1. 介绍
JVM提供了多种垃圾收集器,应该根据应用选择一种合适的垃圾收集器。
垃圾回收管理内存通过如下操作:
在年轻代分配对象,把年龄大的对象晋升到老年代。
当年老代超过阈值的时候,并发标记收集。
通过合并内存,拷贝内存的方式对内存进行整理,回收可以内存。
垃圾回收什么时候会产生问题?对于有些应用,垃圾回收永远都不会成为问题,有些应用在垃圾回收期间短暂的暂
停,适当的垃圾回收频率下也可以表现的很好。
阿姆达尔定律(http://ifeve.com/amdahls-law/)意味着程序的性能受限于不可并行的部分;有些部分工作
总是要串行处理,没法通过并行来提升性能。这个定理同样适用于Java平台。特别是Java1.4以前没有并行的垃圾
收集器,所以在GC时候的停顿造成的问题在多核的系统中会更明显。
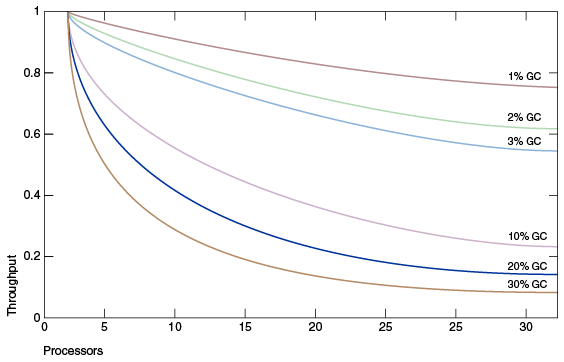
以上这幅图展示了这个关系,红色线是一个应用1%的GC时间下,吞吐量单核下为1,32核的时候就下降了
20%,到了0.8。粉红色的线是一个应用10%的GC时间下,32核下吞吐量下降了大概75%。
这幅图还说明一个问题,GC很短时间的停顿,对于大型系统可能会成为主要的性能瓶颈。同时,对于GC时间
很小的提升也可以很大的提升性能。对于一个大型系统选择一个合适的垃圾收集器变得十分重要。
串行垃圾收集器对于小型应用通常是够用的。大型的应用,需要大量内存或者需要运行在多核上的应用,应该
选择并行收集器。
2. JVM默认配置
默认的垃圾回收器,堆选择
假设放class文件的机器是如下配置:
CPU核数大于等于2
物理内存大于等于2G
那么默认的选择如下:
吞吐量(并行)垃圾收集器
初始堆大小是物理内存的1/64,最大到1G
最大堆大小是物理内存的1/4,最大到1G
对于64位的系统,最大内存参考并行垃圾收集器。
目标决定了垃圾回收的选择
对于吞吐量收集器,Java SE提供了两个参数来调整是选择限制最大停顿时间,还是吞吐量优先;这两个设置在其
他垃圾收集器是没用的。
最大GC停顿时间优先
设置-XX:MaxGCPauseMillis=<nnn>以后,系统的GC停顿时间少于nnn毫秒,垃圾收集器会调整堆大小和其他相
关参数来保持GC停顿时间少于nnn毫秒。这个参数会导致垃圾收集器更频繁的收集,降低应用整体的吞吐量。垃圾
收集器会尽量满足GC停顿时间不超过nnn,尽管在有些情况下,也可能满足不了。
吞吐量优先
设置-XX:GCTimeRatio=<nnn>以后,系统垃圾收集的时间 比 应用时间应该是 1/1+nnn。例如设置nnn为19,那么GC停顿时间的占比应该小于等于5%。
最小内存
如果最大GC停顿时间和吞吐量有些已经被满足,垃圾收集器会减低堆内存大小,直到吞吐量不能被满足。
调整策略
不要选择最大堆内存,除非你确定需要比默认堆内存最大值大的空间,选择吞吐量的对你的应用就够用了。
堆内存会自动增长和减少来支持设置的吞吐量。
3. Java可用的垃圾收集器
串行收集器,使用单线程收集,不需要线程通信。这个收集器是单核的机器最好的选择,因为他没法利用多核
处理器,如果多核中内存大小小于100MB也是不错的选择。设置-XX:+UseSerialGC。
并行收集器,也叫作吞吐量收集器,在执行年轻代收集的时候是并行的,这样很明显的就减少了垃圾收集开
销。适用于中大型应用,运行在多核硬件上。设置-XX:+UseParallelGC。并行收集器有一个特性,可以在老年代
的回收的时候并行收集,设置-XX:+UseParalleOldGC。
并发收集器,为了追求更短的响应时间,牺牲整体吞吐率,因为更短的停顿时间会降低应用性能。有两个收集器是并发收集,-XX:+UseConcMarkSweepGC CMS收集器,-XX:+UseG1GC G1收集器
选择合适的收集器
100MB以下的堆使用串行收集器
应用运行在单核的机器,并且对GC停顿时间有要求,让JVM自己选择垃圾回收器或者使用串行收集器
如果追求应用性能峰值为第一优先级,对GC停顿时间没有太多要求,或者可以接收1秒以上的延迟,让JVM自己选中垃圾收集器或者使用并行收集器
如果响应时间更重要,GC停顿时间必须少于1秒,使用CMS或者G1收集器
4. 并行收集器
在新生代和老年代都并行收集。8核以下的机器,会开8个线程来并行回收,8核以上的会用N*5/8的线程来收集,有些操作系统上是N*5/16的线程,也可以通过-XX:ParallelGCThreads=<N>手动设置。
在单核的机器上并行收集器还不如串行收集器,但是内存比较大的时候,双核的机器并行收集器就会优于串行收集器,并随着核数的增加而明显增加。并行收集的线程越多停顿时间会越短。线程太多会有
碎片问题。每个线程会在老年代预留一部分空间来让新生代中的对象晋升
分代
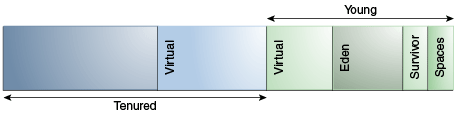
针对行为的参数设置
最大停顿时间,第一优先级
吞吐量,第二优先级
最小内存,第三优先级
分代内存大小调整
默认的,按照20%增长,5%缩小。-XX:YoungGenerationSizeIncrement=<Y> 可以配置新生代增长的大小,-XX:TenuredGenerationSizeIncrement=<T>配置老年代增长的大小,
-XX:AdaptiveSizeDecrementScaleFactor=<D>可以配置缩小的比例,假设内存增长的比率是X那么缩小的比例是 X/D。
哪一代的最大GC时间如果不满足阈值,那么会缩小那一代的内存,如果两代都不满足,那么缩小需要时间长的那代的内存。
吞吐量不满的话,两代内存都增加
5. 并发收集器
Java提供两种并发收集器:
CMS收集器,这个收集器有更少的停顿时间
G1收集器,这个收集器用于多核机器,大内存。满足最少停顿时间,和高吞吐量
并发收集的开销
最大开销是在垃圾回收的时候使用一个和多个核。在一个N核的系统中,并发收集器会用K/N个核心,1<K<4/N。停顿时间由
于并发降低,这会导致在并发收集阶段,留个应用程序可以用的CPU资源变少。机器和核数增加,这种CPU资源的减少会变少,
但是CMS收集器带来的并发收集好处会更明显。
6. CMS收集器
CMS收集器是为了更短的垃圾收集停顿时间设计的,并且可以垃圾收集器和应用程序可以共享CPU资源一起同时运行。一个应
用有一个很大的常住内存的数据在多核的机器运行倾向于使用这种收集器。
并发失败
当CMS收集器与用户线程一起工作,垃圾回收还没完成收集而老年代满了,或者老年代没有连续的可用大内存,那么垃圾回收
器会使用户线程停止,等待垃圾收集完成。
GC时间过长和OutOfMemoryError
CMS收集器收集时间过长会抛出OutOfMemoryError:如果超过98%的时间用来做GC,收集后增加的可用内存不足总内存的
2%,会抛出OutOfMemoryError。
浮动垃圾
因为收集器和用户线程是并行的,所以会产生浮动垃圾,需要等待下次垃圾回收被回收
GC停顿
CMS停顿两次。第一次停顿标记GC ROOTS的可达对象。第二次停顿发生在并发之后,补充并发期间应用线程对对
象的引用。
并发标记阶段
并发标记发生在第一次GC停顿和第二次之间。并发标记和应用线程一起执行,第二次标记结束以后确定哪些对象是不可达,进
入到下一个并发清理阶段
CMS收集的开始生命周期
串行收集器是老年代满了再收集,作为对比CMS需要定时收集,并且在老年代满之前就需要收集完,不然的话应用会进入更长
时间的GC停顿,因为并发失败。有如下几种方式开始CMS收集。
基于历史,CMS收集器会预估老年代满的时间,在之前开始CMS收集。
CMS还会在超过老年代用量阈值的时候进行收集。默认阈值大约是老年代的92%,这个值也是动态变化的。通过-
XX:CMSInitiatingOccupancyFraction=<N>可以调整阈值,N是0-100的老年代比率。
调度暂停
老年代和年轻代的垃圾收集器是独立的, 他们之间停顿相互不重叠,但是可以交替停顿,这个交替停顿看起来会像是一次长的
停顿。为了避免这样,CMS新生代的收集器尝试调用发生在第一次标记和重标记之间。
7. G1收集器
G1收集器是对heap的重新认识,他把heap分成大小相等的区域。启动时可以设置区域大小,根据内存大小的不同可以设置从
1MB到32MB。区域的划分不要超过2048个。以前的eden,survivor和old区是这些每个区域块,但不是连续的。
G1收集器会尽量满足设置的GC停顿时间,自动调整年轻代内存的大小。
以上内容总结自oracle的原文,出处地址,http://docs.oracle.com/javase/8/docs/technotes/guides/vm/gctuning/index.html
GC优化的目标,吞吐量,延迟,内存使用。
吞吐量是单位时间处理的请求,延迟是一个请求的处理时间。为什么这两个不是一回事,有没有延迟低,但是吞吐量少的。比如,火车用100小时能把10000T煤从山西运
到广州, 飞机用20小时能把100T煤从山西运到广州,火车运煤的吞吐量是100T/小时,火车的运煤延迟是0.01小时/吨。飞机的吞吐量是5T/小时,飞机运煤的延迟是
0.2小时/吨。
延迟最优,主要优化目标是GC的平均停顿时间和GC最大停顿时间
吞吐量最优,高吞吐意味着CPU的资源更多的用于用户线程
内存使用最优,内存最优只能增加GC次数和时间来达到目的