1. 用requests库和BeautifulSoup库,爬取校园新闻首页新闻的标题、链接、正文。
import requests from bs4 import BeautifulSoup res = requests.get('http://news.gzcc.cn/html/xibusudi/') res.encoding = 'UTF-8' soup = BeautifulSoup(res.text, 'html.parser') # print(soup) for news in soup.select('li'): if len(news.select('.news-list-text'))>0: time = news.select('.news-list-info')[0].contents[0].text name = news.select('.news-list-title')[0].text sout= news.select('.news-list-info')[0].contents[1].text print(time,name,sout) link = news.select('a')[0].attrs['href'] resd = requests.get(link) resd.encoding = 'UTF-8' soupd = BeautifulSoup(resd.text, 'html.parser') print(soupd.select('#content')[0].text)

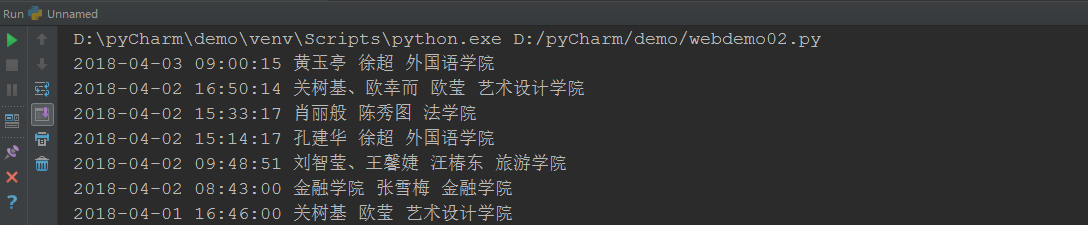
2. 分析字符串,获取每篇新闻的发布时间,作者,来源,摄影等信息。
info = soupd.select('.show-info')[0].text # print(info) dt = info.lstrip('发布时间:')[:19] at = info[info.find('作者:'):].split()[0].lstrip('作者:') sh = info[info.find('审核:'):].split()[0].lstrip('审核:') ly = info[info.find('来源:'):].split()[0].lstrip('来源:') print(dt, at, sh, ly)
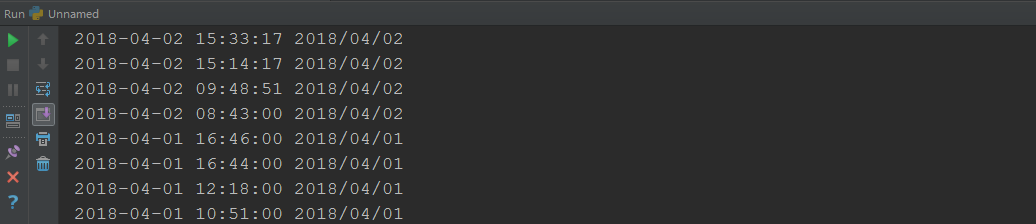
3. 将其中的发布时间由str转换成datetime类型。
dati = datetime.strptime(dt, '%Y-%m-%d %H:%M:%S') print(dati, dati.strftime('%Y/%m/%d'))