一 完善球赛程序,测试gameover函数的正确性
1.1 未修改之前的乒乓球的gameover函数的代码
def gameOver(scoreA, scoreB): g=scoreA-scoreB if (abs(g)==2 and scoreA> 10 and scoreB> 10) or (g> 0 and scoreA==11) or (g<0 and scoreB==11): return True else: return False a=input() b=input() print(gameover(a,b))
未修改过的上述代码输入多组数据经行测试,显然输出结果与正确结果有些出入
故对以上函数进行修改
1.2 修改后的gameover函数的代码如下:
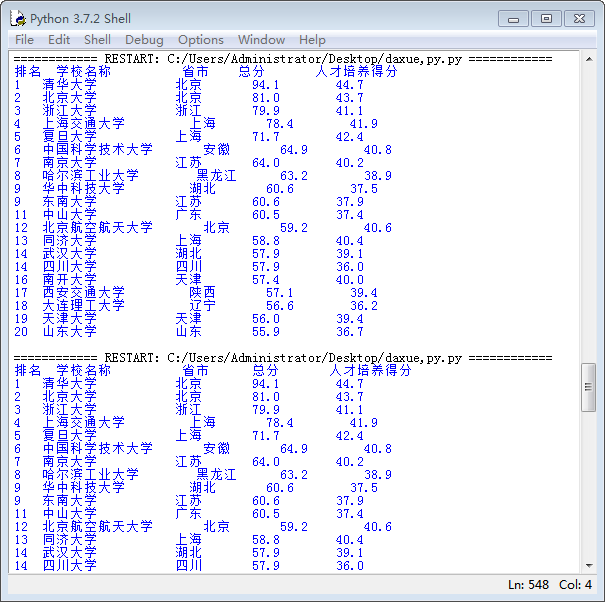
from math import* def gameover(scoreA,scoreB): g=scoreA-scoreB if (abs(g)==2 and scoreA>=10 and scoreB>=10) or (g>0 and scoreA==11 and scoreB!=10) or (g<0 and scoreB==11 and scoreA!=10): return True else: return False a=input() b=input() print(gameover(a,b))
多次输入测试数据结果如下(输出结果与预想一致结果):
二 用requests库的get函数()访问网站20次
2.1 访问百度网站的代码如下:
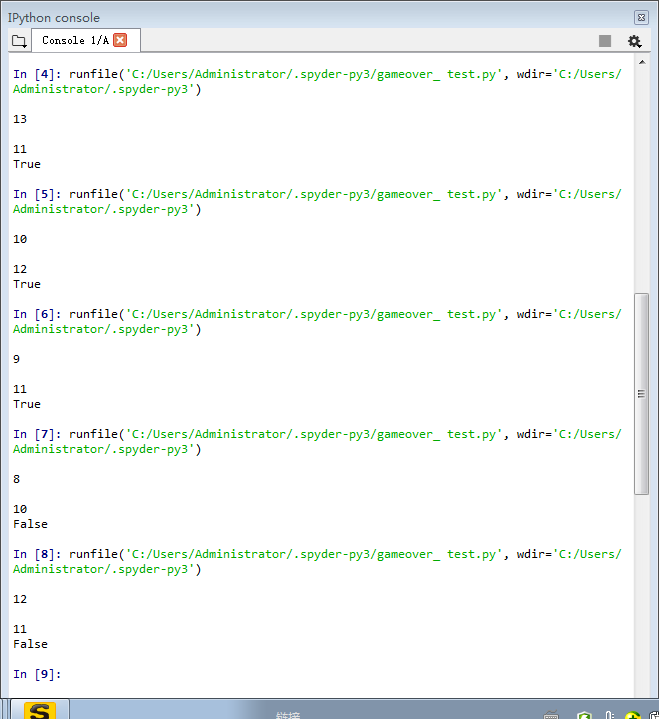
# -*- coding: utf-8 -*- """ Created on Mon May 20 22:19:31 2019 @author: 02豆芽运气 """ import requests from bs4 import BeautifulSoup def getHTMLText(url): try: r=requests.get(url,timeout=30) soup=BeautifulSoup(r.text) r.raise_for_status() r.encoding='utf_8' return (r.text,r.status_code,len(r.text),len(soup.p.contents)) except: return"" url='https://www.baidu.com' for i in range(20): #for循环调用函数访问网站20次 print(i) print(getHTMLText(url))
2.2 执行效果
三 对html页面进行一系列的操作
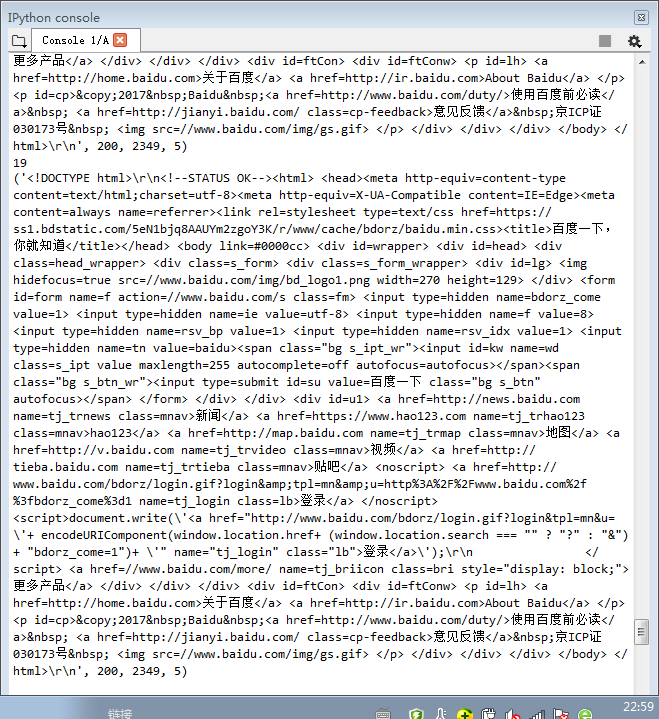
from bs4 import BeautifulSoup import re import requests soup=BeautifulSoup("<!DOCTYPE html><html><head><meta charset='utf-8'><title菜鸟教程(rounoob.com)</title></head><body><h1>我的第一标题</h1><p id='first'>我的第一个段落。</p></body><table border='1'><tr><td>row 1,cell 1</td><td>row 1,cell 2</td></tr><tr><td>row 2,cell 1</td><td>row 2,cell 2</td></tr</table></html>") print(soup.head,"02") #打印head标签的内容和我的学号后两位 print(soup.body) #打印body的内容 print(soup.find_all(id="first")) #打印id为first的文本 r=soup.text pattern = re.findall('[u4e00-u9fa5]+',r)#获取并打印hml页面中的中文字符 print(pattern)
效果:
四 爬取2015年中国大学排名
代码如下:
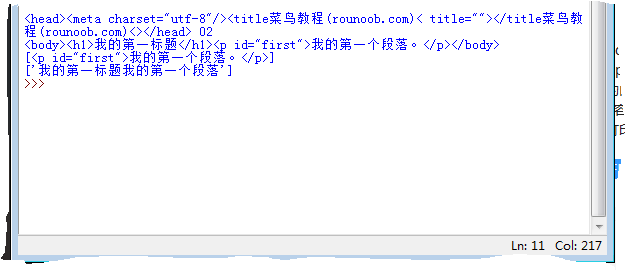
# -*- coding: utf-8 -*- """ Created on Mon May 27 21:30:19 2019 @author: Administrator """ from bs4 import BeautifulSoup import requests import pandas allUniv=[] def getHTMLText(url): try: r=requests.get(url,timeout=30) r.raise_for_status() r.encoding='utf-8' return r.text except: return "" def fillUnivList(soup): data=soup.find_all('tr') for tr in data: ltd=tr.find_all('td') if len(ltd)==0: continue singleUniv=[] for td in ltd: singleUniv.append(td.string) allUniv.append(singleUniv) def printUnivList(num): print("{:4}{:14}{:8}{:9}{:10}{:8}".format("排名","学校名称","省市","总分","人才培养得分",chr(12288))) for i in range(num): u=allUniv[i] print("{:4}{:<15}{:9}{:<12}{:<10}{:<8}".format(u[0],u[1],u[2],u[3],u[4],chr(12288))) def saveAsCsv(filename,allUniv): FormData = pandas.DataFrame(allUniv) FormData.columns = ["排名", "学校名称", "省市", "总分","人才培养得分" ] FormData.to_csv(filename, encoding='utf-8', index=False) if __name__ == "__main__": url = 'http://www.zuihaodaxue.com/zuihaodaxuepaiming2015_0.html' html = getHTMLText(url) soup = BeautifulSoup(html, features="html.parser") data = fillUnivList(soup) #print(data) printUnivList(20) # 输出前10行数据 def main(num): url='http://www.zuihaodaxue.com/zuihaodaxuepaiming2015_0.html' html=getHTMLText(url) soup=BeautifulSoup(html,"html.parser") fillUnivList(soup) printUnivList(num) main(20)
结果: