我们拿词典做了例子:
1、词典前面的拼音目录-----》聚集索引
2、词典前面的部首目录-----》非聚集索引
3、词典正文(意思是去掉拼音和部首目录)-----》数据表的物理存储
以SqlServer为例:有一张表,表结构如下:
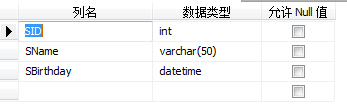
1、不建立主键的情况下:插入几条记录(这个情况下相当于一个词典的正文没有按照拼音进行排序,是乱放的)
INSERT [dbo].[Student] ([SID], [SName], [SBirthday]) VALUES (6, N'docker', CAST(0x000082E600000000 AS DateTime)) INSERT [dbo].[Student] ([SID], [SName], [SBirthday]) VALUES (7, N'empty', CAST(0x000082E600000000 AS DateTime)) INSERT [dbo].[Student] ([SID], [SName], [SBirthday]) VALUES (8, N'fifth', CAST(0x000082E600000000 AS DateTime)) INSERT [dbo].[Student] ([SID], [SName], [SBirthday]) VALUES (9, N'zoo', CAST(0x000082E600000000 AS DateTime))
INSERT [dbo].[Student] ([SID], [SName], [SBirthday]) VALUES (1, N'Allen', CAST(0x0000817900000000 AS DateTime))
INSERT [dbo].[Student] ([SID], [SName], [SBirthday]) VALUES (2, N'Andy', CAST(0x000082E600000000 AS DateTime))
INSERT [dbo].[Student] ([SID], [SName], [SBirthday]) VALUES (3, N'bob', CAST(0x000082E600000000 AS DateTime))
INSERT [dbo].[Student] ([SID], [SName], [SBirthday]) VALUES (4, N'bily', CAST(0x000082E600000000 AS DateTime))
INSERT [dbo].[Student] ([SID], [SName], [SBirthday]) VALUES (5, N'cindy', CAST(0x000082E600000000 AS DateTime))
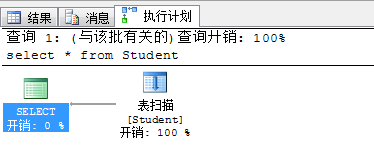
执行sql语句:select * from Student --- 没有排序字段,查询出的就是数据物理存储到数据页中的顺序:

这个顺序呢就是按照你记录添加进的顺序。
再看“查询分析器”:执行了“表扫描”,就是去查询整个物理表了,这里演示的数据少,无所谓,如果是几千万条,就要花费很久的时间了。
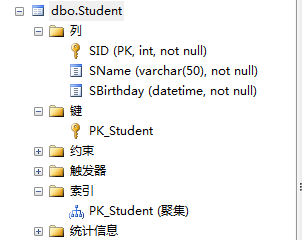
2、建立主键。--建立主键后,数据库会自动创建一个“聚集索引”,作用呢,就是把物理存储顺序按照聚集索引的数序重新排列一遍。
然后,我们重新查询一遍:select * from Student
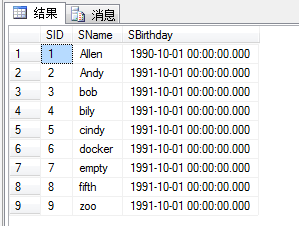
结果变了,按照顺序进行了重新存储。
并且,看“查询分析器”:走的是聚集索引扫描。---->聚集索引就是个文件,里面放的就是对应关系(相当于词典前面的拼音目录)

3、建立“非聚集索引”。

执行查询:select * from Student where sname='docker'
查询分析器:

还是走的聚集索引,这是为什么呢?为什么没有走非聚集索引呢??----非聚集索引中的临界点(Tipping Point)