神经网络也是机器学习的一种方法,是深度学习的基础。这是一种模拟生物神经系统实现人工智能的一种技术。要学习神经网络,就要从最经典的“M-P神经元模型”开始,这是神经网络乃至深度学习的基础,也是这个算法为什么被称为“神经网络”的原因。
-- M-P神经元模型

图1表示的是生物学上的神经元结构,一个神经元有多个树突,主要用来接收信息的传入;轴突只有一条,轴突尾端的末梢和其他神经元的树突相连,可以给其他神经元传递信息;细胞核则决定传递什么样的信息。
图2是1943年就已经提出来的M-P神经元模型,这是由神经生理学家McCulloch和计算数学家Pitts联合提出,所以采用两人名字的首字母“M-P”为这个模型命名。
M-P神经元模型包含输入、输出与计算功能,输入相当于树突,接受来自n个神经元的信号,而这些输入信号通过带权重的连接进行传递;而输出则相当于轴突,计算则相当于细胞核。图2中神经元对所有输入信号进行加权求和后与阈值比较,然后通过激活函数处理产生该神经元的输出。将多个神经元按照输入-输出的关系连接起来,就形成一个神经网络,这个神经网络中最重要就是神经元之间的连接,也就是权重,我们训练神经网络的过程,其实就是确定这些权重取值的过程,让这些权重调整到一个最佳值,使得整个神经网络的预测效果最好。
-- 感知机
感知机是最简单的神经网络模型,只由输入层和输出层组成,也称为单层神经网络(只有输出层一层具有计算功能)。我们来看一个简单的例子来理解什么是感知机。
小明考虑明天要不要开车去公司,他决定考虑3个因素,取值都为是(1)或否(0),这就作为感知机的输入:
1、天气:明天是否下雨;
2、交通:明天预计道路是否顺畅;
3、同伴:明天是否有同伴一起分摊油费。
有了输入,还要有权重,这些因素的重要性不尽相同,越重要,权重就越高,假设:
天气:权重为8
交通:权重为6
同伴:权重为4
感知机决策模型如下,x1/x2/x3分别代表天气、交通、同伴,输入与神经元的连接代表权重w,神经元的阈值假设为8。如果3个条件都是1,则8*1+6*1+4*1 = 18 > 8,小明决定明天开车去上班。如果明天不下雨,交通又堵,但有同伴一起,0*8 + 6*0 +4*1 = 4 < 8,则小明决定明天不开车。

感知机是神经网络中最简单的一种形式,只能处理最简单的线性问题,现实中运用的神经网络要复杂得多,不仅有输入层、输出层,还有若干隐藏层,这样,整个神经网络中的权重参数会变得很多,对于特征的表示就越丰富。就可以解决很多非线性的分类问题。
图3.含隐藏层的神经网络
图4. 单层神经网络分类 图5. 两层神经网络分类 图6. 多层神经网络分类
从上面的图可以看到,加入隐藏层的目的,其实是对原始输入数据进行空间变换,使得在原始空间内不能线性可分的数据在新的空间内能够被线性分类。从数学公式上也能看出,输入向量(原始数据x)和矩阵(隐藏层权重w)相乘,本质上就是对向量的坐标空间进行变换。这样,就不难理解,神经网络层数越多、神经元越多,对于非线性问题的描述就越强,能拟合更复杂的非线性函数。
-- 损失函数与梯度下降求解
模型确定好之后,就可以开始对数据进行训练学习了,但模型训练中,我们怎么判断学习到的参数是合适的呢,换句话说,以什么依据来判定模型的好坏呢?这里就要引入损失函数(loss function),也称为代价函数,用来表示模型预估值与真实值之间不一致的程度,例如可以使用平方损失函数:e叫做单个样本的误差
![]()
从总体来看,我们要使得整个训练集数据平方误差越小越好,则可以得到整个模型的目标函数:
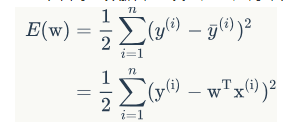
我们训练的目的就是使得这个目标函数尽可能小,这样,模型预估值和真实值之间才能尽可能接近。问题也就变为通过求得更优的参数w,使得目标函数E(w)最小。
要使得E(w)取极小值,就需要用到我们大学时学到的知识了,函数 y = f(x)的极值点,就是它的导数为0的那个点。基于梯度的搜索(梯度下降)是使用最为广泛的参数寻优方法。梯度,是一个向量,它总是指向函数值上升最快的方向,我们总是寻着梯度的反方向就是函数值下降最快的方向去修改x,就在逐渐逼近极小值了。

首先我们随机选取一点作为起始点(图中X0),然后不断迭代计算目标函数在当前点的梯度,不断朝着负梯度方向搜索,直到梯度为0,则表明已找到局部最小值(如果目标函数仅有一个局部最小值,那么这就是全局最小值),参数迭代更新也将停止。局部最小值不是我们所追求的,怎么能避免落入“局部最小值”的陷阱呢,业界提供了两种策略:
(1)采用多组不同的随机参数值初始化神经网络,训练后取目标函数最小的作为最终参数。相当于从多个不同的点开始搜索最小值,通过比较找到最接近于全局最小值的点。
(2)采用随机梯度下降算法,算法中加入了随机因素,即使陷入“局部最小值”,梯度仍不为0,这样就可跳出局部最小值继续搜索。
梯度下降算法中有一个关键的超参数:学习率(learning rate),它决定了梯度下降过程中参数更新的幅度,下面图中形象的表示了学习率的作用:

学习率太小,会导致模型参数收敛得很慢,需要很长时间才能找到最小值;但学习率太大,会导致跳过最小值,所以,选取合适的学习率是关键。
-- 激活函数(Activation function)
激活函数的作用是为神经网络引入非线性因素,使得神经网络能更好地解决一些复杂问题。激活函数会作用到每一个神经元上,而且每层的激活函数可以不同。通常激活函数需要具有以下性质:
(1)非线性;
(2)可微性;
(3)单调性;
常见的几种激活函数:
(1)Sigmoid函数

它能将输入的连续值压缩到0和1之间,但现在用得越来越少了,主要是会引起“梯度消失”的问题,而且收敛速度也比较慢。
(2)tanh函数
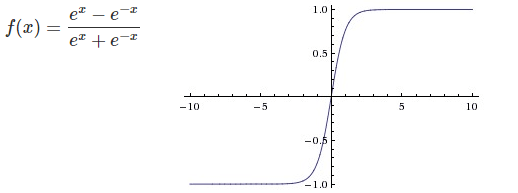
tanh函数相比sigmoid收敛速度更快,但还是存在“梯度消失”的问题。
(3)ReLU函数

Relu是现在用得最多的激活函数,它不仅能够快速收敛,并且有效地缓解了“梯度消失”的问题。
-- 反向传播算法(BP)
神经网络训练依赖是反向传播算法(Back Propagation),神经网络训练的目的,就是确定各层神经元连接的权值。BP算法会随机初始化模型中的所有权值和偏置,根据训练集中每个输入x和输出y,从后往前,逐层更新参数,首先计算输出层的梯度,然后是中间隐藏层的梯度,最后是输入层的梯度。BP的详细推导比较复杂,如果想详细了解,可参考 https://www.cnblogs.com/charlotte77/p/5629865.html ,不理解详细推导过程也没关系,不影响我们训练和应用模型。
-- MNIST手写数字识别实战
MNIST手写数字识别是深度学习领域最经典的一个入门实例,网上已经有很多介绍,这里就不多讲了,用两个神经网络的模型对比看看有什么区别。第一个是无隐层的神经网络,第二个是含200个神经元隐层的神经网络,后面附上代码和准确率、loss的曲线图,看看二者有什么区别。

无隐层神经网络:准确率92.7%
import tensorflow as tf
import os
import numpy as np
from tensorflow.examples.tutorials.mnist import input_data
os.chdir("/home/z00421185/zhoujie_project")
mnist = input_data.read_data_sets("/home/z00421185/zhoujie_project/MNIST/", one_hot=True)
x = tf.placeholder(tf.float32, [None, 784])
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))
y = tf.nn.softmax(tf.matmul(x, W) + b)
y_ = tf.placeholder(tf.float32, [None, 10])
cross_entropy = -tf.reduce_sum(y_ * tf.log(y))
learning_rate = 0.001
train_step = tf.train.AdamOptimizer(learning_rate).minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
writer = tf.summary.FileWriter('./tf_log/graphs', tf.get_default_graph())
summary_loss = tf.summary.scalar("Training Loss", cross_entropy)
summary_accuracy = tf.summary.scalar("Training Accuracy", accuracy)
merged = tf.summary.merge_all()
for i in range(20000):
batch_xs, batch_ys = mnist.train.next_batch(100)
result, _ = sess.run([merged, train_step], feed_dict={x: batch_xs, y_: batch_ys})
writer.add_summary(result, i)
print(sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels}))含隐层的3层神经网络:准确率98.14%
import tensorflow as tf
import os
import numpy as np
from tensorflow.examples.tutorials.mnist import input_data
os.chdir("/home/z00421185/zhoujie_project")
mnist = input_data.read_data_sets("/home/z00421185/zhoujie_project/MNIST/", one_hot=True)
x = tf.placeholder(tf.float32, [None, 784])
W1 = tf.Variable(tf.truncated_normal([784, 200], stddev=0.1))
W2 = tf.Variable(tf.truncated_normal([200, 10], stddev=0.1))
b1 = tf.Variable(tf.zeros([200]))
b2 = tf.Variable(tf.zeros([10]))
y1 = tf.nn.sigmoid(tf.matmul(x, W1) + b1)
y = tf.nn.softmax(tf.matmul(y1, W2) + b2)
y_ = tf.placeholder(tf.float32, [None, 10])
cross_entropy = -tf.reduce_sum(y_ * tf.log(y))
learning_rate = 0.001
train_step = tf.train.AdamOptimizer(learning_rate).minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
writer = tf.summary.FileWriter('./tf_log/graphs2', tf.get_default_graph())
summary_loss = tf.summary.scalar("Training Loss_1", cross_entropy)
summary_accuracy = tf.summary.scalar("Training Accuracy_1", accuracy)
merged = tf.summary.merge_all()
for i in range(20000):
batch_xs, batch_ys = mnist.train.next_batch(100)
result, _ = sess.run([merged, train_step], feed_dict={x: batch_xs, y_: batch_ys})
writer.add_summary(result, i)
print(sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels}))20000次迭代,训练准确率和loss曲线如下图,只是增加了一层隐层,准确率就从92.7%提升到98.14%,从下面两张图上也可以看出模型有很好的提升。

作者:华为云专家周捷
@All开发者,想获取满满的技术干货吗?想了解最前沿的技术洞察吗?想得到最权威的学习认证吗?还有多维的交流平台以及有趣的有奖互动?
2020年华为开发者大会将于2月11-12日在深圳举办,这将是华为面向开发者群体的最顶级盛会,包含但不限于华为在云计算、人工智能、5G、IoT等多个领域,特别是智能计算双引擎鲲鹏和昇腾的最新创新与最佳实践,充满期待对吧,欢迎报名预约!
往期文章精选
javascript基础修炼(13)——记一道有趣的JS脑洞练习题