| 作业要求 | 作业要求 |
|---|---|
| 作业目标 | 学会用cookie模拟登陆网页并爬取数据 |
| 作业源代码 | 码云仓库 |
| 队员1 | 211806352 |
| 队员2 | 211806304 |
| 一、结对过程 |
| 1、结对感受 |
作业总结:本次作业的任务是在上次作业的基础上进行代码升级,做起来比较轻松,所以这次作业的思路十分清晰,方向
也很明确。
我和我的队友,先按要求写好了所有的思路要求分析后才开始编程,这样的效率会更快,我们合作地十分愉快。
| 2、对方评价 |
谢道彤对陈创的评价:陈创同学非常细心,在编程过程中很注重代码注释的编写,认为这是一个非常重要的编程习惯,一定
要养成这个习惯,在这次作业中他的提议让我明白了很多
陈创对谢道彤的评价:谢道彤同学遇到问题会先自己思考,然后再去参考一些资料,是我学习的榜样。
| 二、结对照片 |

| 三、时间分配 |
| 估计 | 实际 | |
|---|---|---|
| 代码行数 | ---- | 194 |
| 思路 | 10分钟 | 5分钟 |
| 理出逻辑 | 20分钟 | 40分钟 |
| 编程 | 120分钟 | 240分钟 |
| 测试 | 10分钟 | 20分钟 |
| 博客 | 100分钟 | 120分钟 |
| 总计 | 260分钟 | 425分钟 |
| 四、思路分析 |
| 1、编程思路 |
②从网页爬取经验
③爬取的经验信息经过排序处理
④写入最终的文件
⑤将文件Git到码云仓库
| 2、方法分类 |
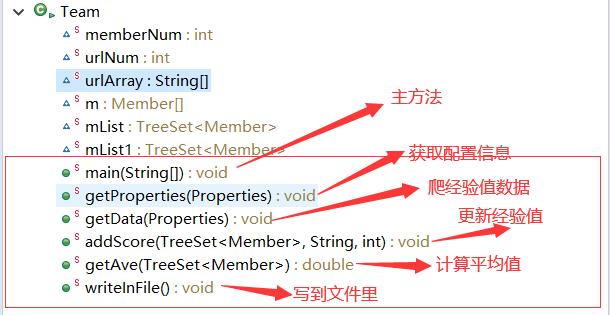
| 五、编程过程 |
首先,我们要明白,经验值这个数据不是每个访问网页的游客所能能看到的,要登陆才能看到这些数据。老师这次要求直接
用网页爬数据,
同时也说明了要用到cookie。OK那第一步就是获取我们云班当前登陆的cookie,不用打开百度,我告诉你,我们先这样:
①在云班课活动页面按F12,进入开发者模式
②找到它再点它

③按F5刷新网页,会出现这个,点一下它

④找到cookie,一整串复制粘贴到创建的配置文件里

⑥在java中模仿下面这三句话,然后document里就是你要处理的网页数据啦,url就是活动页面浏览器地址栏的地址
Properties con = new Properties();
con.load(new FileInputStream("resources/config.properties"));
Document document = Jsoup.connect(con.getProperty("url")).header("Cookie", con.getProperty("cookie")).get();
⑦拿到doc后,接下来就可以模仿着上次作业内容来爬数据了。只是变化一下而已,不会很难。
⑧用对象数组存学生的信息,再用 Comparator 或者其他接口按要求对数据进行排序,最后用这招写到文件里去就OK啦

⑨我们在排序这里卡了很久,原因是之前作业没有好好理解 Comparator 接口,经过这次的教训,我已经深深体会到温故
知新的重要性了。
⑩最终输出

| 六、git到码云仓库 |
1、仓库建好后配置三步走
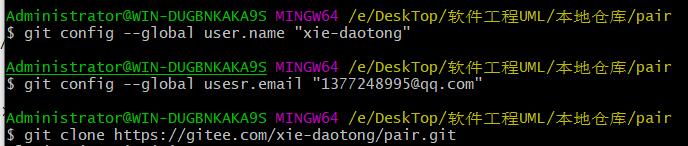
2、文件上传四步走
先把要传的文件放到pair文件夹里



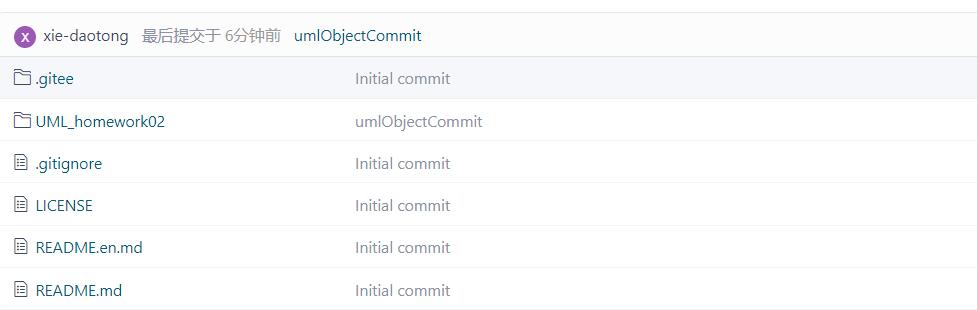
3、成果
| 七、学习成果 |
1、学会了用cookie模拟登陆网页
2、重新学习了 Comparator 接口
3、体会到结对编程的快乐