深度学习paddle加载模型之后使用模型报错
在使用paddle加载模型成功之后,只要运行到使用模型的语句就会报错。最开始我一直以为是这个语句本身的问题或是模型的问题,
爆出问题是 无法读取某些图片 can not read the image file : D:Walker estv01zhenframe2.jpg
但是我在百度之后很多的答案并不是我想的问题,大部分都在说是加载图片的问题,可能是虽然图片的格式看着是jpg或是其他,但是只是将图片的后缀修改jpg,没有转码,我尝试转码后并没有用。后来我通过来百度飞桨的群里询问,得到可能是路径不是存在中文的原因,上面我给出路径是已经修改成中文的,所以没有问题。windows中路径问题有很多,所以我们尽量进行英文命名,不用中文命名,有的 / 和 并存在一个路径上也可能会有问题,比如 D:Walker estv01zhen/frame2.jpg,尽量保持统一。
可以读取图片之后我以为问题解决了,但是又出现了其他的问题,
运行到使用模型的语句就是报出如下错误:
Error #15: Initializing libiomp5md.dll, but found libiomp5md.dll already initialized. OMP: Hi
这是在pycharm中运行的报出错误,如果使用jupyter notebook 甚至会直接运行到这句的时候,瞬间内核崩溃,但是这个问题简单,只需要添加两行代码:
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE'
问题就解决了
所有的代码:
import matplotlib import os os.environ['CUDA_VISIBLE_DEVICES'] = '0' import paddlex as pdx import cv2 from random import shuffle, seed base = 'D:Filepascalvoc/VOCdevkit/VOC2012/' from paddlex.det import transforms train_transforms = transforms.Compose([ transforms.MixupImage(mixup_epoch=250), transforms.RandomDistort(), transforms.RandomExpand(), transforms.RandomCrop(), transforms.Resize(target_size=512, interp='RANDOM'), transforms.RandomHorizontalFlip(), transforms.Normalize(), ]) eval_transforms = transforms.Compose([ transforms.Resize(target_size=512, interp='CUBIC'), transforms.Normalize(), ]) #base = 'D:软件谷歌浏览器下载/pascalvoc/VOCdevkit/VOC2012/' train_dataset = pdx.datasets.VOCDetection( data_dir=base, file_list=os.path.join(base, 'train_list.txt'), label_list='labels.txt', transforms=train_transforms, shuffle=True) eval_dataset = pdx.datasets.VOCDetection( data_dir=base, file_list=os.path.join(base, 'val_list.txt'), label_list='labels.txt', transforms=eval_transforms) print("开始加载模型") model = pdx.load_model('YOLOv3/best_model') model.evaluate(eval_dataset, batch_size=1, epoch_id=None, metric=None, return_details=False) import cv2 import time import numpy as np import matplotlib.pyplot as plt import paddlex as pdx import cv2 def video2frame(videos_path, frames_save_path, time_interval): ''' :param videos_path: 视频的存放路径 :param frames_save_path: 视频切分成帧之后图片的保存路径 :param time_interval: 保存间隔 :return: ''' vidcap = cv2.VideoCapture(videos_path) success, image = vidcap.read() count = 0 a = 2 while success: success, image = vidcap.read() count += 1 if count % time_interval == 0: cv2.imencode('.jpg', image)[1].tofile(frames_save_path + "/frame%d.jpg" % count) image_name = 'D:/Walker/testv01/zhen/frame'+ str(a)+'.jpg' start = time.time() result = model.predict(image_name, eval_transforms) print('infer time:{:.6f}s'.format(time.time()-start)) print('detected num:', len(result)) im = cv2.imread(image_name) font = cv2.FONT_HERSHEY_SIMPLEX threshold = 0.01 for value in result: xmin, ymin, w, h = np.array(value['bbox']).astype(np.int) cls = value['category'] score = value['score'] if score < threshold: continue cv2.rectangle(im, (xmin, ymin), (xmin+w, ymin+h), (0, 255, 0), 4) cv2.putText(im, '{:s} {:.3f}'.format(cls, score), (xmin, ymin), font, 0.5, (255, 0, 0), thickness=2) cv2.imwrite(image_name, im) plt.figure(figsize=(15,12)) plt.imshow(im[:, :, [2,1,0]]) a = a + 2 # if count == 20: # break print(count) if __name__ == '__main__': videos_path = 'qq01.mp4' frames_save_path = 'D:/Walker/testv01/zhen/' time_interval = 2 # 隔一帧保存一次 video2frame(videos_path, frames_save_path, time_interval)
import cv2
import os
import numpy as np
from PIL import Image
def frame2video(im_dir, video_dir, fps):
im_list = os.listdir(im_dir)
im_list.sort(key=lambda x: int(x.replace("frame", "").split('.')[0])) # 最好再看看图片顺序对不
img = Image.open(os.path.join(im_dir, im_list[0]))
img_size = img.size # 获得图片分辨率,im_dir文件夹下的图片分辨率需要一致
# fourcc = cv2.cv.CV_FOURCC('M','J','P','G') #opencv版本是2
fourcc = cv2.VideoWriter_fourcc(*'XVID') # opencv版本是3
videoWriter = cv2.VideoWriter(video_dir, fourcc, fps, img_size)
# count = 1
for i in im_list:
im_name = os.path.join(im_dir + i)
frame = cv2.imdecode(np.fromfile(im_name, dtype=np.uint8), -1)
videoWriter.write(frame)
# count+=1
# if (count == 200):
# print(im_name)
# break
videoWriter.release()
print('finish')
if __name__ == '__main__':
im_dir = 'D:/Walker/testv01/zhen/' # 帧存放路径
video_dir = 'D:/Walker/testv01/video/suc.avi' # 合成视频存放的路径
fps = 20 # 帧率,每秒钟帧数越多,所显示的动作就会越流畅
frame2video(im_dir, video_dir, fps)
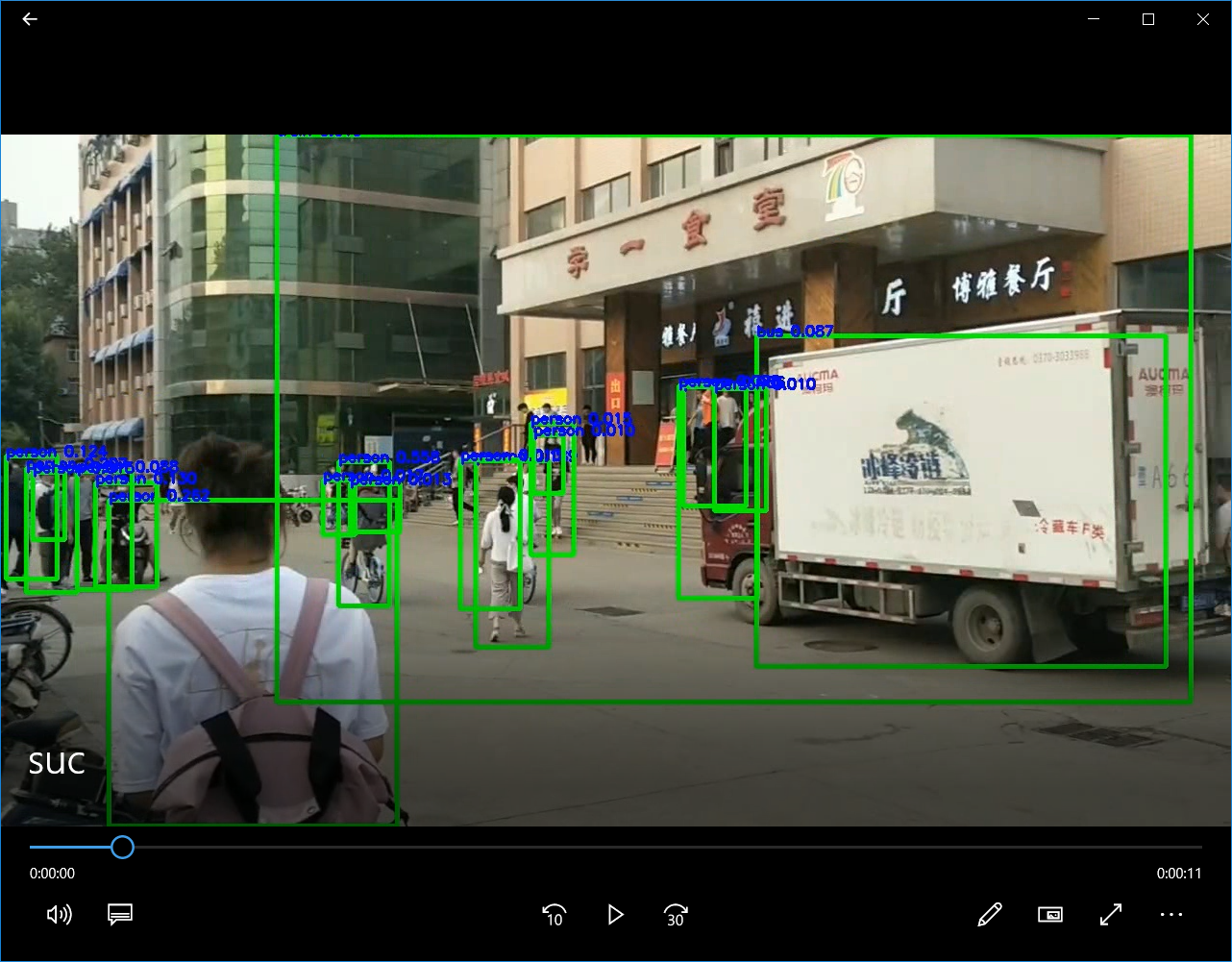
这样就能分割视频成指定的帧,然后进行每个帧中的行人以及其他物品的识别了。

最后再将每一帧的图片进行组合就成为视频了。