一.集合
一)作用:集合 list tuple dict一样都可以存放多个值,但实际和主要用于:去重 关系运算
二)定义:在{}内用逗号分隔开多个元素,集合具备以下三个特点:
1:每个元素必须是不可变类型
2:集合内没有重复的元素
3:集合内元素无序
1 s = {1,2,3,4} # 本质 s = set({1,2,3,4})
# 注意1:列表类型是索引对应值,字典是key对应值,均可以取得单个指定的值,而集合类型既没有索引也没有key与值对应,所以无法取得单个的值,而且对于集合来说,主要用于去重与关系元素,根本没有取出单个指定值这种需求。
# 注意2:{}既可以用于定义dict,也可以用于定义集合,但是字典内的元素必须是key:value的格式,现在我们想定义一个空字典和空集合,该如何准确去定义两者?
d = {} # 默认是空字典
s = set() # 这才是定义空集合
三)类型转换:
但凡能被for循环的遍历的数据类型(强调:遍历出的每一个值都必须为不可变类型)都可以传给set()转换成集合类型
1 >>> s = set([1,2,3,4])
2 >>> s1 = set((1,2,3,4))
3 >>> s2 = set({'name':'jason',})
4 >>> s3 = set('egon')
5 >>> s,s1,s2,s3
6 {1, 2, 3, 4} {1, 2, 3, 4} {'name'} {'e', 'o', 'g', 'n'}
四)
1)关系运算
我们定义两个集合S1与S2分别存放两个相同的名字:
1 S1={'小明','小美','小红','小燕'}
2 S2={'小文','小琴','小红','小燕'}
关系图如下:
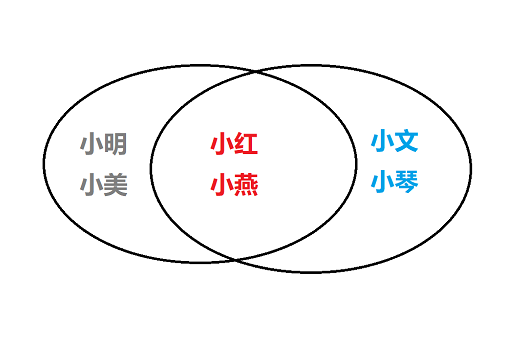
1 # 1.合集(|):求两个用户所有的好友(重复好友只留一个)
2 >>> friends1 | friends2
3 {'小明','小美','小红','小燕','小文','小琴'}
4
5 # 2.交集(&):求两个用户的共同好友
6 >>> S1& S2
7 {'小红','小燕''}
8
9 # 3.差集(-):
10 >>> S1- S2# 求用户1独有的好友
11 {'小明','小美'}
12 >>> friends2 - friends1 # 求用户2独有的好友
13 {'小文','小琴'}
14
15 # 4.对称差集(^) # 求两个用户独有的好友们(即去掉共有的好友)
16 >>> friends1 ^ friends2
17 {'小明','小美','小文','小琴'}
18
19 # 5.值是否相等(==)
20 >>>S1 == S2
21 False
22
23 # 6.父集:一个集合是否包含另外一个集合
24 # 6.1 包含则返回True
25 >>> {1,2,3} > {1,2}
26 True
27 >>> {1,2,3} >= {1,2}
28 True
29 # 6.2 不存在包含关系,则返回True
30 >>> {1,2,3} > {1,3,4,5}
31 False
32 >>> {1,2,3} >= {1,3,4,5}
33 False
34
35
36 # 7.子集
37 >>> {1,2} < {1,2,3}
38 True
39 >>> {1,2} <= {1,2,3}
40 True
2.去重
1 1、只能针对不可变类型去重
2 print(set([1,1,1,1,2]))
3
4 2、无法保证原来的顺序
5 l=[1,'a','b','z',1,1,1,2]
6 l=list(set(l))
7 print(l)
8
9
10 l=[
11 {'name':'lili','age':18,'sex':'male'},
12 {'name':'jack','age':73,'sex':'male'},
13 {'name':'tom','age':20,'sex':'female'},
14 {'name':'lili','age':18,'sex':'male'},
15 {'name':'lili','age':18,'sex':'male'},
16 ]
17 new_l=[]
18 for dic in l:
19 if dic not in new_l:
20 new_l.append(dic)
21
22 print(new_l)
3.其他操作方法
1 其他内置方法
2 s={1,2,3}
3 需要掌握的内置方法1:discard
4 s.discard(4) # 删除元素不存在do nothing
5 print(s)
6 s.remove(4) # 删除元素不存在则报错
7
8
9 需要掌握的内置方法2:update
10 s.update({1,3,5})
11 print(s)
12
13 需要掌握的内置方法3:pop
14 res=s.pop()
15 print(res)
16
17 需要掌握的内置方法4:add
18 s.add(4)
19 print(s)
其余方法全为了解
res=s.isdisjoint({3,4,5,6}) # 两个集合完全独立、没有共同部分,返回True
print(res)
了解
s.difference_update({3,4,5}) # s=s.difference({3,4,5})
print(s)
二.字符编码
分析过程
x="上"
内存
上-------翻译-----》0101010
上《----翻译《-----0101010
字符编码表就是一张字符与数字对应关系的表
a-00
b-01
c-10
d-11
ASCII表:
1、只支持英文字符串
2、采用8位二进制数对应一个英文字符串
GBK表:
1、支持英文字符、中文字符
2、
采用8位(8bit=1Bytes)二进制数对应一个英文字符串
采用16位(16bit=2Bytes)二进制数对应一个中文字符串
unicode(内存中统一使用unicode):
1、
兼容万国字符
与万国字符都有对应关系
2、
采用16位(16bit=2Bytes)二进制数对应一个中文字符串
个别生僻会采用4Bytes、8Bytes
unicode表:
内存
人类的字符---------unicode格式的数字----------
| |
| |
|
硬盘 |
|
| |
| |
GBK格式的二进制 Shift-JIS格式的二进制
老的字符编码都可以转换成unicode,但是不能通过unicode互转
utf-8:
英文->1Bytes
汉字->3Bytes
结论:
1、内存固定使用unicode,我们可以改变的是存入硬盘采用格式
英文+汉字-》unicode-》gbk
英文+日文-》unicode-》shift-jis
万国字符》-unicode-》utf-8
2、文本文件存取乱码问题
存乱了:解决方法是,编码格式应该设置成支持文件内字符串的格式
取乱了:解决方法是,文件是以什么编码格式存如硬盘的,就应该以什么编码格式读入内存
3、python解释器默认读文件的编码
python3默认:utf-8
python2默认:ASCII
指定文件头修改默认的编码:
在py文件的首行写:
#coding:gbk
4、保证运行python程序前两个阶段不乱码的核心法则:
指定文件头
# coding:文件当初存入硬盘时所采用的编码格式
5、
python3的str类型默认直接存成unicode格式,无论如何都不会乱码
保证python2的str类型不乱码
x=u'上'
6、了解
python2解释器有两种字符串类型:str、unicode
# str类型
x='上' # 字符串值会按照文件头指定的编码格式存入变量值的内存空间
# unicode类型
x=u'上' # 强制存成unicode