什么是索引下推?
- 索引下推(index condition pushdown )简称ICP,在Mysql5.6的版本上推出,用于优化查询。
- 在不使用ICP的情况下,在使用非主键索引(又叫普通索引或者二级索引)进行查询时,存储引擎通过索引检索到数据,然后返回给MySQL服务器,服务器然后判断数据是否符合条件 。
- 在使用ICP的情况下,如果存在某些被索引的列的判断条件时,MySQL服务器将这一部分判断条件传递给存储引擎,然后由存储引擎通过判断索引是否符合MySQL服务器传递的条件,只有当索引符合条件时才会将数据检索出来返回给MySQL服务器 。
- 索引条件下推优化可以减少存储引擎查询基础表的次数,也可以减少MySQL服务器从存储引擎接收数据的次数。
开撸
- 在开始之前先先准备一张用户表(user),其中主要几个字段有:id、name、age、address。建立联合索引(name,age)。
- 假设有一个需求,要求匹配姓名第一个为陈的所有用户,sql语句如下:
SELECT * from user where name like '陈%'
- 根据 "最佳左前缀" 的原则,这里使用了联合索引(name,age)进行了查询,性能要比全表扫描肯定要高。
- 问题来了,如果有其他的条件呢?假设又有一个需求,要求匹配姓名第一个字为陈,年龄为20岁的用户,此时的sql语句如下:
SELECT * from user where name like '陈%' and age=20
- 这条sql语句应该如何执行呢?下面对Mysql5.6之前版本和之后版本进行分析。
Mysql5.6之前的版本
- 5.6之前的版本是没有索引下推这个优化的,因此执行的过程如下图:

- 会忽略age这个字段,直接通过name进行查询,在(name,age)这课树上查找到了两个结果,id分别为2,1,然后拿着取到的id值一次次的回表查询,因此这个过程需要回表两次。
Mysql5.6及之后版本
- 5.6版本添加了索引下推这个优化,执行的过程如下图:
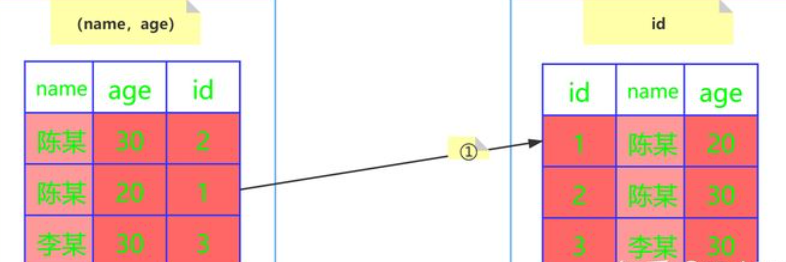
InnoDB并没有忽略age这个字段,而是在索引内部就判断了age是否等于20,对于不等于20的记录直接跳过,因此在(name,age)这棵索引树中只匹配到了一个记录,此时拿着这个id去主键索引树中回表查询全部数据,这个过程只需要回表一次。
实践
- 当然上述的分析只是原理上的,我们可以实战分析一下,因此陈某装了Mysql5.6版本的Mysql,解析了上述的语句,如下图:

- 根据explain解析结果可以看出Extra的值为Using index condition,表示已经使用了索引下推。
总结
- 索引下推在非主键索引上的优化,可以有效减少回表的次数,大大提升了查询的效率。
- 关闭索引下推可以使用如下命令,配置文件的修改不再讲述了,毕竟这么优秀的功能干嘛关闭呢:
set optimizer_switch='index_condition_pushdown=off';
什么是索引合并?
MySQL在 5.0版本中引入新特性:索引合并优化(Index merge optimization),当查询中单张表可以使用多个索引时,同时扫描多个索引并将扫描结果进行合并。
通俗解释就是: 一条SQL中使用两个或多个索引,查出来的数据集取交集或并集
该特新主要应用于以下三种场景:
1、 对OR语句求并集,如查询SELECT * FROM TB1 WHERE c1=“xxx” OR c2=""xxx"时,如果c1和c2列上分别有索引,可以按照c1和c2条件进行查询,再将查询结果合并(union)操作,得到最终结果
2、 对AND语句求交集,如查询SELECT * FROM TB1 WHERE c1=“xxx” AND c2=""xxx"时,如果c1和c2列上分别有索引,可以按照c1和c2条件进行查询,再将查询结果取交集(intersect)操作,得到最终结果
3、 对AND和OR组合语句求结果
注意事项:
select * from LHY where name = “lhy” and A > 100 or B > 100;
LHY表中包含索引 A 索引 B
不是使用合并索引就一定能够提高效率
当索引A 查出来数据为100W条, 索引B查出来的数据只有100条,当两个数据集取交集时,还是比价消耗IO的
遇到这种情况可以尝试优化SQL来实现(union)
select * from LHY where name = “lhy” and A > 100 union all select * from LHY where name = “lhy” and B > 100 and A <= 100;
第二条sql中要包含第一条sql中的反操作,避免数据重复。