的执行效率。但是当要处理的数据量比较大时,例如当输入输 出的数据量超过文件系统定义的尽寸时,利用系统调用可获得较高的效率。
strace 加执行文件名
使用命令gcc -Wall -o hello hello.c 编译。用命令 strace hello 跟踪该可执行文件。是否很惊讶? 每一行都和一个系统调用相对应。 strace是一个非常有用的程序,它可以告诉你程序使用了哪些系统调用和这些系统调用的参数,返回值。
问题和解决思路
1、如何理解文件描述符fd?
解决:文件描述符:File descriptor,简称fd,当应用程序请求内核打开/新建一个文件时,内核会返回一个文件描述符用于对应这个打开/新建的文件,其fd本质上就是一个非负整数。实际上,它是一个索引值,指向内核为每一个进程所维护的该进程打开文件的记录表。当程序打开一个现有文件或者创建一个新文件时,内核向进程返回一个文件描述符。在程序设计中,一些涉及底层的程序编写往往会围绕着文件描述符展开。但是文件描述符这一概念往往只适用于UNIX、Linux这样的操作系统。
操作系统为每一个进程维护了一个文件描述符表,该表的索引值都从从0开始的,所以在不同的进程中可以看到相同的文件描述符,这种情况下相同的文件描述符可能指向同一个文件,也可能指向不同的文件,具体情况需要具体分析

2、如何查看文件状态
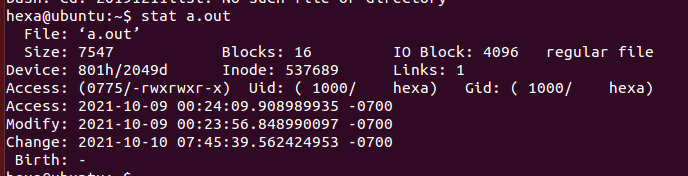
3、如何查看目录
目录是用于保存其它文件的节点号和名字的文件,目录文件中的每个数据项都是指向某个文件节点的链接,删除文件名就等于删除与之对应的链接。删除一个文件时,实际上是删除了该文件对应的目录项,同时指向该文件的链接数减1,如果指向某个文件的链接数为0,则该节点及其指向的数据不再被使用,磁盘上相应的位置就被标记为可用空间。
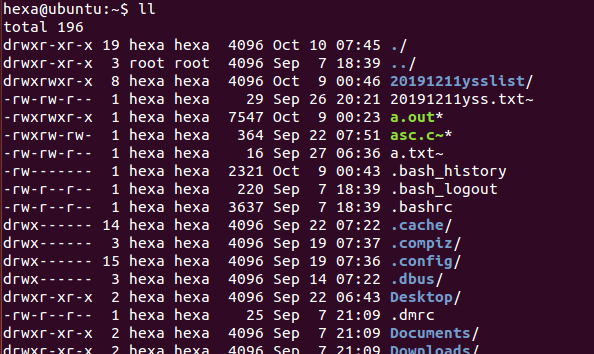
4、Write系统调用实践
把缓冲区buf前nbytes个字节写入与文件描述符fildes关联的文件中,返回实际写入的字节数。函数返回0,则未写入任何数据,返回-1则表示在write调用中出现错误,错误代码保存在全局变量errno中。
#include<unistd.h>
#include<stdlib.h>
int main()
{
const char *p = "hello world";
if(write(1,p,11)!=11)
write(2,"error
",6);
pause();
exit(EXIT_SUCCESS);
}
