机器学习性能评估指标
TP、TN、FP、FN
FN:False(假的) Negative(反例),模型判断样本为负例,但模型判断错了,事实上是正样本。(漏报率)
FP:False(假的) Positive(正例),模型判断样本为正例,但模型判断错了,事实上是负样本。(误报率)
TN:True(真的) Negative(负例),模型判断样本为负例,事实上也是负样本,模型的判断是对的。
TP:True(真的) Positive(正例),模型判断样本为正例,事实上也是正样本,模型判断是对的。
Precision
中文叫做精确率/查准率,表示模型认为的正例(TP+FP)中,真正判断正确的比例。
$$P=frac{TP}{TP+FP}$$
Recall
中文叫做召回率/查全率,表示样本真实的正例(TP+FN)中,真正判断正确的比例。
$$frac{TP}{TP+FN}$$
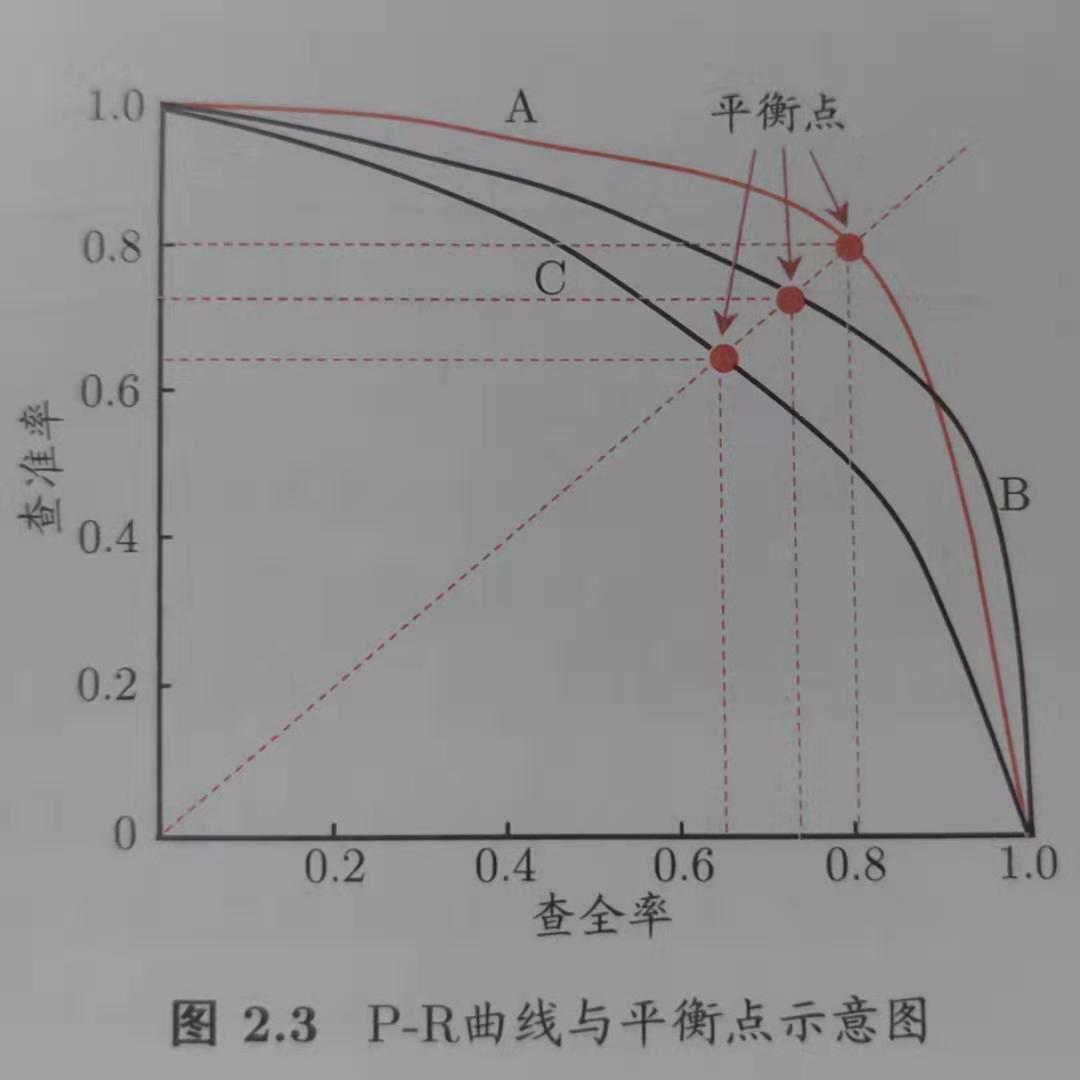
P-R曲线
以查准率为纵轴,以查全率为横轴画出来的曲线。
F-Measure
是精确率和召回率的调和平均
$$F=frac{(alpha^{2}+1)P*R}{alpha^{2}(P+R)}$$
当$alpha=1$时,记为F1指标:
$$F1=frac{2PR}{P+R}$$
ROC、AUC
另开一贴,见:https://www.cnblogs.com/4PrivetDrive/p/15164365.html
平方根误差 RMES
平方根误差也叫做RMSE。在实际情况中,如果出现一些偏离程度非常大的离群点时,RMSE就会变得非常差。
解决方法:
1)如果我们认定这些离群点是“噪声点”的话,就需要在数据预处理的阶段把这些噪声点过滤掉;
2)如果不让我这些离群点是“噪声点”,就需要进一步提高模型的预测能力,将离群点产生的机制建模进去;
3)找一个更合适的指标来评估该模型。关于评估指标,其实是存在比RMSE的鲁棒性更好的指标,比如平均绝对百分误差MAPE(mean absolute percent error),相比于RMSE,MAPE相当于把每个点的误差进行了归一化,降低了个别离群点带来的绝对误差的影响。
平均绝对误差 MAE
是绝对误差的平均值,可以更好的反映预测值误差的实际情况。
$$MAE(X,h)=frac{1}{m}sum_{i=1}^{m}|h(x_{i}) - y_{i}|$$
模型评估中的验证方法
(1)Holdout检验:
直接将原始的样本集合随机划分成训练集和验证集两部分。比方说,对于一个点击量预测模型,我们把样本按照70%~30%的比例分成两部分,70%的样本用于模型训练;30%的样本用于模型验证,包括绘制ROC曲线、计算精确率和召回率等指标来评估模型性能;
缺点:在验证集上计算出来的最后评估指标与原始分组有很大的关系
(2)交叉验证
K-fold交叉验证:首先将全部样本划分成k个大小相等的样本子集;一次遍历这k个子集,每次把当前子集作为验证集,其余所有子集作为训练集,进行模型的训练和评估;最后把k次评估指标的平均值作为最终的评估指标。在实验中,k经常取10.
留一验证:每次留下一个样本作为验证集,其余所有样本作为测试集。在样本总数较多的情况下,留一验证的时间开销极大.
留p验证:每次留下p个样本作为验证集,而从n个元素中选择p个元素有Cnp种可能,因此它的时间开销更是远远高于留一验证。
(3)自助法
基于自助采样法的校验方法。对于总数为n的样本集合,进行n次有放回的随机抽样,得到大小为n的训练集。n次抽样过程中,有的样本会被重复采样,有的样本没有被抽出过,将这些没有被抽出的样本作为验证集,进行规模验证。